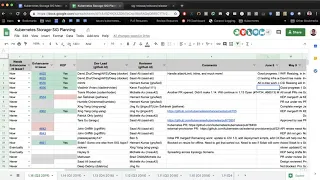
►
From YouTube: Kubernetes SIG Storage 20190606
Description
Kubernetes Storage Special-Interest-Group (SIG) Meeting - 06 June 2019
Meeting Notes/Agenda: https://docs.google.com/document/d/1-8KEG8AjAgKznS9NFm3qWqkGyCHmvU6HVl0sk5hwoAE/edit#heading=h.wmy92pkpnl3w
Find out more about the Storage SIG here: https://github.com/kubernetes/community/tree/master/sig-storage
Moderator: Saad Ali (Google)
Chat Log:
None
A
All
right
today
is
June
6
2019.
This
is
the
meeting
of
the
kubernetes
storage
special
interest
group.
So
today
on
the
agenda,
we're
gonna
go
through
1.15
items
that
we've
been
working
on
and
get
status,
updates
on
them
and
I
see.
There
are
a
couple
of
items
for
design
review
as
well
as
PRS
to
discuss
and
miscellaneous
items
so
we'll
get
to
those
after
planning
last
meeting
was
cancelled
due
to
Q
con.
A
We
had
a
strong
attendance
at
Q
con
with
lots
of
interest
in
storage,
so
that
went
well
if
you're
interested
those
videos
are
posted
on
YouTube
under
the
CNC
F
channel
feel
free
to
take
a
look
at
those.
So
let's
go
ahead
and
get
started
with
the
planning
and
important
dates
to
know
here.
Are
we've
already
passed
the
code
freeze
date,
so
that
means
the
major
functionality
that
we
wanted
to
get
in
had
to
get
in
by
May
30th.
We
are
now
officially
in
code.
A
Freeze
second
date
that
just
passed
us
was
the
docs
completion
date.
So
if
you
have
any
features
that
are
new,
the
docs
must
be
reviewed
and
completed
by
June
4th.
That
was
Tuesday.
If
that's
not
done,
you
need
to
get
that
done
as
soon
as
possible
and
then
the
next
date
is
June
17th,
which
is
when
kubernetes
115
should
be
released.
So
let's
go
ahead
and
do
a
update
here
to
see
what
features
made
it
into
this
release
and
what
features
did
not.
A
A
B
A
A
D
C
A
A
C
A
C
C
C
A
E
F
A
G
So
this
one
I
send
out
email
requesting
to
create
a
report
for
this,
and
then
you
reply.
It
sounds
good
to
me
so
I
open
the
room
request
in
kubernetes
our
arc,
but
they're
saying
that
we
need
us
am
I
wrong.
Siga
apps
Francie
gaps
to
approve
it,
otherwise
that
it
can't
be.
It
is
perfect.
You're
waiting
for
that
haven't
heard
anything
for
our
sea
crabs.
Okay,.
A
G
G
G
G
A
A
A
A
A
A
H
H
A
A
A
A
So
we'll
have
to
pick
that
up
next
quarter,
generic
data
populate
er,
I
didn't
see
any
updates
there
I
there
I
think
that'll
become
more
important
next
quarter.
It's
good
that
we
got
the
volume
cloning
stuff
in,
because
that's
one
piece
of
this,
but
the
generic
data
population
isn't
there
yet
moving
NFS
volume
to
separate
repo.
C
D
A
F
I
A
A
F
A
G
A
G
A
C
A
G
D
A
So
we'll
mark
that
is
incomplete
and
moves
that
to
next
quarter.
Csi
spec
alpha
beta
GA
designation.
This
work
got
started.
I
did
not
get
a
chance
to
look
at
it
in
the
last
four
weeks.
So
I
don't
know
what
the
latest
on
it
is.
I
know
we
had
agreed
on
what
the
designation
would
look
like,
but
I
don't
know
if
we
actually
implemented
anything
there.
So
I'll
call
this
started
and
I
have
better
information.
This.
A
Is
just
for
how
are
you
gonna
handle
alpha-beta
GA
designations
for
new
features
to
the
spec
got
it
so
there
was
a
consensus
on
how
we're
gonna.
Do
it
I'm,
not
sure
if
we
actually
updated
anything
to
say
this
is
officially
how
we're
gonna
do
it
and
then
finally
support
containerized,
CSI
node
plugins
in
Windows,
with
a
storage
proxy
executable?
A
B
B
16.1
interesting
development
with
respect
to
this
is
also
that
in
cig
windows,
there's
been
some
movement
around
seeing
if
we
can
do
privileged
containers
directly
with
support
that
directly
in
Windows,
so
so
yeah.
We
will
continue
this
investigation,
but
depending
on
how
that
process
goes,
we
might
have
to
course-correct
a
bit
nice.
A
A
That's
awesome,
I
would
make
it
natively
equal,
so,
okay,
thank
you
all
for
the
status
updates
and
thanks
for
all
the
hard
work
here,
I
think
we
still
got
a
considerable
amount
done
this
quarter.
A
lot
of
what
we
were
doing
was
probably
not
going
to
be
finished
in
a
single
quarter.
So
that's
why
we
have
a
lot
of
4-inch
here
and
we'll
pick
up
those
items
for
next
quarter
and
finish
off.
A
I'm
gonna
create
a
new
tab
here
for
1.16
feel
free
to
start
adding
items
there
as
soon
as
I
do
I'll
send
out
an
email
and
then,
in
our
next
meeting
in
two
weeks,
we'll
discuss
our
1.16
items
and
what
we're
going
to
commit
to
alright
moving
on
from
planning.
Let's
move
on
to
PRS
that
need
attention.
We
have
this.
One
here
failed
to
unmount
NFS
when
connection
was
lost,
who
added
this
and
who
wants
to
talk
about
it.
I.
I
Think
I
added
this
because
it's
issue
alike.
Meanwhile,
we
we
kind
of
I,
think
discuss
this
before
but
want
to
get
a
concerns
like
what
we
should
do
is
really
it's
very
simple
rights.
We
have
answered
and
the
client
and
they
will
serve
it,
sorry
is
done
and
when
we
killer
down
the
pod
right,
we
fail
to
a
month
because
the
a
month
we
were
just
hanging
there
and
there
is
a
PR.
Maybe
we
you
can
move
down
a
little
bit.
We
can
see
the
PR
this
one
I,
think
so
and
they
the
solution.
I
There
is
to
add
a
force
option
during
a
month
and
I
think
we
have
question
about
whether
this
force
option
should
be
used
for
all
and
months.
Oh
and
the
weather
is
necessary
because
force
means,
even
if
you
unmount,
and
sometimes
you
get
arrow
like
device-
is
busy
because
some
process
is
using
it
and
the
force
we
were
just
like
for
a
month,
no
matter
what
processes
using
it,
whether
we
might
cause
some
data
corruption
problem
so
normally
will
before
we
our
mount.
I
H
I
say
with
NFS
hard
mounts:
I've
seen
situations
where
even
a
even
on
mount
a
chef
will
not
going
on
like
get
it.
You
unmounted
and
you
can
really
get
wedged
the
option
to
do
a
force.
Unmount
with
NFS
is
a
step
forward,
but
I
bet
you
that
there
will
still
be
weird
scenarios
where
that's
not
enough.
Yeah.
F
H
I
I
We
no
longer
have
the
hanging
amount
problem
issue,
that's
been,
I,
guess
and
or
user
has
to
manually,
go
inside
and
unmount
it.
Otherwise
your
party
is
stuck
there
and
second
option
like
here
force,
but
yes,
it
cannot
solve
all
the
problems
seems,
but
it's
not
sure
how
was
the
presentation
like
force
amongst
can
help.
C
H
And
is
that's
why
what
I
was
going
to
suggest
is?
Is
there
a
way
we
could
allow
the
pod
to
be
deleted
and
make
the
garbage
get
cleaned
up
later,
so
at
least
we
can
say
yeah
the
pot
is
shut
down.
There's
nothing
running.
We
can't
perform
the
unmount
because
I
met
the
mount
is
stuck
waiting
on
the
NFS
server,
but
we
can
at
least
call
the
pod
Lee
didn't
have
some
garbage
collection
for
the
mount
later.
Is
that
but.
H
C
H
E
E
A
H
I
C
H
C
C
I
C
H
A
H
People
always
have
that
recourse.
If
their
server
really
is
unreachable
and
then
a
key
can
just
bounce
the
whole
node.
And
then,
when
it
comes
back
up,
it'll
have
no
mounts
and
people
will
start
up
and
start
cleaning
up
any
garbage
in
the
file
system
and
you'll,
then
should
get
back
into
a
good
state.
I
I
C
J
This
is
Christian
I
wanted
to
follow
up
on
one
comment
that
was
just
made
from
the
thread
pool
perspective,
so
a
single
volume
getting
stuck
in
unmount
seems
fine.
What
if
I
have
tons
of
pods
mounting?
You
know
dozens
of
different
volumes
and
and
half
my
pods
mount
NFS
server,
that's
healthy
and
the
other
half
one.
That's
not
healthy.
Could
the
unhealthy
ones
collectively
over
exhaust
the
threat
poll
and
hence
lead
to
a
node
in
a
stuck
state
where
it's
it's
half
life
and
half
dead?
Yes,.
C
H
C
I
H
C
A
A
Well,
the
problem
is
that
you
don't
necessarily
know
when
you
want
to
do
it
until
you
get
into
this
case,
and
it's
not
something
that
you
want
to
say:
hey
every
time,
I
have
a
mount,
always
do
a
force
on
mount.
You
want
to
use
it
as
an
exceptional
case
when
you
get
into
one
of
these
conditions,
but.
H
A
A
I
agree,
the
adding
it
to
a
CSI
driver
makes
sense,
don't
add
it
to
the
core
for
everything
and
then
for
the
CSI
driver
make
it
is
make
it
a
last
resort
option
that
you
have
to
opt
into
that
seems
reasonable,
but
before
you
do
all
of
that
work
do
under
like
do
the
homework
to
understand.
Does
this
actually
how
open
and
you
know
what
percentage
of
cases
does
it
help?
Does
it
help
the
use
cases
that
you're
looking
into.
G
G
Basically,
this
is
just
to
check
if
a
PV
is
healthy,
whether
it
still
exists,
whether
it's
still
monk
it
whether
it's
still
attached
what
is
whether
it
is
still
usable
and
they've,
not
we're
using
taint
to
market
that
there
are
some
issues
with
it,
so
that
so
at
a
high
level,
that's
what
this
one
is
and
I
will
work
with,
is
Nick
chill
out
of
the
CSI
design
to
this
cap.
So.
C
C
G
C
A
I
C
A
C
A
E
So
there's
an
effort
and
open
source
to
move
all
the
core
components:
the
disrelish
so
as
a
side
effect.
Dependencies
like
shell
are
gonna,
be
missing
from
these
containers.
I
know
a
lot
of
flex.
Walling
tests,
b2b
tests
actually
use
shell
scripts
to
enervate,
implement
the
Flex
following
interface
and
it's
in
the
examples
to,
and
possibly
some
some
of,
our
users
flex
following
also
implemented
a
shell.
E
C
E
C
But
I
guess
the
main
thing
is
that
if
we
just
add,
if
we
add
one
more
intermediate
layer,
then
what
that
lets
distributions
do
is
most
distributions
by
default
will
use
the
destroy
this
for
controller
manager
and
they
won't.
You
know
potentially
not
support
flexible,
you
master
stuff
a,
but
it
still
gives
the
ability
for
people
that
still
need
it
to
use
it
with
that
risk.
Yeah.
F
The
one
problem
has
been
that,
like
a
lot
of
flex
volume,
even
if
there's
a
shell,
they
may
have
dependency
other
dependency
on
the
host.
Actually,
so
Michelle
is
not
the
definite
the
only
thing
a
flex
script
needs
sometimes,
so
it
has
always
been
problematic
to
run
flex
for
domain
controller
measure
is
containerized,
so
I
mean
if,
in
my
opinion,
might
be
best
to
actually
slowly
deprecated
it
because
it's
not
it
never
works
properly
and
at
least
in
openshift
in
our
we
are
slowly
trying
to
slightly
slowly
move
away
from
it.
So
I
thought.