►
From YouTube: Say What?: 2014 Spring NuPIC Hackathon Demo
Description
Matt Roos, Will Gray Roncal, Dean Kleissas
A
Okay,
hey
guys
so
my
name's
will.
This
is
matt
and
dean
and
we're
gonna
kind
of
just
walk
you
through
our
demo.
What
we
did
real
quick,
I
know
we're
demo
like
17
or
something
and
it's
it's
6
30.
So
we'll
just
kind
of
give
you
the
highlights
here.
But
what
we
wanted
to
do
is
to
look
at
speech
data.
So
we
took
some
of
the
timid
corpus
and
we
we
tried
a
bunch
of
different
experiments.
So
we
looked
at
a
single
channel
version
using
pitch
to
predict
male
versus
female
turns
out.
A
We
could
do
that
and
then
we
looked
at
some
things
that
were
harder
with
multi-channel
versions.
Looking
at
things
like
speaker,
id
and
sentence
recognition,
tasks,
and
one
of
the
things
that
we
were
interested
in
was
exploring
kind
of
different
representations
of
the
of
the
audio
signal.
So
looking
you
know
trying
to
go
from
a
raw
way
form
to
look
at
hit
pitch
or
the
capture
coefficients
or
some
audio
spectrogram
kind
of
information,
and
so
for
those
of
you
who,
who
don't
know
temit.
A
A
A
A
So
these
were
these
were
sentences
so
each
oh,
I'm
sorry
right!
Yes,
so
the
input
was
pitch
pitch
values
that
were
derived
from
one
of
these
one
of
these
sentences
and
sampled.
How
often
so
this
was
sampled.
Would
we
wind
up
using
10,
millisecond,
yeah,
10,
millisecond
windows?
Okay,
just
just
pitch
values,
that's
it
yeah,
and
so
I'm
going
to
let
team
do
the
next
slide.
D
Yeah-
and
so
we
did
that
because
we
framed
this,
you
know
we've
never
used
new
pick
before
since
we
came
today
and
so
the
first
thing
we
figured
was:
let's
keep
it.
You
know
single
one
input
kind
of
like
what
the
example
is,
and
so
we
start
with
the
pitch,
and
then
we
try
to
get
more
complicated
and
add
multiple
channels
essentially
to
the
data,
and
this
was
an
example
where
we
did
speaker
id.
D
So
in
this
case
the
first
block
of
the
we
train,
the
cla
up
with
just
one
speaker,
a
bunch
of
different
utterances
like
over.
You
know
random
things.
The
person
was
saying
one
male
and
then
we
tested
with
a
chunk
of
that
speaker
again
saying
something
and
a
bunch
of
other
random
males,
saying
different
things
and
again,
using
this
framework
of
just
trying
to
treat
it
as
an
anomaly
detection
problem,
not
really
actually
doing
prediction,
and
then
you
can
see
that
you
know
it's
still
very.
B
D
D
Just
threw
in
13.
wow
used
some
guesses
on
parameters,
and
you
know
tuned
basically
for
all
of
our
multi-channel
stuff.
I
just
set
the
only
thing
for
the
encoders
was
setting
the
range
properly
based
on
the
data
and
then
kind
of
guessing
and
trying
a
couple
different.
You
know:
bin
sizes
and
bit
sizes
and
whatnot.
A
D
D
D
G
G
It
got
confused
that
it
start
and
wasn't
sure
and
then
gotcha.
It
was
sure
by
the
time
you
got
to
the
there's
two
ways
of
getting
that
kind
of
a
graph,
and
one
of
them
is
at
the
beginning.
It's
unsure
and
it
gets
it's
get.
Goods
are
painter,
but
if
you
put
the
correct
speaker
at
the
end,
then
that
would
eliminate
that
as
possible.
H
E
D
I
F
F
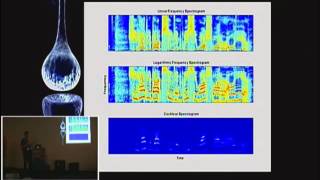
So
we
took
that
cochlear
spectrogram
representation
and
we
wanted
to
try
what
I'm
going
to
call
sentence
spotting,
which
is,
as
was
already
stated,
some
of
these
sentences
are
two
of
the
sentences
are
repeated
by
every
speaker.
So
we
have
a
good
chunk
of
data
to
work
with
and
the
idea
was
to
train
the
cla
on
just
that
sentence
and
then
again
turn
off
the
learning
and
does
it
consider
pretty
much
any
other
sentence
to
be
a
an
anomaly
and
what
I'm
showing
in
these?
These
two
figures.
F
Let
me
show
you
a
movie
here,
so
there's
one
on
the
left.
This
is
so.
This
is
the
regular
cochlear
spectrogram,
but
there's
really
too
much
data
here,
and
so
I
did
a
high
pass
filter
of
the
across
the
frequency
axis.
Sorry,
the
resolution
here
is
really
poor
and
then
another
and
a
decimation,
and
likewise
across
the
time
domain
and
now
I'm
going
to
hit
this
play
and
it's
going
to
show
you
what
these
spectrograms
look
like
for.
F
So,
of
course,
you
see
sort
of
jitters
in
time
and
things
like
that
and
unfortunately,
or
presumably
any
failure
you
might
be
attributed
to
that.
But
but
if
we
compare
that
to
this,
in
which
case
this
is
our
test
corpus,
which
contains
some
of
the
training
sentences
by
others
spoken
by
other
speakers
as
well
as
just
many
other
different
sentences,
all
together.
F
B
F
B
F
D
The
big
thing
is,
we
didn't
swarm
properly,
so
we
probably
had
lots
of
problems
there
and
also
I
don't
know
if
we're
really
capturing
you,
you
could
see
in
that
last
video.
You
know
people
talk
at
different
speeds
with
different
pauses,
and
it
really
gives
you
this
time.
You
know.
There's
I
don't
know
if
we
really
were
able
to
capture
that
time
and
variance.
D
E
F
B
F
So
I
don't
really
need
to
read
these
off.
You
know
we're
new
to
new
pick,
but
it
was
very
educational.
Clearly
we
saw
that
swarming
and
really
learning
your
parameter.
Space
is
really
important
and
that
video
may
not
have
gotten
it
across.
But
if
you
look
at
that
on
you
know,
my
screen
run
regularly.
You'll
see
that
there's
very
those
are
very
consistent
senses.