►
Description
Bruno Olshausen, Redwood Center for Theoretical Neuroscience.
Presented at the IS4SI 2019 Summit in Berkeley, California. https://is4si.org
A
So
I'm
gonna
try
to
give
you
a
perspective
from
computational
neuroscience,
where
we're
trying
to
build
computational
mathematical
models
of
how
brains,
process
information
and
what
I
think
this
can
bring
into
AI
and
sort
of
getting
the
eye
actually
into
artificial
intelligence.
The
intelligence
part.
So
the
should
begin
by
introducing
the
group
which
I
work
with
here
on
campus,
the
Redwood
centre
for
theoretical
neuroscience.
A
A
And-
and
the
second
is-
and
probably
this
is
the
most
important
of
all-
is
sort
of
aiming
aiming
your
gun
correctly
or
aiming
your.
You
know
your
problem,
solving
skills
directly
in
the
in
the
right
way,
and
you
know
I
sort
of
argue
a
lot
of
the
problems
that
people
are
solving
right
now
are
kind
of
not
really
the
right
problems
to
be
to
be
true,
solving
at
the
right
metrics
to
try
to
be
satisfying,
and
so
so,
how
do
we?
How
do
we
sort
of
sort
of
point
our
efforts
in
the
right
direction?
A
Better
and
and
then
finally,
you
would
pointed
to
the
looking
looking
at
mathematics
for
some
some
new
directions
there,
and
my
own
view
is
that
the
the
kind
of
math
that
we
need
to
understand
how
brains
work
we
don't
have
yet.
So
if
you
go
to
mathematics
departments
across
the
country,
you
know
I
I,
think
they
just
don't
know,
and
so
we
shouldn't
are
sort
of
accept.
The
math,
as
is,
is
like
the
stopping
point.
A
How
did
we
get
to
this
point,
and
this
is
just
a
depiction
of
the
perceptron
model
which
was
due
to
Frank
Rosenblatt
in
1959,
and
this
was
the
1950s
1960s
model
of
how
neurons
works,
a
work
work,
which
is
basically
that
a
neuron
is
a
summing
Junction.
It
takes
a
bunch
of
signals
and
combines
them
with
different
weights.
So
this
is
the
inputs
here.
Each
is
weighted
by
a
different
amount,
and
then
you
just
take
a
weighted
sum
of
these
inputs
and
pass
it
through
a
threshold.
A
Instead
out
is
either
a
0
1,
which
was
loosely
meant
to
correspond
to
either
you
know
spike
or
no
spike,
and
so
you
know
the
basically
the
conceptualize
down
here
and
so
Rosenblatt
showed
how
you
can
devote
how
you
can
train
this
system
by
example,
to
adjust
these
weights
to
perform
some
function.
That
was
called
the
perceptron
learning
rule
that
got
people
really
excited
in
the
1960s
that
you
could
do
that.
You
could
do
things
like
this
and
got
people
working
to
build
multi-layer,
perceptrons.
A
So
there's
a
lot
of
experimentation
going
on
in
1960s
with
multi-layer
perceptrons,
but
they
didn't
have
a
learning
rule
for
them,
because,
although
they
had
they
had
learning
rules
based
on
gradient
descent
due
to
Bernie,
Woodrow
and
others
at
the
time
they
knew
about
gradient
descent
and
stuff,
but
they
were
stuck
with
this
phone
here,
because
if
you
built
a
multi-layer
network
out
of
this
out
of
these
nonlinearities,
well
they're,
not
differentiable,
and
so
this
is
kind
of
one.
What
retrospective
way
of
looking
at
it?
A
It
took
people
like
20
years
to
realize
that
you
can
kind
of
sidestep
that
issue
by
making
a
smooth
nonlinear
function
and
then
it's
differentiable
and
it's
kind
of
remarkable.
Ideally,
you
know
I'd
like
to
really
emphasize
this
to
my
students,
because
there
was
nothing
kind
of
there's,
no
big,
roadblock
or
showstopper.
That
was
preventing
people
in
1965
from
doing
something
like
this
Arthur
Bryson
was
doing
gradient
descent
with
multi-layer
neural
networks.
They
were
doing
it
with
linear
neural
networks,
mainly,
and
so
they
were
really
just
kind
of
one
step
away.
A
A
Differentiable
now
allow
people
to
stack
these
neurons
in
multiple
layers,
and
that
was
a
huge
advance
that
came
in
the
mid
1980s
as
a
result
and
that
produced
a
whole
nother
wave
of
excitement
and
and
then
we
have
the
deep
learning
sort
of
revolution
that's
occurring
today,
which
utilizes
these
so-called
real
ooh
nonlinearities,
where
instead
of
johar
sort
of
saturating
at
the
top
people
kind
of
noticed.
Well,
you
know
why
clip
the
output
like
that
you're
just
kind
of
losing
information.
A
These
neurons
and
layers,
which
and
the
so
called
convolutional
model
cava,
and
this
is
really
due
to
Fukushima,
who
developed
this
model
in
the
nineteen
in
1980,
and
he
based
this
idea
really
based
on
Hugh
Poe
and
weasels
hierarchical
models.
So
he
was
very
inspired
things
happening
in
neuroscience,
but
again
they
said
this
is
a
model
at
Hubel
and
Wiesel
described
in
1965.
A
Their
hierarchical
model
of
feature
extraction,
beginning
with
simple
features
in
the
retina
orientation,
detectors,
sort
of
linear
orientation
filters
in
in
V,
1,
followed
by
complex
cells,
that
kind
of
pooled,
or
averaged
over
position
to
build
some
in
position
invariance
and
then
so
called
hyper
complex
cells,
which
would
respond
to
more
complex
shapes.
So
they
had
this
model.
They
proposed
in
the
mid
60s
based
on
a
hierarchy
and
feature
extraction.
Fukushima
is
reading
this
work
and
he
said
well,
you
know
gosh.
That
sounds
really
interesting.
What
can
I
do
with
that?
A
Let's
meet
I'll,
build
a
computational
model
and
see
if
I
can
train
it
to
to
to
do
some
simple
object,
recognition
tasks,
and
that
was
this
model
called
the
Neo
carga
Tron
and
he
trained
it
beeped
with
heavy
and
learning.
So
it's
just
simply
an
unsupervised
network
trained.
Without
a
teacher.
He
printed
a
bunch
of
images
of
handwritten
digits
here
and
then
it
has
these
feature.
A
So
it
all
really
kind
of
stems
from
this
work,
there's
very
little
different
as
they're,
just
simply
using
back
prop
instead
of
unsupervised
learning.
But
it's
the
same
basic
idea
and
Fukushima
was
very
humble
man.
He
doesn't
have
a
cool
Twitter
feed
to
promote
all
his
work
and
stuff
like
that.
So
a
lot
of
people
don't
really
acknowledge
him.
I
think
as
much
as
he
deserves,
but
he's
really
kind
of.
A
Okay,
so
nevertheless,
though
you
know,
I
think
the
thing
to
notice
here
is
that
all
these
models
were
working
today,
we're
working
with
today,
they're
based
on
conceptualizations
of
neurons
that
were
made
in
the
1960s
okay,
the
basic
idea
of
thinking
of
a
neuron
is
as
linear,
summing
Junction,
followed
by
a
threshold
and
stacking
neurons
and
layers
like
this,
basically
inspired
by
Hugo
and
weasels
model,
okay
and
and
so
our
art.
So
but
in
the
meantime,
neuroscience
is
really
advanced
remarkably
over
the
past
50
years
and
and
our
models
have
not
really
caught
up.
A
So
I
want
to
give
you
just
a
few
examples
of
this,
so
one
is
just
think
about
what
a
single
neuron
is
doing,
and
so
so
this
is
just
a
picture
of
one
to
one
specific
type
of
neuron.
The
brain
is
so
called
pyramidal
cell,
showing
all
those
dendritic
processes.
This
is
where
all
the
inputs
come
into
into
into
the
cell,
and
it
does
some
computation
with
that
and
if
there's
anything,
we
know
now
from
modern
neuroscience
that
a
neuron
is
not
doing
it's
not
doing
this.
A
In
other
words,
it's
not
doing
what
a
perceptron
computation
says.
It's
just
a
weighted
sum
passing
it
through
it
through
it
through
a
single
single,
it's
with
single
threshold
in
collection
of
the
soma,
but
but
rather,
what
happens
in
real
neurons?
Is
that
there's
all
kinds
of
nonlinearities
in
the
dendritic
tree,
so
it
with
an
image,
dendritic
branch
here,
there's
many
different
compartments.
You
could
divide
it
into
and
the
inputs
coming
in
to
any
one
branch
locally
within
within
the
dendritic
tree
combined
nonlinearly.
A
A
Early
1990s
is
the
so
called
Sigma
Pi
model
and
it's
called
Sigma
Pi,
because
a
sum
of
products,
so
you
think
of
like
each
compartment
on
the
generated
tree,
is
taking
a
local
product
of
inputs
and
then
and
then
the
neuron
is
taking
a
weighted
sum
of
all
these
different
products
happening
on
the
dendritic
tree.
So
this
would
be
maybe
perhaps
make
a
better
model
than
they're
on,
but
still
I
think
way
off
in
terms
of
capturing
the
actual
computational
complexity.
A
These
these
neurons
are
sensitive
to
coincidences
among
spikes,
so
in
other
words,
if
spikes
arrive
at
the
same
time
within
a
millisecond
or
each
other.
So
then
that's
going
to
have
a
better,
more
more
efficacy
than
neurons
that
are
right
out
of
synchrony,
and
things
like
that.
So
there's
there's
a
whole
complex
cascade
of
things
happening.
A
A
neuron
is
an
extremely
complex
device
and
actually
modeling
how
come
it
is
something
we
still
don't
know,
and
so
so
one
thing
I
think
to
understand
here
is,
though
that
is
rather
than
trying
to
simplify
the
neuron
into
a
simple
perceptron.
We
should
embrace
this
complexity.
There's
a
lot
more.
You
can
do
this
is
a
much
richer
computation.
There's
a
lot
more.
We
could
do
with
these
types
of
neurons
than
the
simple
neurons
we
use
in
our
model
today.
A
A
So
it's
not
just
all
one
big
kind
of
mess,
but
that
for
each
neuron
the
dark
part
indicates
the
dendrites
and
the
light
part
indicates
the
axon.
So
these
are
all
the
axons
of
one
neuron.
These
are
all
the
dendrites
of
one
neuron.
We
have
reaching
up
here
the
superficial
layers,
and
this
is
for
just
another
neuron.
The
dark
part
of
the
dendrites
in
the
light
part,
is
the
axons
okay.
A
So
there
Rama,
fiying
and
sort
of
branching
and
very
complex
ways
within
the
neural
tissue
connecting
connecting
different
layers
of
computation
with
it
within
the
cortex
and
understanding
what
these
different
layers
are
doing
is
really
one
of
the
goals
of
modern
neuroscience
still,
but
one
thing
we
do
know
in
terms
of
way
of
characterizing.
It
is
this
layer
for
this
layer,
for
here
is
important
because
it's
the
input
layer
of
the
cortex,
so
the
inputs
from
the
thalamus
come
in
to
layer
four
and
then
they
in
turn
project
on
to
layer.
A
Two
three
here
mainly
that's
the
main
target
is
layer,
two
three
and
then
within
layer.
Two
three
there's
a
vast
array
of
horizontal
connections:
they're
not
really
shown
here
but
neurons
that
spread
the
information
laterally
across
the
cortex,
so
there's
a
vast
mixing
of
information
as
a
highly
recurrent
circuit.
Okay.
So
it's
not
like
these
in
neurons
are
kind
of
keeping
information,
private
and
just
sort
of
taking
the
information
from
below
their
vast
mixing
of
information.
These
nonlinear,
with
these
nominee
or
computations,
going
on
here
and
layer,
two
three.
A
They
in
turn
project
down
to
layer,
five,
which
in
turn
has
a
whole
slew
of
horizontal
connections
here
and
layer,
five
Dom
projects
to
motor
structures
and
layer,
six
projects
back
down
to
the
to
the
thalamus
okay.
So
the
the
thing
to
convey
here
is
that
there's
a
there's
just
a
huge
amount
of
structure
here
in
these
cortical
circuits
computational
structure.
So
it's
undoubtedly
a
different
computational
role
for
these
neurons
in
layer.
Four,
as
opposed
to
these
neurons
neurons
in
layer.
A
Two
three,
as
opposed
to
neurons
down
here,
they're,
probably
doing
very
different
computations
that
support
perception
that
support
cognition.
What
exactly
those
are?
We
don't
know,
but
this
is
something
that
I
think
the
computational
community
could
really
help
in.
Is
you
know,
rather
than
sort
of
treating
this
as
a
single
slab
of
a
neural
network?
Let's
try
to
embrace
that
and
really
understand
and
exploit
it
in
in
in
the
in
these
models,
especially
these
horizontal.
These.
These
are
current
connections
where
information
is
intermixed
and
try
to
understand.
Why
is
that
useful?
A
Why
is
that
a
good
thing
for
the
system
to
do
another
aspect-
and
this
is
kind
of
one
of
the
aspects
of
the
architecture
that
inspired
deep
learning
Fukushima's
model
is
the
is
the
fact
that
these
cortical
areas
are
appear
to
be
kind
of
stacked
in
a
hierarchy,
and
this
is
being
shown
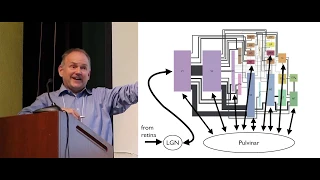
Illustrated
here.
This
is
a
redrawing
of
the
famous
Venice
and
fellowman
diagram
that
charts
out
the
connections
of
all
the
different
areas
within
the
visual
cortex.
So
each
box
here
corresponds
to
a
different,
distinct
visual
area
within
the
visual
cortex
area.
A
V1
is
the
primary
visual
cortex
area.
V2
is
the
second
second
visual
area
and
so
forth.
Area
v4
is
another
area
involved
in
object
or
form
processing,
and
these
areas
here
are
largely
involved
in
object,
recognition,
okay,
so
the
one
interesting
sort
of
trend,
as
you
proceed
from
left
to
right
in
this
diagram,
is
that
you
tend
to
go
from
very
low
level
image
related
features,
so
these
neurons
and
v1
are
basically
coding
properties
of
the
image,
irrespective
of
what
they
mean
in
the
world.
A
This
is
how
we
think
about
it,
and
these
neurons
on
the
right,
especially
in
these
boxes,
there
are
encoding
properties
of
the
world
and
not
so
much
tied
to
image
property,
so
they're
coding
things
about
objects.
These
are
coding
information
about
relative
spacial
relationships
in
the
world
that
are
useful
for
navigation
and
reaching,
and
things
like
that.
A
Okay,
so
so,
I
think
what
the
deep
learning
community
is
kind
of
taken
from
this
is
kind
of
okay.
Well,
there's
a
hierarchy
here
and
let's
stack
our
layers
and
well
we'll
we'll
sort
of
get
something
interesting
at
the
top
here.
So
they're
trying
to
sort
of
capture
aspects
like
that,
but
one
thing
to
bear
in
mind
here
is
this-
is
a
very
quartic
eccentric.
This
is
a
very
quartic
eccentric
point
of
view.
A
One
is
the
LGM
which
provides
input
to
v1
from
relays
information
from
the
retina
and
the
other
is
the
pulvinar
nucleus
of
the
thalamus,
which
relieves
receives
projections
from
all
these
different
cortical
areas
and
in
a
sense
kind
of
recapitulates,
the
cortical
hierarchy,
so
in
the
same
way
that
those
different
areas
up
here
in
the
cortex
there's
different
areas
down
here
in
the
pulvinar
nucleus
of
the
thalamus.
So
all
these
cortical
areas,
projecting
information
down
to
the
pulvinar
in
the
thalamus
and
the
pulvinar
and
thalamus,
is
in
turn
projecting
back
up
to
them.
A
What
in
the
world
is
doing,
nobody
has
any
idea.
Okay,
IV
the
field
would
be
it,
but
some
people
will
tell
you
that
it's
doing
this
involves
an
attention
and
it
is
definitely
if
you
lesion
the
pulvinar,
you
get
different
deficits
and
attention
and
there
seems
to
be
some
kind
of
indicator.
You
know
evidence
for
that,
but
there's
really
kind
of
almost
zero
computational
theory
of
what
this
kind
of
system
is
doing
and
how
it
works.
A
The
closest
actually
is
the
theory
of
Maurice
Sherman
and
Ray
Guillory,
and
they
think
that
this
is
basically
a
hierarchy
of
nested
sensory
motor
loops.
It's
what's
interesting
about
their
theory.
Is
that
what
they
point
out
is
all
these
different
cortical
areas.
This
is
not
just
kind
of
like
a
perceptual
apparatus.
Here,
all
these
different
cortical
areas,
the
layer
five
neurons,
have
layer,
five
neurons,
which
project
two
motor
structures.
A
So,
for
example,
v1
has
layer
five
neurons,
which
projected
the
superior
colliculus,
which
in
turn
drives
eye
movements
layer,
two,
the
two
also
projects
in
the
superior
colliculus
right
and
many
other
areas.
But
these
projects
are,
maybe
you
know,
had
head
sort
of
head
movement
areas
or
reaching
reaching
movements,
and
things
like
that.
A
I'm,
sorry,
okay
friend,
so
I
feels
yeah,
so
yeah
I
guess
that's
on
here,
but
okay,
and
so
that
that's
point
is
that
all
these
areas
have
outputs,
and
so
this
is
one
big
disconnect
between
the
sort
of
fundamental
neuroanatomy
and
organization
of
the
system
and
the
way
that
we
currently
conceptualize
these
deep
learning
and
that
networks
is
that
this
is
not
just
computing.
One
big
nonlinear
function
right.
It's
not
like
there's
a
top
box.
A
So
in
the
sort
of
deep
learning
point
of
view,
this
would
be
the
input
and
the
stuff
on
the
right
would
be
the
output
and
then
all
the
stuff
in
the
middle
is
just
in
service
to
the
top
box.
It's
just
helping
you
compute
some
nonlinear
function
that
can
classify
faces
or
you
know,
command
a
robot
to
do
something
or
whatever
it's
just
stuff
in
the
middle.
That's
that's
this
helping
you
compute!
This
big
function,
f
of
X,
so
X
is
the
input
and
then
you
pass
X
to
the
network,
which
is
f.
A
W
are
the
parameters
all
the
weights
within
the
neural
network
and
you're,
trying
to
Train
this
big
nonlinear
function.
To
do
some
task,
which
is
like
the
top
box
up
here,
and
what
the
neuroanatomy
tells
us
and
the
physiology
tells
us
is
fundamentally
that's
not
the
kind
of
system.
It
is
that's
entirely
the
wrong
way
to
conceptualize
it
right.
If
you
start,
you
start
from
that
framework.
A
You're
not
gonna,
gain
any
insights
about
what
the
system
is
doing
and
you're
gonna
be
totally
missing
the
boat
and
as
well
you're,
not
exploiting
the
rich
structure
here
right.
This
is
this
is
fundamental
to
how
we
behave,
how
we
drive
cars,
how
we
eat,
how
we
recognize
images,
how
we
do
everything
in
the
world
and
and
and
this
always
want
to
understand-
how
we
do
these
things.
We
have
to
understand
this
circuit
and
how
the
thalamus
and
cortex
work
together,
as
well
as
the
fact
that
these
almost
all
this
information
flow.
A
This
is
something
that's
still
very
non-intuitive
to
us
how
all
this
information
flow
is
essentially
bi-directional:
okay,
so
the
bi-directional
information
flow
between
between
cortex
and
thalamus,
but
also
between
all
these
cortical
areas.
So
it's
not
shown
in
these
and
these
black
bands
between
areas.
The
thickness
of
these
black
bands
denotes
how
much
white
matter
is
devoted
to
the
malicious
go
back
a
little
bit.
The
thickness
of
these
wires
denotes
how
much
white
matter
is
devoted
to
these
connections,
but
all
these
connections
you
see
SS
are
essentially
bi-directional.
A
So
v1
projects
v2
v2
projects
back
to
v1,
okay.
So
why
would
you
want
to
do
that?
Lgn
relays
information,
v1,
v1
projects
back
to
LG
yet
and
modifies
the
representation
here
this
in
turn
sent
back
to
cortex?
Okay?
Why
is
that
good?
How
does
that
help
you
see?
This
is
something
again
that
the
field
of
neuroscience
would
greatly
benefit
from
computational
theories
that
provide
insight
and
and
and
and
vice-versa,
the
field
of
computational
vision
would
have
much
to
gain,
probably
by
incorporating
these
kinds
of
structures
in
their
models
and
making
much
richer
visual
systems.
A
So
this
is
really
some
really
neat
work
that
came
out
recently
from
matthias
bet
cos
lab
where
they,
you
probably
heard
of
this
work,
where
you
can
sort
of
create
these
so-called
adversarial
examples
for
neural
networks,
where
you
take
a
picture
of
a
bus
and
perturb
the
pixels
a
little
bit,
and
then
it
classifies
it
as
a
fire,
hydrant
or
a
penguin,
or
something
completely
different
right
and
so
they're
trying
to
get
to
the
bottom
of
this
understand.
Well,
why
is
that?
Why
is
that
happening?
A
These
are
images
which,
which
they
generated
for
the
network,
which
have
you
know,
basically
have
the
same
features
as
this
and
fool
the
neural
network
into
saying.
Well,
it's
the
same
category
as
this
with
very,
very
high
confidence.
Okay.
So,
since
this
this
is
what
you're
sort
of
witnessing
here
is
the
null
space
of
the
neural
network
model.
It
basically
thinks
that
everything
here
in
this
row
is
equivalent.
It
has
no
way
of
differentiating
these
things
from
each
other.
Everything
in
this
row
is
considered
to
be
equivalent.
A
Everything
in
this
row
is
considered
to
be
equivalent.
Okay,
this
is
the
way
these
neural
networks
see
the
world
and
obviously
that's
a
very
poor
perceptual
model.
If
you're
trying
to
capture
the
way
things
think
we
do
things
okay,
so
let's
go
back
to
these
original
models
that
we
that
that
we
introduced
the
beginning,
the
the
so
called
the
perceptron
model
and
the
the
confident
model
Fukushima,
which
essentially
all
of
deep
learning
today
is
based
on
these.
A
But
you
can
write
down
a
mathematical
formula
for
anything
right
that
you
you
come
up
with.
That's
not
the
point.
The
point
is
that
they're
not
based
on
any
kind
of
first
principles,
Reap
first
principles,
reasoning
from
mathematics
that
would
sort
of
lead
you
to
believe
a
priori
that
a
weighted
sum
and
Thresh
holding
is
a
good
thing
to
do
right
or
that
a
cognate
a
with
this
good
thing
to
do
or
stacking
the
things
in
a
hierarchy
that
that's
a
good
thing
to
do.
A
Okay,
it's
just
kind
of
based
on
loose
kind
of
biological,
mimicry.
Okay,
so
let's
take
a
casual
look
at
a
neuron
and
saves
the
make
babies
because
sort
of
loose
model
of
what
it
does
and
things
like
that.
Okay,
so
it's
not
really
based
on
anything
all
the
stuff
that
we're
taking
very
seriously
today
and
in
these
neural
networks.
It's
not
based
on
anything
that
should
shock
you,
okay,
and
so
it's
it's
something
that
I'm,
not
okay,
shouldn't
I,
don't
mean
to
be
too
critical
right.
A
But
the
point
is
to
inspire
you
inspire
others
to
think
bigger
right,
so
that
was
this
is
a
great
start
where
the
field
is
now
I.
Think
it's
you
know.
Obviously
some
gains
we've
made
these
networks
do
very
interesting
things.
So,
let's,
let's
you
know,
take
some
comfort
in
that.
But
the
point
is
I
guess
I'm
trying
to
make
here
is
that
there's
a
lot
lot
more,
a
lot
more
Headroom
a
lot
longer
ways
to
go
and
much
more
that
we
could
exploit
to
do
better.
A
Okay,
so
so
then,
so
what
should
we
be
doing
so?
I
argued
that
these
these
neural
networks
really
aren't
solving
the
right
problem,
so
formulating
the
court
formulated
in
the
cortex
as
f
of
X
semicolon
W
is
not
really
the
right
way
to
conceptualize
what
a
brain
is
doing
and
your
trading
on
a
classification
task.
Okay.
So
how
should
we?
A
How
should
we
sort
of
point
our
efforts
in
in
the
right
direction
and
women
argue
here-
is
that
there's
some
places
we
can
turn
to
for
inspiration
and-
and
so
one
is
not
beyond
just
the
brain
itself.
Actually,
so
one
is
animal
behavior.
Another
is
psychophysics,
a
philosophy.
I
think
that's
a
lot
to
teach
us
and
also
mathematics,
so
I'll
just
go
through
a
couple
of
these
in
turn.
So
let's
first
turn
to
an
oblate
animal
behavior.
A
So
these
are
just
four
examples
of
from
the
animal
kingdom
kingdom
of
animals
that
do
not
only
vision
but
electro
sensation
and
all
kinds
of
other
groovy
things
so
I'll
just
kind
of
talk
about
them
a
little
bit
here.
The
jumping
spider
has
a
total
of
eight
eyes
on
these
two
forward.
Looking
eyes
in
the
front,
have
very
large
lenses
and
give
the
jumping
spider
very
high
resolution
with
which,
with
which
it
can
do
pattern
vision.
So
a
jumping
spider
can
basically
recognize
another
spider
of
conspecific
just
from
vision
alone.
It
can
navigate
three-dimensional
mazes.
A
It
can
do
all
kinds
of
amazing
things
with
its
visual
system,
it's
very
visually
aware
of
its
environment.
It
uses
this
the
eyes
on
the
side
of
his
head.
You
can't
see
them
on
the
they're,
so
actually
pointing
off
to
the
side
to
detect
things
that
move
and
when
it
sees
something
that
moves
like
a
like
a
fly
that
wants
to
capture,
then
it
rotates
its
head
toward
towards
it
to
image
it
with
these
high-resolution
eyes
and
I'll
show
you
later
that
these
high-resolution
eyes
actually
have
a
one-dimensional
strip.
A
The
retina
is
a
1d
strip
and
then
it
scans
that
back
and
forth
to
to
view
the
image
okay,
so
it's
really
remarkable
behavior
and
and
so
as
you
notice,
and
when
we
look
at
all
these
animals,
we
have
to
sort
of
think
about
this
question.
What
problem
are
they
solving
right?
What
Palmer
they
solving
well
object.
Recognition
is
one
of
it
right.
They
want
to
recognize
conspecifics,
but
that's
you
know
like
the
tip
of
the
iceberg.
There's
a
ton
of
other
problems,
they're
solving
to
navigate
around
in
the
world.
The
sand.
A
Wasp
is
another
Byrne
remarkable
example.
It
has
a
compound
eye
and
unlike
these
sort
of
camera
like
I,
so
the
jumping
spiders
have
so
the
the
compound
eye
actually
has
very
low
resolution.
So
we
cannot
recognize.
You
know
spiders
or
other
conspecifics,
just
from
their
visual
system
alone
has
a
very
blurry
view
of
the
world,
but
it's
very
good
at
tracking
tracking
things
at
high
speed
in
motion
and
one
of
things
that
San
wasp
does
it.
Well,
it
hunts
bees.
It
hunts
bees.
A
As
far
as
a
mile
away
from
its
nest,
it
builds
us
nest
in
the
sand.
Has
points
called
the
San
Blas
if
it
has
just
a
hole
like
a
burrow
in
the
sand
where
that's
that's
its
home
and
then
it
can
fly
as
much
as
far
as
a
mile
away
from
home
to
capture
a
bee
and
bring
it
back
to
its
nest,
and
so
Nick
and
Niko
Tinbergen
wondered
well.
How
do
they
do
that?
A
How
do
they
navigate
and
find
their
find
their
way
home,
and
not
only
that,
but
even
when
they
get
in
the
vicinity
of
their
nest?
How
do
they
find
this
little
hole
in
the
ground,
which
is
there,
which
is
their
nest,
and
what
he
showed
is
that
they
can
actually
recognize
from
the
debris
sitting
around
the
necks
that
that's
the
pattern
of
degree,
the
to
the
spatial
pattern
of
debris
sitting
around
the
nest
they
can
recognize
where,
where
home
is
so,
they
can
do
some
kind
of
pattern.
A
Vision
from
that,
you
know
remarkably
well
they're
sort
of
flying
around
in
the
world
and
so
again
really
remarkable
capacity
to
emit
navigate
the
box
jellyfish.
Even
perhaps
even
more
remarkable
doesn't
even
have
a
brain.
It
has
a
remarkable
visual
system
and
has
total
24
eyes,
and
at
least
four
of
these
eyes
have
very
high
resolution.
So
Dan
Nielsen
has
taken
to
these
in
the
lab
and
shown
that
there,
their
lens
is
actually
aberration
free.
A
It
forms
out
like
a
perfect,
perfect
image,
it's
better
even
than
our
lens
right,
so
it's
like
amazingly
perfectly
evolved
lens,
and
these
these
these
these
these
eyes
here
point
towards
the
water
surface.
They
have
little
counter
weights
on
them
that
always
keep
the
eye
pointed
towards
the
water
surface,
no
matter
what
direction
that
the
box
jellyfish
is
oriented
in,
and
it's
thought
that
they're,
using
as
a
visual
system
to
kind
of
survey,
the
terrestrial
landscape
around
it.
A
So
they
have
an
electric
organ
back
here,
which
generates
an
electric
field
not
to
stun
other
animals
or
fish.
It
actually
just
uses
it
as
a
sensing
apparatus,
and
so
they
it
generates
these
electric
fields,
and
then
it
has
the
electro
sensors
all
over
the
skin
surface,
which
detect
distortions
in
the
electric
field
and
that's
how
it
sort
of
ascertains
what's
out
there
so
stuff
matter
out.
There
in
the
world
that
conducts
this
conducting
material
will
tend
to
condense.
A
These
electric
field
lines
and
other
material
will
tend
to
leave
them
more
spaced
apart,
and
it
actually
has
a
fovea
a
much
more
dense
region
of
packed
electro
sensory
organs
that
it
uses
to
form
a
more
sort
of
high-resolution
image
of
how
the
logic
field
is
distorted.
Okay,
so
it's
interesting
question
to
ask:
well
how
does
the
world
appear
to
electric
fish,
but
it
can
never
suffice
it
to
say
they
can
do
three-dimensional
navigation
based
on
electro
sensation.
A
So
if
they,
this
has
been
shown
in
the
lab
they
can
sort
of
just
by
how
the
electric
field
is
distorted
around
them,
they
get
a
sense
of
three-dimensional
space
and
they
can
navigate
around
objects,
they
can
find
objects
to,
hunt
and
prey
upon
and
so
forth.
Okay,
so
these
are
all
I,
think
really
remarkable
examples
to
contemplate
and
think
about.
A
A
There's
a
there's,
a
phenomenon
with
it
within
the
not
a
phenomenon,
but
a
paradox
in
the
robotics
community
called
more
of
X
paradox,
and
this
is
named
for
the
roboticist
Hans
Hans
Moravec,
who
kind
of
observed
that
you
know
well,
isn't
it
kind
of
curious
that
we
can
build
now,
computers
that
can
play
chess?
They
can
play
NGO.
They
can
do
all
these
remarkable,
so
so-called
intellectual
feats,
but
they
can't
even
stand
up
and
open
a
door.
You
know
let
alone
do
these
things
here.
A
Ok,
so
there's
something
about
dealing
with
the
real
three-dimensional
world:
the
physical
environment.
Just
you
know,
coping
in
the
3-dimensional
world
wind
blows
on
you
sand
blows
in
your
face
all
kinds
of
unpredictable
things
you
happen
and
you
have
the
robustness
you
have
the
ability
to
survive
and
and
deal
with
these
unpredictable
events
and
a
kind
of
general
intelligence
in
a
way
that
can
deal
with
unforeseen
circumstances
all
the
time.
Ok,
this
is
something
to
kind
of
wrap
our
heads
around
and
and
and
think
about
solving
these
kinds
of
problems.
A
So
so
that
that's
animal
behavior
I
mentioned
psychophysics,
there's
a
bunch
of
interesting
findings
in
psychophysics,
which
I
think
tell
us
much
about.
They
give
us
a
very,
very
strong
hints
about
what's
going
on
inside
the
brain
without
ever
putting
electrode
into
the
brain,
but
I'll
point
you
to
one
really
astounding
one
in
particular.
This
is
the
work
of
Ken,
Takayama
and
chinchou
mojo,
and
he
Jiang
say
here
that
occurred
during
in
the
mid
1990s
and
that's
the
work
on
visual
surface
representation.
So
what
they
showed
through
a
series
of
very
cleverly
designed
experiments.
A
This
is
like
the
hubell
weasel,
you
know
story
and
then
in
v2
you
would
have
even
more
complex
neurons,
maybe
things
that
determine
detect
key
Junction,
T
junctions
or
curvature
detectors,
and
things
like
that
that,
contrary
to
that
idea
that
that's
you
know
that
that's
not
what
the
system
is
doing.
It
doesn't
work
that
way.
It
doesn't
simply
extract
features
from
the
two-dimensional
image
rather
very
quickly.
It
gets
into
a
three-dimensional
format.
A
It
takes
the
image,
pixel
data
and
tries
to
make
an
explicit
representation
of
surfaces,
for
example
these
surfaces,
these
tables
they
would
be
labeled
differently,
even
in
with
in
v1.
Those
neurons
in
v1
really
have
information
about
the
properties
of
that
surface
and
how
it
extends
in
three-dimensional
space
and,
moreover,
where
about
words,
boundaries
are
okay,
that
information
is
spread
across
surfaces
within
the
within
these
cortical
representations
and
stops
at
the
edges
of
these
surfaces.
Okay,
so
I
can't
go
into
the
details
here.
A
I'll
just
turn
you
this
paper,
it's
a
wonderful
paper
because
it
just
sort
of
summarizes
all
their
experimental
findings
and
it
sort
of
shows
one
after
the
other.
That
sort
of
arguing
in
terms
of
the
surface
view,
rather
than
this
point
of
view,
so
this
really
kind
of
Orient's
you
differently,
not
only
as
a
neurophysiologist.
A
It
says
really,
if
you're
doing
neurophysiology
on
these
cortical
areas,
you
should
be
sort
of
examining
it
in
a
different
way
and
asking
different
questions
and
using
different
kinds
of
stimuli,
but
also
as
a
computational
person
trying
build
models
of
the
system.
You
shouldn't
be
just
building
little
cognate
features
that
sort
of
detect
two-dimensional
features
from
the
image.
You
should
be
trying
to
sort
of
look
for
something
different
and
extracting
stuff
something
more
related
to
surfaces.
A
This
is
a
really
important
aspect
of
representation,
so
he
gives
some
one
of
the
examples
that
he
may
rely
upon
in
this
work
is
simple
phenomenology,
so
I'll
give
you
an
example
of
this
phenomenology
here
with
in
this
striking
example
of
our
brains
to
sort
of
pull
out
surface
structure
from
from
a
scene,
and
so
this
is
an
image
of
something
if
you've
seen
it
before,
don't
speak.
But
if
you,
if
you
haven't
seen
it
before
I'll,
just
ask
you:
does
anybody
here?
A
Do
any
of
you
recognize
what
you're
looking
at
show
of
hands
if
you've
nuts,
yes,
no
okay,
no
hands
all
right,
so
it
kind
of
just
looks
like
maybe
a
sort
of
an
amorphous
set
of
white
and
black
white
and
black
splotches
in
this
scene
here
and
so
in
this
particular
case,
one
subject
was
asked
to
draw
what
they
see
and
this
object.
This
is
one
way
of
sort
of
interrogating.
A
The
visual
system
is
to
you
know,
ask
the
person
to
draw
what
they
see,
and
so
this
is
what
one
subject
drew
as
a
line
drawing
to
depict
this
scene
you're.
Just
they
just
do
the
boundaries
of
these
sort
of
different
black
and
white
splotches.
So
for
those
of
you
who
couldn't
see
the
figure
in
the
scene,
how
many
of
you
would
it
would
would
agree
that
this
is
sort
of
a
reasonable
depiction?
You
would
draw
something
like
that:
okay,
fair
number
number
hands.
Okay.
A
For
some
people?
That's
enough,
just
to
say,
say:
cow,
because
a
minute
is
you
think
about
cow,
you
sort
of
try
to
fit
a
cow
model
to
it.
Then
you
can
start
to
see
it.
Okay,
I'll
tell
you
a
little
more.
This
is
the
head
of
the
cow,
and
this
is
the
snout
and
then
here
the
eyes,
that's
an
eye.
There
there's
another
eye
over
here.
A
So
it's
kind
of
remarkable
right,
I
mean
the
same
subject.
Do
this
and
then
you
know
few
minutes
later
they
do
this.
So
the
only
thing
that's
different
is
what's
inside
their
head.
Okay,
so
when
they
initially
saw
this
figure
without
knowing
what
it
is,
they
had
one
representation
inside
their
head
and
when
you
interrogate
that
representation,
it
just
tells
you
about
the
boundaries.
This
is
like
just
the
idea
of
extracting
two-dimensional
features.
This
is
something
like
the
representation
in
your
retina.
Your
retina
has
a
representation
like
this.
A
It's
just
a
sort
of
expiring
to
the
boundaries
two-dimensional
features
within
the
image,
because
that's
all
it
knows
about
it's
not
trying
to
build
a
model
of
the
world.
It's
just
representing
data
about
the
world.
That's
the
data!
Okay,
that's
just
the
image
data!
Okay,
this
comes
from
inside
your
head.
This
is
a
model.
This
is
a
model,
that's
made
up
not
out
of
nothing,
but
it
is
basically
conjured
up
inside
your
head
and
that's
what
you're
experiencing
here
and
this
model
is
expelled
is
it
consists
mainly
of
surfaces?
A
Okay,
so
you
sort
of
so
and
see.
This
is
one
surface,
and
you
see
this
is
another
surface,
because
this
person
note
that
they
drew
a
boundary
here
right
and
that
person
had
no
right
to
draw
a
boundary
from
the
data
alone.
I
mean
there's
absolutely
zero
evidence
for
a
boundary
there
in
the
raw
image
data,
okay.
Nevertheless,
the
subject
says
well:
this
is
one
surface
belonging
to
the
head,
and
this
is
another
surface.
A
Okay,
moreover,
you're
explaining
away
all
kinds
of
details
about
these
black
and
white
boundaries,
these
black
and
white
boundaries,
which
are
kind
of
undifferentiated
to
you
before
you'd,
probably
say
this
is
due
to
the
cows
reflectance,
like
that's
a
black
fur.
This
is
white
fur.
Maybe
this
is
something
like
a
black
and
white
cow
right
and
whereas
this
boundary
here,
where
it's
white
here
is
black
here,
you
say:
well,
that's
do
the
three-dimensional
shape
of
the
cow?
Let's
do
the
structure
of
the
head.
That's
tell
me
something
about
the
shape
from
the
shading
information.
A
Okay,
so
you
explaining
away
all
kinds
of
details
is
a
very
layered
representation,
but
it's
entirely
in
terms
of
surfaces
and
then
there's
this
idea
of
the
cow.
Okay,
you
know
it's
a
cow,
the
high-level
classification,
but
what
but
but
a
lot
of
it
is
just
sort
of
perceiving
the
rich,
very
rich
three-dimensional
structure
of
the
scene
and-
and
this
is
kind
of
the
basis
of
of
what's
going
on
inside
your
head.
A
So
this
is
what
Nakayama
is
arguing
from
psychophysics
is
that
you
really
need
that
think
about
how
the
brain
sort
of
gets
into
this
kind
of
format
of
representation
like
a
3d
surface
representation,
as
opposed
to
just
extracting
2d
features
like
you
know,
lines
and
curves,
and
things
like
that:
okay,
the
the
fourth
I'm.
Sorry,
the
third
one,
the
third
sort
of
area
I
mentioned
to
turn
to
is
philosophy
and
I'll.
Just
point
you
to
a
really
beautiful
piece
of
work
by
a
pair
of
philosophers.
A
So
it's
trying
to
sort
of
look
at
this
problem
of
visual
awareness,
and
where
is
that
you
know
if
you're
looking
for
the
neural
correlate
of
visual
awareness,
how
to
how
to
go
about
doing
that
and
so
I'll.
Just
summarize
the
abstract
here.
This
is
just
a
few
sort
of
key
senses
from
the
abstract
and
what
they're,
what
they're
sort
of
coming
in
and
saying
is
that
seeing
or
vision
is
a
way
of
acting
okay.
A
This
is
just
like
totally
anathema
to
the
way
to
the
vision
people
think
about
vision,
okay,
but
they're,
saying
look
if
vision
is
not
about
building
an
internal
representation
of
the
world
of
doing
it,
building
a
visual
representation
seeing
is
really
a
way
of
acting
with
the
acting
in
the
world
and
that
the
activity
in
these
internal
representations
does
not
generate
the
experience
of
seeing
okay.
So
rather
they're
saying
the
experience
of
seeing
occurs
when
the
organism
masters.
This,
though
governing
laws
of
sensory
motor
contingency.
So
what
is
sensory
motor
contingency?
A
They
just
took
a
very
simple
robot,
robotic
creature,
with
all
kinds
of
cameras
attached
to
it
in
all
kinds
of
actuators.
I
showed
that,
from
this
joint
space
you
could
discover
the
six
degrees
of
freedom
of
the
physical
world.
Okay.
So
it's
a
very
rich
idea,
both
computationally
and
neuro,
physiologically
I.
A
Okay
and
then-
and
then
maybe
this
is
so
it's
an
example
of
this
idea
of
the
sensory
motor
of
sensory
motor
contingencies.
And
you
know
animals
that
use.
This
will
turn
back
here
to
the
jumping
spider.
So
so
this
is
just
showing
you
a
sort
of
cross
section
inside
the
jumping
spiders
head
these
eight
eyes.
So
these
two
forward
looking
eyes
to
other
eyes
on
the
side,
also
pointing
forward
these
eyes
on
the
side,
have
fisheye
lenses
with
like
360-degree
coverage,
point
of
view,
but
very
blurry.
A
And
then
these
two
tiny
eyes
are
pit
eyes
here
on
this
side
of
the
head.
So
a
total
of
eight
eyes,
four
pairs
of
eyes-
and
this
is
just
a
video
of
a
baby
jumping
spider,
a
one-day-old
jumping
spider
and
because
it's
an
infant
jumping
spider
that
the
exoskeleton
is
translucent,
so
you
can
see
through
it.
A
So
you
can
see
these
tubes
moving
back
and
forth
inside
this
head,
so
it's
retina,
so
it's
retina
is
at
the
end
of
these
tubes
here,
okay,
so
the
retina
is
back
here
and
the
retin
is
basically
a
one-dimensional
strip
of
photoreceptors.
Okay.
These
are
storing
the
photoreceptors
here.
They're,
basically
they're
just
arranged
in
a
one-dimensional
strip,
not
a
2d
array,
and
they
take
this
array
and
they
scan
it
back
and
forth
by
moving
that
tube
back
and
forth.
Okay,
so
you
can
see
that
moving
back
and
forth
inside
the
head.
A
So
this
is
very
much
an
active
process.
It's
like
the
whiskers
of
a
rat
when
it
whisks
right,
okay.
So
it's
moving
this
thing
back
and
forth
and
as
it
collects
information
about
the
world-
and
it
has
to
somehow
put
it
together-
it's
the
sensorimotor
contingency
how
the
sensory
information
just
looking
at
this.
If
you
just
looked
at
these
information
alone
from
these
from
these
pixels,
that
would
tell
you
nothing
would
be
almost
meaningless
in
order
to
interpret
this,
you
have
to
know
how
the
eye
is
moving
at
the
same
time,
and
then
you
can.
A
Then
you
can
sort
of
learn
something
about
the
world.
Okay,
so
it
uses
this
in
abundance,
and
then
you
know
this
is
just
an
example:
the
jumping
spider
again,
a
one-day-old
jumping
spider.
This
is
markable
for
many
other
reasons,
but
it's
just
attending
to
a
fruit
fly.
So
it's
going
to
jump
out
and
capture
it
later
and
part
of
this
strip
see.
But
here
but
but
it's
you
know,
has
this
remarkable
ability
to
attend
as
I
mentioned
earlier,
and
it's
all
sort
of
an
active
process.
A
A
So
he's
a
mathematician
and
he's
looking
at
this
problem
from
vision,
the
problem
of
vision
from
a
mathematical
point
of
view
and
saying:
okay,
weren't
the
what
are
the
fundamental
problems
that
need
to
be
solved:
okay
or
what?
What
is
this
sort
of
that?
What's
this?
What's
the
mathematical
structure
of
this
problem
and
what
he
says
is
capable
there's
three
kind
of
components
to
it,
what
one
thing
they
call
sparse,
discreteness
the
fact
that
there's
patterns
in
the
world?
A
Okay-
so
there's
like
you
know
they
think
of
those
a
letter,
the
alphabet
or
the
shapes
of
objects,
and
things
like
that.
Okay,
so
there's
particular
kinds
of
patterns
that
you
see
in
the
world
and
they're,
rather
discrete
they're
like
categories
okay,
the
other-
and
this
is
another
type
of
pattern
that
we
don't
often
think
about
is
transformations.
So
as
we
move
through
the
world,
these
images
that
fall
onto
our
retina
are
highly
dynamic.
Okay,
so
things
are
transforming
this
information.
A
These
patterns
that
fall
on
a
retina
they
transform
over
time
and
the
transformations
are
a
kind
of
pattern
in
them
in
them
in
their
own
right.
Okay,
so
that's
another
fundamentalist
thing
to
describe
and
then
hierarchy.
The
idea
that
holes
are
holes
are
composed
of
parts,
parts
are
in
turn,
composed
of
sub
parts
and
so
forth,
okay
and
then
so
he
goes
about
in
this
work,
trying
to
develop
a
mathematical
framework
or
sort
of
attacking
each
of
these
problems.
A
So
the
idea
is,
when
you
do
this,
when
you
actually
take
a
sparse
representation
and
map
it
into
a
low
dimensional
manifold.
That's
makes
explicit
these
transformations
that
are
occurring
in
the
in
the
input,
and
this
was
this
was
very
much
inspired
in
you
Bayes
mind.
It
was
inspired
by
David
Mumford's
pattern.
Theory,
this
mathematical
framework.
A
It
was
called
holographic,
reduced
representations
and,
and
then
pen
tikka
nervous
sort
of
more
more
recently
trying
to
popularize
this
maybe
loose
word
for
it.
Maybe
sort
of
try
to
extend
the
theory
in
various
ways
and-
and
he
calls
it
hyperdimensional
computing
of
the
idea
of
computing
with
high
dimensional
vectors.
But
the
basic
idea
is
just
shown
here
is
that
basically,
everything
in
this
framework
is
represented
with
a
high
dimensional
vector
rather
than
a
single
neuron.
Ok,
so
if
you
think
about
it,
many
of
our
neural
network
models
are
really
based
on
single
neuron
thinking.
A
So
back
in
the
1950s
1960s.
When
people
first
started
probing
the
brain
they're
using
electrode,
they
poked
into
the
brain
and
out
of
all
those
millions
of
neurons
sitting
there
they
record
from
one
neuron
and
they
listen
to
its
action
potential.
So
they
try
to
create
a
story.
They
say,
oh,
that
neuron
is
a
feature
detector.
That
neuron
is
a
fly
detector
right.
That
neuron
is
a
speed
detector.
That
neuron
is
a
color
detector.
A
Ok,
so
they
sort
of
develop
this
kind
of
single
neuron
way
of
thinking
about
what
the
nervous
system
is
doing,
and
we've
kind
of
embraced
that
in
our
models,
all
these
perceptron
based
deep
learning
models
are
really
fundamentally
single
neuron
models.
Ok,
it's
all
in
the
spirit
of
like
this
neuron
does
that
that
neuron
does
that
or
what
we
also
called
labeled
lines
and
a
pen
T's
kind
of
a
observation
way
he's
coming
at
it
and
also
Tony
plate.
Is
that
really,
when
you
look
at
the
nervous
system,
it's
not
like
that.
A
It's,
but
you
see,
is
these
very
large
high
dimensional
circuits,
so
many
neurons,
together,
they're,
all
highly
densely
occurred
to
each
other.
So
thinking
of
the
neuron
is
a
fundamental
unit.
May
not
be
the
right
starting
point.
You
want
to
rather
think
of
a
population,
a
large
population
of
neurons
or
what
other
people
also
other
people
also
call
a
cell
assembly
that
that's
that's
the
right
starting
point
and
way
to
sort
of
think
about
representations.
A
So
so
the
idea
in
this
framework,
everything
is
represented
by
a
high
dimensional
vector,
so
on
the
order
of
10,000
bits
and
there's
three
fundamental
operations:
multiplication
used
for
binding
addition
used
for
combining
things
and
then
permutation
used
for
sequences.
Okay
and
again,
you
know
these
weren't,
just
sort
of
pulled
out
of
the
blue.
These
were
formulated
really
from
first
principles.
Thinking
of
thinking
about,
like
what
do
I
need
to
do.
If
these
are
the
things
I
need
to
solve,
I
want
to
be
able
to
do
binding.
A
I
want
to
be
able
to
combine
things,
I
want
to
be
able
to
do
sequencing,
and
how
do
I?
How
do
I
do
these
things
and
and
Pentti
is
also
showing
this
approximates
a
field
in
terms
of
mathematics.
Ok,
so
I
think
I'm
running
out
of
time,
so
I'm
gonna
just
skip
ahead
to
the
end
and
happy
to
talk
later
about
some
of
the
examples
of
high
dimensional
computing.
A
But
but
this
is
something
that
we're
working
on
a
lot
in
my
own
lab
right
now
is
trying
to
apply
this
idea
of
high
dimensional
computing
array
of
different
problems,
envisioned
in
audition
in
speech,
recognition
and,
ultimately
in
robotics,
and
we're
also
working
on
a
project
for
abusing
that
using
this
framework
as
a
model,
the
cerebellum
okay.
So
the
I'll
just
summarize
kind
of
that.
The
main
points
that
I've
tried
to
leave
you
with
is
that
is
that
I
think
the
the
field
of
artificial
intelligence,
deep
learning,
computational,
modeling
and
so
forth.
A
A
You
see
these
laminar
structures
in
the
cortex
so
where
the
computational
different
roles
in
these
different
layers,
that
bi-directional
flow
of
information
is
probably
hugely
important,
so
how
information
flows
in
these
feedback
loops,
there's,
probably
a
lot
that
can
be
gained
from
that
and
the
field
is
really
just
at
a
loss
for
even
how
to
think
about
that
right.
Now,
okay
and
then
in
terms
of
what
problems
we
should
be
solving
I'm
acting
in
the
real
physical
world
like
insects
and
spiders,
and
all
these
their
animals
have
to
do
their
solving
some
problems.
A
We
don't
normally
think
about
which
are
probably
enormous,
ly
important
and
and
we're
overlooking
right
now,
and
so
the
other
is
in
terms
of
vision,
thinking
about
surface
representation
rather
than
feature
extraction,
rather
than
sort
of
extracting
two-dimensional
features
from
the
image.
How
do
you
represent
surfaces
in
the
world
and
group
things
together
and,
and
then
also,
this
idea
of
learning
from
censoring
the
sensory
motor
contingency
is
that
Alvin
Oh,
Ian
Kevin
are--can
have
been
fans
in
the
joint
sensory
motor
space.
A
And
finally,
you
know,
as
I
mentioned
before,
I
think
of
really
new
kinds
of
math
are
going
to
be
needed
to
understand
and
the
system
but
to
potentially
newish
kinds
of
directions.
I'm
very
excited
about
this
one
is
this
framework
of
David
Mumford,
the
pattern
theory
and
a
high
dimensional
computing
framework,
which
I
think
that's
a
lot
of
mileage
and
probably
many
others.
Okay,
so
that's
it
take
questions.