10 Dec 2020
Lianmin Zheng, U.C. Berkeley
High-performance tensor programs are crucial to guarantee efficient execution of deep learning models. However, obtaining performant tensor programs for different operators on various hardware platforms is notoriously difficult. Currently, deep learning systems rely on vendor-provided kernel libraries or various search strategies to get performant tensor programs. These approaches either require significant engineering efforts in developing platform-specific optimization code or fall short in finding high-performance programs due to restricted search space and ineffective exploration strategy.
We present Ansor, a tensor program generation framework for deep learning applications. Compared with existing search strategies, Ansor explores much more optimization combinations by sampling programs from a hierarchical representation of the search space. Ansor then fine-tunes the sampled programs with evolutionary search and a learned cost model to identify the best programs. Ansor can find high-performance programs that are outside the search space of existing state-of-the-art approaches. Besides, Ansor utilizes a scheduler to simultaneously optimize multiple subgraphs in a set of deep neural networks. Our evaluation shows that Ansor improves the execution performance of deep neural networks on the Intel CPU, ARM CPU, and NVIDIA GPU by up to 3.8×, 2.6×, and 1.7×, respectively.
High-performance tensor programs are crucial to guarantee efficient execution of deep learning models. However, obtaining performant tensor programs for different operators on various hardware platforms is notoriously difficult. Currently, deep learning systems rely on vendor-provided kernel libraries or various search strategies to get performant tensor programs. These approaches either require significant engineering efforts in developing platform-specific optimization code or fall short in finding high-performance programs due to restricted search space and ineffective exploration strategy.
We present Ansor, a tensor program generation framework for deep learning applications. Compared with existing search strategies, Ansor explores much more optimization combinations by sampling programs from a hierarchical representation of the search space. Ansor then fine-tunes the sampled programs with evolutionary search and a learned cost model to identify the best programs. Ansor can find high-performance programs that are outside the search space of existing state-of-the-art approaches. Besides, Ansor utilizes a scheduler to simultaneously optimize multiple subgraphs in a set of deep neural networks. Our evaluation shows that Ansor improves the execution performance of deep neural networks on the Intel CPU, ARM CPU, and NVIDIA GPU by up to 3.8×, 2.6×, and 1.7×, respectively.
- 2 participants
- 24 minutes

10 Dec 2020
Jorn Tuyls, Xilinx
The vast computational complexity of deep learning creates significant challenges to meet latency and throughput constraints in real-life applications. In recent years this problem has spurred extensive exploration for viable machine learning acceleration techniques which has resulted in a great mixture of toolboxes and custom hardware architectures. However, a large gap currently exists in the industry between developing machine learning models through accessible machine learning frameworks and deploying those models inside real-life applications through these specialized toolboxes and hardware accelerators. This talk explores the technologies used through TVM to bridge this gap for both cloud and edge Vitis-AI FPGA based hardware accelerators. Specifically, we discuss how we exploit the TVM Bring Your Own Codegen (BYOC) features like annotation, partitioning and codegen implementation wrappers and the Vitis-AI PyXIR graph, quantization and runtime abstractions to integrate custom accelerator quantization, compilation and runtime tools.
The vast computational complexity of deep learning creates significant challenges to meet latency and throughput constraints in real-life applications. In recent years this problem has spurred extensive exploration for viable machine learning acceleration techniques which has resulted in a great mixture of toolboxes and custom hardware architectures. However, a large gap currently exists in the industry between developing machine learning models through accessible machine learning frameworks and deploying those models inside real-life applications through these specialized toolboxes and hardware accelerators. This talk explores the technologies used through TVM to bridge this gap for both cloud and edge Vitis-AI FPGA based hardware accelerators. Specifically, we discuss how we exploit the TVM Bring Your Own Codegen (BYOC) features like annotation, partitioning and codegen implementation wrappers and the Vitis-AI PyXIR graph, quantization and runtime abstractions to integrate custom accelerator quantization, compilation and runtime tools.
- 2 participants
- 23 minutes

10 Dec 2020
Michael J. Klaiber, Bosch Corporate Research
The end-to-end performance of recent deep neural network systems is mainly affected by three domains: First the workload, a neural network, which defines the computational tasks and the memory requirements, second the hardware which defines an upper limit of the computational resources, the memory resources and the communication resources, and last the compiler toolchain that maps the workload onto the available hardware resources and schedules the order of the tasks of the workload.
All of these three domains have a tremendous impact on the overall performance of a workload that is executed on the target hardware. Classic development processes, however, keep these three domains often separated until the end of the implementation phase which might be too late for significant changes in either of them. We demonstrate a proof-of-concept of a methodology that uses an (abstract) virtual hardware model of a Coarse-Grained Reconfigurable Architecture (CGRA) hardware accelerator to predict the execution time of a neural network, that performs object-type classification of radar spectrum data accurately down to the transaction level. A key role in this setup plays TVM which we use to transform the high-level algorithmic description to a hardware-aware task graph, that can be simulated on an abstract virtual hardware model. Unlike other approaches that simulate a compiled binary on a detailed hardware model, we use a backend to generate the task graph that is simulated on the virtual system model.
This approach enables algorithm designers to estimate performance accurately for a target system while hardware architects explore the impact of architectural optimizations through an easily adaptable abstract model of the hardware system.
The end-to-end performance of recent deep neural network systems is mainly affected by three domains: First the workload, a neural network, which defines the computational tasks and the memory requirements, second the hardware which defines an upper limit of the computational resources, the memory resources and the communication resources, and last the compiler toolchain that maps the workload onto the available hardware resources and schedules the order of the tasks of the workload.
All of these three domains have a tremendous impact on the overall performance of a workload that is executed on the target hardware. Classic development processes, however, keep these three domains often separated until the end of the implementation phase which might be too late for significant changes in either of them. We demonstrate a proof-of-concept of a methodology that uses an (abstract) virtual hardware model of a Coarse-Grained Reconfigurable Architecture (CGRA) hardware accelerator to predict the execution time of a neural network, that performs object-type classification of radar spectrum data accurately down to the transaction level. A key role in this setup plays TVM which we use to transform the high-level algorithmic description to a hardware-aware task graph, that can be simulated on an abstract virtual hardware model. Unlike other approaches that simulate a compiled binary on a detailed hardware model, we use a backend to generate the task graph that is simulated on the virtual system model.
This approach enables algorithm designers to estimate performance accurately for a target system while hardware architects explore the impact of architectural optimizations through an easily adaptable abstract model of the hardware system.
- 2 participants
- 21 minutes



10 Dec 2020
Jared Roesch, OctoML
The TVM Object system is a C-ABI way to do cross language support and has enabled the core of the TVM compiler to be extended and exposed to multiple languages. In this talk we will describe the motivations behind this design and in particular focus on how we have used this feature to increase uniformity between existing languages such as Python and C++ as well as add new language support. In particular we focus on the design of object system and how to use it via the lens of adding Rust support over the last year, extending the compiler and runtime system. This process has largely been a success resulting in high quality Rust bindings which enable new functionality and features which we will discuss.
The TVM Object system is a C-ABI way to do cross language support and has enabled the core of the TVM compiler to be extended and exposed to multiple languages. In this talk we will describe the motivations behind this design and in particular focus on how we have used this feature to increase uniformity between existing languages such as Python and C++ as well as add new language support. In particular we focus on the design of object system and how to use it via the lens of adding Rust support over the last year, extending the compiler and runtime system. This process has largely been a success resulting in high quality Rust bindings which enable new functionality and features which we will discuss.
- 2 participants
- 23 minutes

10 Dec 2020
Xiaoyong Liu, Alibaba
Ansor can automatically generate a much larger search space by utilizing improved cost model, evolutionary search and task scheduler.
In this talk, we will cover the end2end story behind it, including the motivation, the architecture, the solution and the result.
Beside this, we'll discuss how Ansor, as well as TVM, to integrate with our inference solution and the real-life benefit out of the technology.
Ansor can automatically generate a much larger search space by utilizing improved cost model, evolutionary search and task scheduler.
In this talk, we will cover the end2end story behind it, including the motivation, the architecture, the solution and the result.
Beside this, we'll discuss how Ansor, as well as TVM, to integrate with our inference solution and the real-life benefit out of the technology.
- 3 participants
- 20 minutes


10 Dec 2020
Mei Ye and David Marques, AMD
We use TVM to find the best possible implementation of our inference models on AMD's APUs and achieve impressive results. We will show a video demo of a back ground removal application running on a Window 10 laptop featuring AMD's Zen2/Vega APU. TVM solution is twice as fast as DirectML solution and does not have thermal-throttling problem observed using the DirectML solution.
We use TVM to find the best possible implementation of our inference models on AMD's APUs and achieve impressive results. We will show a video demo of a back ground removal application running on a Window 10 laptop featuring AMD's Zen2/Vega APU. TVM solution is twice as fast as DirectML solution and does not have thermal-throttling problem observed using the DirectML solution.
- 2 participants
- 11 minutes

10 Dec 2020
David Aronchik, Microsoft
Machine learning continues its spread across the tech world and is now in use by more than 80% of enterprises world wide. However, with the increased reliance on this technology, the spectre of additional security attack surface areas rises up. Machine learning attacks are a new area of opportunity for adversaries, and require a new way to approach defense. In this talk, we will cover several of the most common ML attacks today and how to defend against them. We will also show how to use a sophisticated, cloud-native pipeline with Kubeflow will to enable organizations to detect, remediate and defend against future attacks.
Machine learning continues its spread across the tech world and is now in use by more than 80% of enterprises world wide. However, with the increased reliance on this technology, the spectre of additional security attack surface areas rises up. Machine learning attacks are a new area of opportunity for adversaries, and require a new way to approach defense. In this talk, we will cover several of the most common ML attacks today and how to defend against them. We will also show how to use a sophisticated, cloud-native pipeline with Kubeflow will to enable organizations to detect, remediate and defend against future attacks.
- 3 participants
- 34 minutes

9 Dec 2020
0:00 - Welcome, Luis Ceze, Co-founder and CEO OctoML
10:49 - Community Update, Tianqi Chen, Co-founder and CTO OctoML
23:12 - TVM Update from AWS, Yida Wang, Senior Scientist, AWS
29:18 - Machine Learning at Arm, Jem Davies, VP, General Manager, and Fellow, Machine Learning Group, Arm
38:00 - TVM Update at AMD, Wilson Yu, Sr. Director, AMD Advanced Technologies Group, AMD
41:03 - TVM Update at SiMa.ai, Kavitha Prasad, VP of Business Development and Systems Applications, SiMa.ai
46:18 - TVM Update at OctoML, Jason Knight, Co-founder and CPO OctoML
52:46 - Q&A
10:49 - Community Update, Tianqi Chen, Co-founder and CTO OctoML
23:12 - TVM Update from AWS, Yida Wang, Senior Scientist, AWS
29:18 - Machine Learning at Arm, Jem Davies, VP, General Manager, and Fellow, Machine Learning Group, Arm
38:00 - TVM Update at AMD, Wilson Yu, Sr. Director, AMD Advanced Technologies Group, AMD
41:03 - TVM Update at SiMa.ai, Kavitha Prasad, VP of Business Development and Systems Applications, SiMa.ai
46:18 - TVM Update at OctoML, Jason Knight, Co-founder and CPO OctoML
52:46 - Q&A
- 9 participants
- 1:04 hours


9 Dec 2020
Joey Chou, Randy Allen, SiMa.ai
Given its ability to accept TensorFlow, Pytorch, MXNet, and ONNX output, TVM is a natural choice as front end for compilers targeting machine learning centric hardware. The intermediate representation (IR or more specifically in this case, Relay IR) is high-level and easy to understand. Being abstract, it is a natural vehicle for performing source-like, machine-independent optimizations. Relay is easy for developers to understand and debug, enabling faster compiler development.
A front end is only one part of a compiler, however; there are also optimization and code generation (i.e. "backend") to consider -- parts that are sensitive to the target architecture and are thereby machine-dependent. The delineation between front end and back end is hazy in many cases, making the demarcation between the two an ill-defined proposition at times (PCC -- the Portable C Compiler, for instance, famously generated code almost as soon as it parsed the input). Backends generally focus on transformations that are tied closely to the actual machine architecture. As such, they need low level details embedded in their representations. These details are unnecessary to front ends and are usually a pain to manipulate and maintain.
SiMa is developing a machine learning accelerator (MLA) composed of a large number of matrix-multiply processors capable of parallel execution with processor interconnections supporting fast data transfer -- a natural target for a TVM-based compiler. Accordingly, SiMa has also developed a TVM-based front end (codenamed the Awesome Front End or AFE) to target the MLA. The MLA shares characteristics with most machine-learning accelerators, and as such, development of the AFE uncovered lessons valuable to many compiler developers. This talk will discuss the general experience of tying a new backend into TVM and some of the pragmatic lessons learned from our endeavor.
Given its ability to accept TensorFlow, Pytorch, MXNet, and ONNX output, TVM is a natural choice as front end for compilers targeting machine learning centric hardware. The intermediate representation (IR or more specifically in this case, Relay IR) is high-level and easy to understand. Being abstract, it is a natural vehicle for performing source-like, machine-independent optimizations. Relay is easy for developers to understand and debug, enabling faster compiler development.
A front end is only one part of a compiler, however; there are also optimization and code generation (i.e. "backend") to consider -- parts that are sensitive to the target architecture and are thereby machine-dependent. The delineation between front end and back end is hazy in many cases, making the demarcation between the two an ill-defined proposition at times (PCC -- the Portable C Compiler, for instance, famously generated code almost as soon as it parsed the input). Backends generally focus on transformations that are tied closely to the actual machine architecture. As such, they need low level details embedded in their representations. These details are unnecessary to front ends and are usually a pain to manipulate and maintain.
SiMa is developing a machine learning accelerator (MLA) composed of a large number of matrix-multiply processors capable of parallel execution with processor interconnections supporting fast data transfer -- a natural target for a TVM-based compiler. Accordingly, SiMa has also developed a TVM-based front end (codenamed the Awesome Front End or AFE) to target the MLA. The MLA shares characteristics with most machine-learning accelerators, and as such, development of the AFE uncovered lessons valuable to many compiler developers. This talk will discuss the general experience of tying a new backend into TVM and some of the pragmatic lessons learned from our endeavor.
- 2 participants
- 6 minutes


9 Dec 2020
Cody Yu, AWS
Recently, more and more deep learning frameworks embrace code generation to generate kernel code during the model compilation to complement the gap between new emerging deep learning operators and hardware platforms. In order to generate high-performance kernels, many auto-tuning methodologies for tensor programs are proposed. Unfortunately, there is no systematic solution to manage and maximize the tuning result utilization. In this talk, we present Lorien, a scale-out auto-tuning system, to significantly improve the tuning throughput, as well as a data model to manage tuning results in a NoSQL database for 1) deployment, 2) cost model training, 3) neural architecture search, and 3) tuning-as-a-service.
In addition, with the sufficient tuning results, we also present a performance cost model trained by the massive tuning data. The cost model directly leverages AutoTVM schedule template parameters as high-level features to free humans from feature engineering to develop cost models for different platforms.
Recently, more and more deep learning frameworks embrace code generation to generate kernel code during the model compilation to complement the gap between new emerging deep learning operators and hardware platforms. In order to generate high-performance kernels, many auto-tuning methodologies for tensor programs are proposed. Unfortunately, there is no systematic solution to manage and maximize the tuning result utilization. In this talk, we present Lorien, a scale-out auto-tuning system, to significantly improve the tuning throughput, as well as a data model to manage tuning results in a NoSQL database for 1) deployment, 2) cost model training, 3) neural architecture search, and 3) tuning-as-a-service.
In addition, with the sufficient tuning results, we also present a performance cost model trained by the massive tuning data. The cost model directly leverages AutoTVM schedule template parameters as high-level features to free humans from feature engineering to develop cost models for different platforms.
- 2 participants
- 27 minutes

9 Dec 2020
0:00 - TVM at AWS, Yida Wang, AWS
10:57 - Dynamic Model Support Work at AWS
23:23 - TVM and Machine Learning Framework Integration, Wei Xiao, AWS
29:45 - Q&A
10:57 - Dynamic Model Support Work at AWS
23:23 - TVM and Machine Learning Framework Integration, Wei Xiao, AWS
29:45 - Q&A
- 5 participants
- 33 minutes


9 Dec 2020
Kerwin Tung, Chuck Pilkington, Dexian Li, ITRI (Industrial Technology Research Institute)
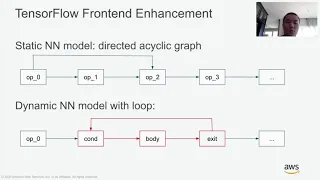
The Synopsys EV7x Vision Processors’ heterogeneous architecture integrates vector DSP, vector FPU, and a neural network accelerator to provide a scalable solution for a wide range of current and emerging artificial intelligence applications. Synopsys is collaborating with ITRI to develop a TVM-based NN compiler to translate the neural network model into codes that can be executed on Synopsys EV7x hardware. In this work, we add Synopsys EV as a new target for TVM. Code generator, runtime support and auto-tuning templates have been updated for EV.
The Synopsys EV7x Vision Processors’ heterogeneous architecture integrates vector DSP, vector FPU, and a neural network accelerator to provide a scalable solution for a wide range of current and emerging artificial intelligence applications. Synopsys is collaborating with ITRI to develop a TVM-based NN compiler to translate the neural network model into codes that can be executed on Synopsys EV7x hardware. In this work, we add Synopsys EV as a new target for TVM. Code generator, runtime support and auto-tuning templates have been updated for EV.
- 1 participant
- 6 minutes
9 Dec 2020
TVM Conf 2020 - Tutorials - An Introduction to TVM
Chris Hoge, OctoML
Chris Hoge, OctoML
- 5 participants
- 1:12 hours

9 Dec 2020
Zhi Chen, Cody Yu - AWS
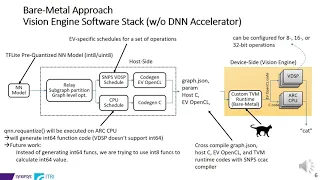
In this tutorial, we demonstrate how you, as a hardware backend provider, can easily leverage the Bring Your Own Codegen (BYOC) framework to integrate the kernel library/compiler/framework of your hardware device to TVM. The most important advantage of leveraging BYOC framework is that all related source files of your devices are self-contained, so the codegen/runtime of your devices are pluggable to the TVM code base. It means that 1) the TVM code base with your codegen would be upstream compatible, and 2) TVM users can choose to enable the codegen/runtime based on their needs. We will also introduce some success stories of integrating third-party library and accelerators into TVM via BYOC. All cases are already upstreamed.
In this tutorial, we demonstrate how you, as a hardware backend provider, can easily leverage the Bring Your Own Codegen (BYOC) framework to integrate the kernel library/compiler/framework of your hardware device to TVM. The most important advantage of leveraging BYOC framework is that all related source files of your devices are self-contained, so the codegen/runtime of your devices are pluggable to the TVM code base. It means that 1) the TVM code base with your codegen would be upstream compatible, and 2) TVM users can choose to enable the codegen/runtime based on their needs. We will also introduce some success stories of integrating third-party library and accelerators into TVM via BYOC. All cases are already upstreamed.
- 4 participants
- 59 minutes

9 Dec 2020
There's a new and updated version of this tutorial. Go check it out here! https://youtu.be/vOqB3VYyvNg
Leandro Nunes, ARM
TVMC is a command line driver for TVM. It aims to offer a unified interface for users, to run common tasks using TVM infrastructure, such as compiling a model; tuning a model and running a model using the graph runtime.
This tutorial intends to present a detailed walkthrough TVMC, from installation to usage, demonstrating its features using a series of small practical projects, to be reproduced by the audience on their own machines.
For developers, this tutorial also will cover an architectural description of TVMC and how to extend it.
Leandro Nunes, ARM
TVMC is a command line driver for TVM. It aims to offer a unified interface for users, to run common tasks using TVM infrastructure, such as compiling a model; tuning a model and running a model using the graph runtime.
This tutorial intends to present a detailed walkthrough TVMC, from installation to usage, demonstrating its features using a series of small practical projects, to be reproduced by the audience on their own machines.
For developers, this tutorial also will cover an architectural description of TVMC and how to extend it.
- 4 participants
- 1:11 hours

9 Dec 2020
Andrew Reusch, OctoML
An overview of recent developments in running TVM on minimal microcontrollers and a tutorial of how to use microTVM in your next microcontroller project.
An overview of recent developments in running TVM on minimal microcontrollers and a tutorial of how to use microTVM in your next microcontroller project.
- 2 participants
- 1:04 hours
9 Dec 2020
Ming-Yu Hung, Ming-Yi Lai, Mediatek
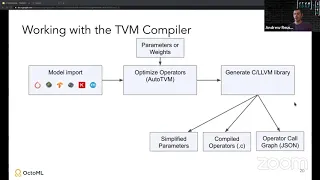
This work adds a codegen flow from TVM Relay to Android NNAPI for more performant mobile machine learning (ML) inferences utilising vendor-specific AI accelerators.
As ML applications evolve, there’s a happening trend that shifts the once cloud-only, centralized inference job to edge, local devices for better responsiveness and privacy protection. With the background, mobile phone chip designers begin incorporating ML-specialized silicons into their product with the aim to provide better support and performance for inferences. However, utilizing the new hardware is not an easy job for phone app developers, as the mobile phone market is highly fragmented with dozens of chip models from various designing companies, each with their own development toolchains. To provide a unified method to access the accelerator, starting from Android 8.1, the mobile platform adds a new library called Neural Networks API (NNAPI) that allows inference jobs to be specified on the graph level with computation details hidden.
This work adds a codegen flow from TVM Relay to Android NNAPI for more performant mobile machine learning (ML) inferences utilising vendor-specific AI accelerators.
As ML applications evolve, there’s a happening trend that shifts the once cloud-only, centralized inference job to edge, local devices for better responsiveness and privacy protection. With the background, mobile phone chip designers begin incorporating ML-specialized silicons into their product with the aim to provide better support and performance for inferences. However, utilizing the new hardware is not an easy job for phone app developers, as the mobile phone market is highly fragmented with dozens of chip models from various designing companies, each with their own development toolchains. To provide a unified method to access the accelerator, starting from Android 8.1, the mobile platform adds a new library called Neural Networks API (NNAPI) that allows inference jobs to be specified on the graph level with computation details hidden.
- 1 participant
- 6 minutes
