►
From YouTube: TVM Conf 2020 - Day 1 - TVM at AWS
Description
0:00 - TVM at AWS, Yida Wang, AWS
10:57 - Dynamic Model Support Work at AWS
23:23 - TVM and Machine Learning Framework Integration, Wei Xiao, AWS
29:45 - Q&A
A
Hello
friends,
my
name
is
I'm
from
aws.
Today,
together
with
some
of
my
colleagues,
we
are
going
to
update
you
the
latest
progress
of
of
our
work
using
tvm
at
aws
in
the
first
10
minutes.
I
will
share
with
you
some
of
our
ongoing
work,
as
well
as
our
thoughts
and
plans
in
the
near
future.
After
that,
my
colleagues
will
introduce
to
you
our
recent
efforts
on
dynamic
model
support
via
tbm
and
framework
integration
of
tvm.
A
A
A
A
We
have
a
mixture
of
good
news
and
bad
news
at
hand.
Firstly,
this
is
a
typical
use
case
that
tbm
can
handle
right.
So
it's
great.
However,
the
life
is
not
that
perfect.
The
model
normally
would
contain
a
few
unfamiliar
or
unseen
operators
that
may
not
run
well
or
even
cannot
run
on
a
given
platform.
A
Then
what
well
good
news
is
that
we
can
tune
these
operators
for
better
performance.
We
have
auto
tvm
and
recently
we
also
have
answer,
and
we
may
have
other
more
advanced
tuning
mechanisms
in
the
future.
Right,
that's
good.
However,
tuning
is
often
time
consuming,
especially
on
h
devices
that
has
very
low
compute
power.
A
A
Here?
Is
our
proposed
solution?
Basically,
we
we
believe
in
data.
Let
me
explain
so
we
would
like
to
have
a
gigantic
database
to
store
the
schedules
of
the
operators
or,
in
some
cases,
sub-graphs
of
all
models
that
we
have
ever
seen
on
all
platforms
that
we
have
ever
tuned
with
such
a
database.
Now,
when
we
get
a
new
request,
namely,
let's
say
executing
a
model
on
a
platform,
we
can
pass
the
model
and
make
the
queries
to
the
database
if
getting
a
hit.
A
A
A
Yep,
so
you
know
ten
years
ago
some
of
my
lab
mats
at
princeton.
They
worked
on
supporting
infra
image
net
infrastructure,
so
we
were
at
that
time
close
to
the
imagenet
team
now,
so
I
have
heard
enough
stories
from
them
about
the
big
data
magic,
which
is
like
the
big
data,
would
lead
to
amazing
results
on
the
same
algorithm
where
small
data
could
not.
So
you
know
the
same
thing
happens
here
in
our
preliminary
experiments.
A
Later
today,
my
colleague
cody
will
talk
about
the
construction
of
the
database
and
the
cost
model
in
more
detail.
So
we
call
this
ongoing
project
lauren.
Okay,
let
me
continue
so
in
addition
to
the
immediate
result:
immediate
solution
of
the
cause
of
the
cross
model.
On
the
other
hand,
in
the
background,
we
will
kick
off
a
tuner
to
tune
the
compute
on
the
given
hardware.
Again,
the
tuner.
The
tuning
techniques
is
orthogonal.
Here
we
can
use
any
tuner.
The
tuned
result
will
be
stored
back
into
the
database
more
advanced.
A
We
can
also
consider
auto
scale
as
auto
scaling
and
auto
quantization
and
point
request
receiving
a
request,
especially
for
model
running
for
model
running
on
edge
devices
which
prefer
later
lighter
computations
next,
and
let
me
switch
the
focus
from
inference
to
training.
We
have
been
talking
about
model
inference
in
tvm
community
for
three
years
how
about
compiler
based
model
training?
A
We
know
that
our
xla
is
such
a
solution,
especially
you
know
a
solution
to
tpu,
and
I
think
people
in
the
tbm
community
must
have
also
been
talking
thinking
about
this
for
quite
a
while
right.
I
don't
think
the
extension
is
trivial
and
I'm
sure
you
would
agree
here.
I
would
like
to
share
with
you
some
known
unknowns
that
we
summarized
first
in
training
all
of
a
sudden.
We
have
many
more
operators
to
worry
about,
so
how
to
write
them
or
say
how
to
generate
auto-generate.
Them
is
a
question
to
answer.
A
Lastly,
large
model
training
requires
a
number
of
techniques
we
barely
didn't
visit
in
tbm,
yet
including
distributed
training.
That
is
how
to
partition
the
model
and
the
data,
and
also
the
data
to
parallelize
a
number
of
devices
and
also
memory
optimization,
something
like
the
trade-off
between
storage,
communication,
bandwidth
and
computation
power
right.
So
we
need
to
consider
this
because
the
model
may
be
too
large
to
fit
into
the
host
memory
of
the
device,
and
another
interesting
aspect
is
to
consider
the
the
sparsity
you
know
here.
A
You
know
in
this
case
the
sparsity
is
used
to
manipulate
and
regularize
the
training
of
gigantic
models
like
gtp
gpd3.
So
these
things
are
not
new
people
have
been
thinking
about
it
from
one
aspect
or
another.
We
are
working
on
this
on
bringing
them
to
the
tvm
domain.
The
work
is
still
pretty
preliminary
and
we
are
looking
for
collaborations.
A
A
Lastly,
I
want
to
talk
a
bit
about
human
training.
Here
I
mean
training
beginners
to
learn
about
how
to
use
and
develop
in
tbm.
I
have
talked
about
the
same
thing
last
year
and
I
think
it
is
worthwhile
to
bring
it
back
again.
We
have
been
frustrated
by
the
difficulty
of
getting
people
on
board
for
years,
so
we
would
like
to
provide
a
systematic
pro
tutorial
to
make
a
training
the
learning
curve.
Let's
stick
in
our
team,
we
have
a
successful
story
before
this
d2l
book.
A
Written
by
my
colleagues,
they
received
positive
feedback
from
readers
and
have
been
adopted
by
many
universities.
So
a
straightforward
idea
is
to
extend
this
work
from
dive
into
deep
learning
to
dive
into
deep
learning
compiler
so
and
we
are
doing
so
using
tbm
as
a
compiler.
We
brought
the
entire
pipeline
and
infrastructure
from
d2l
to
here.
We
aim
at
putting
together
a
systematic
tutorial
for
beginners
who
want
to
use
tvm.
We
started
this
effort
last
year
and
but
still
in
halfway,
so
the
major
part
of
the
operators
are
done.
A
I
mean
in
operators
like
mathematical
convolution,
pulling
they
are
defined
and
optimized
on
both
cpus
and
gpus.
In
this
tutorial,
however,
we
are
now
short
of
hands
of
extending
it
to
the
graph
level
compilation.
You
know
the
relay
stuff
actually,
so
things
like
how
to
use
relay
to
represent
a
neural
network,
how
to
run
relay
passes
like
constant
folding
operator,
fusion
data
layer,
transformation
so
and
so
forth,
and
in
addition-
and
there
may
be
some
interesting
recent
work
to
be
added
into
this
tutorial.
A
A
B
B
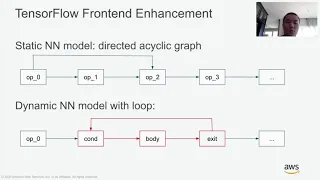
However,
when
we
talk
about
object,
detection
models
from
tensorflow
and
pytorch,
they
both
have
dynamic
structures
such
as
control
flow,
tensor
array
and
dynamic
shape
operators.
They
require
different
handlings
in
three
major
parts.
The
first
is
a
front-end
parser
needs
to
handle
these
dynamic
structures.
The
second
is,
we
need
to
implement
dynamic
operator
in
relay
and
topi.
B
B
B
B
This
is
the
major
work
for
the
front-end
loop
handling.
The
next
part
is
for
the
front-end
is
the
tensor
array.
Optimization
tensor
array
is
a
widely
used
data
structure
in
these
dynamic
models
and
basically
it's
a
list
of
tensors.
Theoretically,
the
tensor
in
a
tensor
array
can
have
arbitrarily
data
type
data
shape
and
even
dynamic
tensor
rank.
However,
the
dynamic
tensor
rank
is
very
rare
in
deep
planning
models,
so
this
makes
opportunity
for
us
to
further
optimization.
B
These
are
the
two
major
parts
for
the
front-end
enhancement
to
support
dynamic
models.
The
next
I'll
take
a
non-maximum
suppression
as
an
example
to
see
how
do
we
support
such
a
complicated,
dynamic
operators
in
relay
and
topi?
So
non-maximum
suppression
has
the
number
of
bounding
boxes
as
a
variable
and
to
compute
the
number
of
bounding
boxes.
It's
almost
to
reduce
the
whole
computation
of
nms
and
it's
not
feasible.
B
B
We
have
already
gets
the
actual
number
of
bounding
boxes.
At
this
point,
we
can
remove
or
pull
the
unselected
boxes
with
operation
strided
slice.
This
is
how
we
handle
the
fir
the
dynamic
operator,
part
of
our
work,
so
in
the
next
hytron
will
present
the
backend
runtime
system
to
support
dynamic
models.
C
C
C
The
kernel
library,
is
higher
dependent
and
is
highly
optimized
for
the
specific
hardware,
and
later
these
two
objects
will
be
loaded
into
the
lightweight
virtual
machine.
The
which
is
the
runtime,
so
interprets
these
instructions
and
execute
the
models.
Invoke
the
kernels
just
to
give
a
little
bit
more
details
about
the
this
project.
We
introduced
any
dimension
that
represents
an
unknown
dimension
at
a
compilation
time.
C
So
next,
I
will
talk
about
like
a
new
things,
which
is
called
the
operator
strategy.
So
this
is
focus
on
how
to
an
operator
defining
relay
is
lower
to
your
kernel
implementation.
So
now
we
are
having
like
more
and
more
kernel
implementations
in
the
tvm
and
also
as
as
well
as
the
third
party
library.
C
So
the
operator
strategy
provides
a
mechanism
or
an
interface
that
allows
the
developer
to
program
the
kernel,
implementation
selection
process,
and
they
can
also
help
the
the
compiler
to
select
the
best
kernel
implementation,
whichever
possible
so
take
the
com2d
operator
as
an
example.
So,
in
the
first
step
you
are
based
on
the
target
you
compile
to,
it
will
invoke
the
corresponding
shape
strategy
function.
So
in
this
case,
if
we
consider
like
this
cuda
is
our
target.
So
we
invoke
the
cuda
strategy
function
and
further
based
on
the
off-road
attributes.
C
If
there's
pos,
if
it's
exists
so
and
then
check
out
like
what's
the
latency
for
each
implementation
and
then
use
the
one
that
gives
the
lowest
latency
to
compile
as
this
kernel,
so
lastly,
let's
look
at
the
evaluation
results
of
the
objective
detection
models
on
the
on
an
instance.
So
we
evaluate
the
object
detection
model
on
the
ec2
m6g
8x
large
instance.
So
this
is
an
arm
based
instant
that
has
32
arm
cores.
C
So
we
use
the
docker
image
provided
by
arm
that
comes
with
the
tensorflow
and
python
pre
pre-installed,
and
we
also
use
the
tvm
to
compile
the
models
from
tensorflow
and
pytorch
and
then
optimize
that
and
compare
the
performance
to
the
native
frameworks.
So
we
can
see
that
tvm
is
slightly
faster
than
the
tensorflow
on
the
ssd
mobile
net
model,
and
now
it
can
also
1.4
x
faster
than
for
the
faster
rcn
resnet
50
model
than
the
tensorflow.
C
The
python
model,
because
the
version
in
this
docker
container
is
too
too
low.
So
it
cannot
execute
the
first
rcn
resin
model.
However,
the
tvm
can
still
compile
and
run
that,
but
due
to
like
there's
too
many
dynamic
shaped
up
operators
in
the
fast
rcm
from
the
pi
touch,
so
the
latency
society
is
higher
than
the
what
we
get
from
the
tensorflow.
So
we'll
continue
working
on
to
improve
the
performance
of
the
python
for
to
support
the
python
models.
D
D
D
These
numbers
we
obtained
on
october
2020
the
numbers-
are
increasing
all
the
time.
So
how
do
we
solve
this
problem?
If
we
try
to
in
add
support
for
each
operator
it's
going
to
take
a
long
time,
so
the
solution
we
came
up
with
was
to
do
a
partial,
compile
for
a
model,
so
I'm
going
to
use
an
example
here.
This
is
the
alpha
post
model
from
the
gluon
cv
model
zoom.
D
In
this
model
we
figured
out
that
we
can
have
these
sub
graphs
from
0
to
4.
These
are
the
blue
circles
in
the
picture
that
are
completely
supported
by
tvm,
and
then
we
have
these
orange
circles,
which
are
operators
not
supported
by
tvm.
So
by
having
a
runtime.
That
is
a
combination
of
the
framework
runtime
and
the
tvm
runtime.
We
are
able
to
do
inference
on
such
models
and
this
work
has
been
released
in
the
amazon
sagemaker
new
compiler
service,
as
well
as
the
sagemaker
hosting
service.
D
So
in
this
slide,
I
will
show
you
a
little
bit
more
details
about
the
compiled
partially
compiled
model.
So
with
this
simple
cat
and
the
grab
command,
you
are
able
to
see
this
json
file
at
the
bottom.
You'll
see
that
there
are
five
of
these
operators,
which
are
called
tvm
subgraph
up.
These
are
the
blue
circles.
D
D
And
on
the
gpu
instance,
it
has
a
speed
up
of
1.23.
Now
I'm
going
to
show
you
a
few
more
models
in
the
tensorflow
and
pytorch
framework,
as
well
as
the
mxnet
framework.
So
we
have
resnet
model
here,
inception
and
yellow
and
we
have
these
different
numbers
of
speedups
and
we
have
cpu
and
gpu
instances.
D
D
D
D
D
E
A
Question
so
this
is
ida
from
aws.
Maybe
I
can
speak
a
bit
about
that.
So
the
interesting
little
report
was
that
the
video
was
recorded
before
reinvent,
but
after
that
you
know
that
aws
announced
a
new
hard
work
called
aws
training.
So
it's
a
special
purpose,
hardware
for
large
scale
training
and
we
are
actually
working
on
the
compilation
chain
of
it
and
you
know,
as
like
aws
influence
yeah.
We
would
continue
utilize,
the
whatever
feature
that
tbm
would
provide.
A
We
would
definitely
reuse
the
things
instead
of
reinventing
them
and
then
you
know
it's
a
special
purpose
accelerator.
There
are
a
lot
of
interesting
challenges
inside
that's
something
that
we
are
interested
in
working
on,
and
you
know
we
would
keep
updates
to
the
community
and
you
know
to
find
support
and
maybe
also
find
collaborations
whenever
it's
possible.
Okay
and
the
other
thing
I
think
you
know
in
terms
of
the
new
hardware-
things
that
I
would
like
to
point
out
is
like
I
think
many
speakers
already
mentioned.
A
It's
about
potentialization
so,
broadly
speaking,
is
to
try
to
utilize
those
customized
compute
units
in
an
efficient
way,
so
in
general
recorded
tensorization
right.
So,
whether
it's
it's
this
historical
array
or
just
like
that
in
so-called
nvidia
gpu,
these
kind
of
things
that
would
be
interesting
for
the
entire
community
to
think
about
a
generic
way
to
utilize
those
spatial
purpose,
computer
units
yep.
That's
it
thanks.
E
Great
thank
you
very
much,
shida
and
and-
and
I
think
the
rest
of
the
community
is
extremely
excited
about.
You
know
further
developments
on
training,
further
developments
on
supporting
tensorization
in
the
next
year
and
I'm
sure
that
in
the
next
conference,
you'll
hear
a
lot
more
about
some
some
early
achievements
in
those
in
both
fronts.
I'll
take.