►
From YouTube: Persistent L2ARC by George Amanakis
Description
From the 2020 OpenZFS Developer Summit
slides: https://drive.google.com/file/d/1N4drzhggcbgVZ36y5HyNdDuOXTsye1N_/view?usp=sharing
Details: https://openzfs.org/wiki/OpenZFS_Developer_Summit_2020
A
B
A
Implementation,
so
what
happens
you
can
see
schematic
at
the
bottom
of
the
screen
is
that
we
write
buffers
and
when
the
device
is
full,
it
will
start
evicting
previously
written
buffers
in
order
to
make
space
to
write
new
ones.
So
the
important
thing
to
realize
here
is
that
it's
implementation
if
the
device
is
full
okay.
A
So
how
did
we
make
the
ultra
persistent?
We
first
of
all
to
enable
the
persistence
means
that
we
need
to
restore
the
header
entries
of
the
buffers
that
reside
in
l2r
in
vr
and
to
do
this
we
implemented
an
on-disk
structure
called
l2
arc
lock
blocks.
So
this
is
actually
metadata
that
contain
the
buffer
header
entries.
You
can
see
there's
structure
down
here,
so
it
has
a
magic
value
for
them
for
determining
indians.
A
A
A
A
So,
okay,
we
have
this
own
device
structure,
but
how
do
we
keep
track
of
those
lock
blocks?
I
mentioned
earlier
that
each
block
contains
a
pointer
to
the
previous,
so
that's
how
we
can
keep
track
of
them
by
information.
I
mean
properties
of
the
block
like
it's
offset
on
the
device,
the
starting
offset
of
the
payload.
The
allocated.
C
A
A
So
we
for
performance
reasons.
We
don't
actually
have
a
single
chain
of
log
blocks,
but
we
have
two
interleaved
chains
and
you
can
see
the
the
schematic
at
the
top
of
the
slide.
The
concept
here
is
that,
while
we
are
issuing
a
synchronous
rate
to
read
one
lot
block,
we
also
issue
an
asynchronous
ring
to
read
immediately
a
prior
one.
A
So
while
we're
decompressing
and
restoring
the
current
plug,
we
spent
the
time
to
read
the
previous
one
and
in
terms
of
performance,
you
can
see
that
in
a
consumer
create
satellite
ssd
with
a
kind
of
fold
by
nowadays
standards,
zn
processor,
restoring
the
contents
of
a
64
giga
python
to
our
device.
That
corresponds
to
about
100
gigabytes
in
of
buffers
in
terms
of
logical
size.
It
takes
about
three
seconds
if
we
had
just
one
chain
of
lock
blocks
and
it
takes
about
two
seconds.
A
If
we
have
the
current
design,
so
we
have
a
performance
gain
of
about
thirty
percent.
It
is
also
worth
noting
here
that
the
l2
arc
is
done
asynchronously
with
respect
to
pulling
port.
So
we
don't
actually
wait
for
the
rebuild
to
finish
to
finish
importing
the
pool,
and
it
is
also
worth
noting
that
we
don't
write
buffers
to
the
cache
device
until
the
rebuild
has
been
completed.
A
A
A
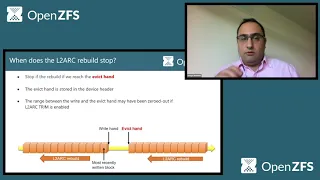
Can
see
that
the
most
recently
written
log
block
is
this
one,
and
you
can
also
see
that
zfs
has
evicted
ahead
some
space
in
order
to
accommodate
upcoming
raids,
and
this
is
shown
by
the
effect
hand,
so
the
victim
is
actually
they
often
until
which,
with
effective
buffers,
in
order
to
make
space
for
the
new
ones.
When
we
start
rebuilding
the
health
work,
we
go
the
opposite
direction
than
what
we
read.
A
A
A
This
means
that
log
blocks
so
metadata
are
still
actually
written
in
the
device,
but
once
the
pool
is
imported,
the
l2r
buffers
won't
be
restored
and
the
other
actually
disables
completely
the
writing
of
lock
blocks
on
the
cache
device,
and
this
may
be
beneficial
for
small
devices.
This
one
defaults
to
one
gigabyte.
So
if
the
device
is
smaller
than
one
gigabyte,
our
l2
resistance
is
disabled
by
default.
A
A
We
have
also
taught
zdb
to
be
able
to
read
those
own
device
structures,
so
you
can
see
the
device
header.
Here
an
example.
You
can
see
with
yellow
the
offsets
of
two
most
recently
written
block
blocks.
We
can
also
see
information
like
their
count,
so
28
of
them
their
allocated
size
and
you
can
also
inspect
the
content
of
the
lock
blocks.
For
example,
you
can
see
here
lb1.
This
is
the
first
one,
the
most
recently
written
one.
You
can
see
it's
compression
algorithm.
It's
check
some
algorithm.
A
You
can
also
inspect
the
buffer
header
entries
for
each
of
its
of
its
buffer,
so
things
like
the
dpa
allocated
size,
the
earth,
transaction
compression
levels,
buffer
content,
type
and
so
on.
In
terms
of
our
arc
stats,
we
implemented
two
sets
of
them.
One
set
is
updated
online,
as
writes
are
happening
to
the
cache
device,
and
you
can
see
information
like
the
number
of
the
log
blocks,
their
allocated
size
and
the
other
set.
A
A
A
So
unfortunately
I
don't
have
one
of
those.
But
yes,
so
in
personal
testing,
up
to
128
gigabytes
jan
asks.
How
does
network
persistent
impact
put
times?
Does
the
pool
import
block
until
the
l-torque
has
been
repopulated?
No,
it
doesn't
block
it.
So
it
happens.
The
network
rebuild
has
is
happening
asynchronous
in
the
background,
and
this
does
not
impact
importing
importing
of
pool
asks.
Are
there
any
operations
that
rebuild
blocks
until
it
finishes?
No,
it
doesn't
so
it
is.
A
A
A
A
C
A
C
The
log
device
is
kind
of
totally
it's
also
an
auxiliary
device.
It's
also
a
way
to
like
get
better
performance
by
using
faster
hardware,
but
you
know
because
the
l
twerk
isn't
required,
for
you
know
the
integrity
of
the
pool
we
didn't
bother
with
monday
mirroring
for
that,
but
yeah
for
the
log
you
would.
You
would
still
want
to
have
mirroring.
D
Yeah,
I
was
going
to
add
it.
It
might,
you
know
originally,
because
we
didn't
have
persistent
l2
arc.
It
didn't
make
a
lot
of
sense
to
actually
build
any
any
redundancy
now
with
persistent
ltr.
That
may
change
for
certain
people,
and
it
may
be
a
feature
that
you
may
want
is
the
ability
to
have
some
redundancy
for
your
l2r
just
because
you
want
to
be
able
to,
like.
You
know,
preserve
that
in
the
event
that
something
fails
and
you
you
know
want
to
like
reboot
or
something.
E
A
C
A
And
shas
is
the
one
who
did
the
original
work,
then
it
was
later
reported
on
to
cfs
and
linux
by
yushon,
and
I
actually
picked
up
on
the
code
that
jorgen
had
lying
around
in
the
cougar
quest,
so
I'm
very
grateful
for
them
and
also
for
everybody
who
provided
feedback
reviewed
code.
I've
listed
some
of
the
people
here
only
know.
I
think
it
took
me
about
five
months
to
complete
this
work
and
get
it
merged,
and
the
support
of
the
open
cfs
community
had
been
has
been
great.
A
So
christian
is
asking:
is
there
code
using
the
cio
pipeline?
Yes,
I
think
I
guess
I'm
pretty
sure
it
does
so.
The
rights
happening
are
through
the
cio
backline
yeah
holding
the
receiver
in
the
twerk.
You
get
all
performance
gains,
so
we're
not
actually
receiving
the
outward.
We
just
go
and
read
and
restore
and
mark
the
metadata,
the
buffer
header
entries
of
the
buffers
that
lie
there.
A
A
It's
it's
that
time
when
it
will
do
the
checksumming
and
decide
if
the
copy
that
is
in
the
l2
arc
is
filed
or
not.
So
this
doesn't
happen
for
the
buffer
itself.
The
checksum
control
doesn't
happen
at
the
time
of
the
rebuild
at
the
time
of
the
rebuild.
All
we
care
about
is
if
the
log
blocks
are
valid
so
as
to
go
ahead
and
restore.
A
A
So
in
terms
of
this,
if
say,
if
the
contents
of
the
disk
change-
but
there
is
still
information
on
network
that
is
not
up
to
date-
can
cfs
will
become
aware
of
it
if
this
buffers
or
if
these
blocks
are
actually
red.
So
it's
then,
when
zfs
will
see
that
okay,
we
have
information
in
the
eldwart
that
doesn't
match
to
check
some
much
what's
on
disk,
so
it
will
go
on
and
fetch
from
disk,
not
from
the
outwork.
A
A
A
When,
when
that
area
of
the
arc
is
scanned,
it's
it's
that's
when
the
l
truck
would
get
updated.
If,
again,
if
the
points
on
the
disks
are
updated,
it
doesn't
mean
that
the
console
benchmark
will
be
automatically
updated.
If
there
is
a
discrepancy,
a
zfs
will
opt
to
read
from
this
and
not
from
the
l2r
company.
B
C
Thank
you
awesome
thanks,
george,
and
thanks
to
whoever
asked
that
last
question.
I
think
that's
a
definitely
interesting
question,
especially
because
I
think
we
try
to
make
it
so
that,
in
the
normal
case,
where
there's
no
hardware
problems,
we
we
would
like
for
zfs
to
not
be
relying
on
the
checksums
in
order
to
get
correct.
C
Behavior
like
the
checksum
is
just
supposed
to
be
there
to
check
that
the
hardware
is
doing
the
right
thing,
so
that
would
be
an
interesting
area
to
do
some
more
investigation
and
enhance
the
outwork
so
that
we
could
know
for
sure
that
the
data
that
we're
reading
should
be
the
right
data.
Assuming
that
the
hardware
is
okay,.