►
From YouTube: Send/Receive Performance Enhancements by Matt Ahrens
Description
From the 2020 OpenZFS Developer Summit
slides: https://docs.google.com/presentation/d/1HuKHawQbuetqpbwp4wmfm6Ozj-WYJpPa6QAxgDxLsgk/edit?usp=sharing
Details: https://openzfs.org/wiki/OpenZFS_Developer_Summit_2020
A
We
can
get
really
good
throughput,
so
more
than
10
gigabits
per
second
on
both
for
both
send
and
receive.
So
I
don't
know
why
am
I
even
here?
Well,
it
turns
out
that's
only
true.
If
you're
using
large
blocks,
if
you're
using
smaller
block
sizes,
then
you
get
maybe
a
third
of
that
performance,
so
you're
nowhere
near
saturating
your
network,
so
why?
Why
do
we
care
about
this?
So
I
work
at
delfix
in
our
product.
A
Customers
have
those
up
to
about
five
gigabits
per
second
and
we
would
like
to
be
able
to
saturate
that,
but
we,
but
we
can't
and
the
other
the
other
wrinkle
here
is
that
a
lot
of
the
time
the
majority
of
the
data
is
just
in
one
file
system.
So
we
can't
take
advantage
of
like
running
multiple
sends
in
parallel.
A
A
So
our
goal
my
goal
for
this
project
was,
you
know
we
want
to
be
able
to
do
a
zfsn
pipe
that
over
the
network,
type
that
into
a
zfs
receive
on
the
other
system,
and
ideally,
we
want
to
like
saturate
either
the
network
or
the
disk,
like
some
piece
of
hardware,
should
be
going
full
tilt
and
we
shouldn't
be
waiting
for
the
software
in
the
cpu.
But
unfortunately
that
is
the
case
today.
A
So
I'm
going
to
be
talking
a
bit
about
like
how
we
did
this
and
then
I'll.
Tell
you
about
a
few
of
the
improvements
that
I
made.
I
had
to
try
like
a
lot
of
different
things,
so
there's
a
lot
of
iteration
and
so
when,
when
I'm
iterating,
basically
what
I'm
doing
is
like
looking
at
a
flame
graph,
seeing
what's
using
cpu
going
and
trying
to
find
out.
Is
this
actually
important?
A
If
I
could
get
rid
of
this,
this
cost
like
it
seems
like
there's
this
cost
in
this
particular
code
path.
If
I
could
get
rid
of
that,
would
that
how
much
would
that
improve,
send
and
receive?
And
that's
a
different
question
than
actually
like
fixing
it.
So,
to
give
an
example
like
every
time
you
create
you
instantiate
a
a
debuff,
you
might
be.
A
We
need
to
allocate
some
memory
and
we
need
to
do
some
space
accounting
to
say
like
okay,
now
there's
this
much
amount
of
memory
that
zfs
is
consuming
for
its
internal
data
structures,
there's
probably
like
locks
associated
with
that.
So
you
know.
Maybe
I
see
the
locking
is
taking
a
long
time
rather
than
like
breaking
up
the
lock
or
doing
something
sophisticated.
I
was
just
like
okay
delete
that
code
or
comment
out
that
code
and
see
if
we
get
better
performance.
If
we
do,
then
I
can
go
back
and
implement
a
real
solution.
A
A
So
then
I
could
come
back
towards
the
end
of
the
project
and
evaluate
like
which
of
these
will
give
us
the
most
the
most
impact
to
performance
for
the
least
amount
of
effort
right.
So
the
test
setup
that
I
used
was
not
the
full-blown
like
product
with
databases,
and
you
know,
networks
for
the
cloud.
But
I
I
wanted
to
look
at
the
performance
of
send
and
then
receive
separately
because
you
know
sending
receive.
Obviously
they
go
together
like
peanut
butter
and
jelly.
A
You
almost
can't
have
one
without
the
other,
but
under
the
hood
they're
doing
almost
totally
different
things
right
because
send
is
getting
data
receive,
is
taking
the
data
in
and
then
writing
it
out.
The
code
paths
are
very
different,
so
things
that
might
improve
one,
don't
necessarily
improve
the
other,
but
I
did
want
to
capture
the
costs
associated
with
the
pipe.
A
So
I
didn't
just
use
zfs
send
greater
than
devnull,
which
is
even
faster,
but
I
wanted
to
capture
the
performance
of
sending
out
to
the
pipe,
because
we,
due
to
some
previous
investigations,
we
suspected
that
there
might
be
problems
there
and
I
use
dd
quick
side
note.
There
are
not
a
lot
of
utilities,
standard,
unix
utilities
that
can
produce
or
consume
a
pipe
at
more
than
a
gigabyte
per
second,
I
I
tried
using
pv
the
pipe
viewer
initially
and
that
will
instantly
become
the
bottleneck
of
any
pipe.
A
So
you
don't
don't
do
that
for
the
test
setup
I
we
actually
didn't.
I
didn't
use
compression
and
I
didn't
use
record
size
ak.
Instead,
I
set
the
record
size
to
match
the
compressed
block
size
that
we
typically
see
of
around
4k,
and
I
just
have
100
gigabytes
of
data.
I,
when
you
so
when
you're
doing
zfs
send
basically
what
that's
doing
is
like
issuing
a
whole
bunch
of
reads
to
disk,
and
then
you
know,
they're
completing
and
then
we're
generating
the
sense
stream.
A
When
we
have
a
lot
of
ios
a
lot
of
reads
pending
at
the
in
the
zfs
vdf
queue
layer,
then
zfs
is
able
to
do
aggregation
so
it
when
we're
going
to
issue
an
io.
If
we
see
oh
there's,
actually
several
adjacent.
I
os
to
this
that
are
all
also
reads.
Then
zfs
will
issue
one
big
read
to
the
disk
and
then
copy
out
the
data
wherever
it
needs
to
go.
A
The
problem
with
this
is
that
it
can
lead
to
really
inconsistent
performance,
because
whether
you
get
that
I
o
aggregation
or
not
depends
on
it
depends
on
like
the
timing
of
everything,
that's
happening,
so
you
know
you
might
get
into
a
mode
where
it's
like
we're.
Just
the
eyes
are
flying
out
really
fast
and
we're
not
getting
any
aggregation
and
we,
you
might
get
into
a
mode
where
things
are
getting
queued
and
also
depends
on
the
layout
of
the
the
data
on
disk.
A
So
I
disabled
this
read
io
aggregation
for
my
test
so
that
we
get
a
consistent
per
I
o
cost,
so
every
4k
we're
actually
sending
down
through
the
block
device
driver
down
to
the
actual
hardware.
This
also
simulates
what
you
would
get
in
kind
of
a
worst
case
scenario,
where
the
files
are
spread
totally
evenly
across
your
disk
and
super
fragmented.
A
A
This
is
a
new
feature
in
the
linux
kernel,
5.0
and
in
a
bunch
of
they
said
like
for
security
reasons,
we're
going
to
whenever
you
allocate
a
page
we're
going
to
zero
it
out
that
these
two
pretty
poor
performance
for
zfs
when
you're
at
high
throughputs,
and
so
we
we've
actually
disabled
this
in
our
product
and
and
you'd-
want
to
disable
it
for
high
throughput
workloads
and
all
right.
So,
let's
get
started
with
our
investigation.
So,
let's
start
with
zfs
send
sort
of
the
flame
graph.
A
So
this
is
a
flame
graph.
What
it's
telling
us
is
kind
of
on
you.
You
have
a
bunch
of
these
bricks
right
so,
like
here's,
a
stack
of
bricks
and
the
the
stack
of
bricks
is
telling
us
a
stack
trace.
So,
for
example,
here,
like
zio,
execute
called
zio
v
dev
I
o
done,
which
is
called
v
q.
I
o
whatever
and
the
width
of
each
brick,
is
how
long
that
function
was
on
cpu
or
that
that
function
or
this
colles
were
on
cpu.
A
A
A
Most
of
the
cpu
that
is
being
used
is
by
these
zio
threads
and
there's
a
whole
bunch
of
these
xero
threads,
at
least
as
many
as
there
are
cpus,
so
at
least
in
theory.
If
these
threads
need
to
do
more
work,
then
they
should
be
able
to
consume
the
idle
cpu,
and
so
these
threads
shouldn't
be
the
bottleneck,
and
then
let's
look
over
here,
so
we
have
the
main
zfs
thread.
So
this
is
like
the
thread
that's
running
from
userland,
it's
outputting
data
to
your
pipe
and
it's
on
cpu
73
percent
of
the
time.
A
So
each
of
these
for
each
of
these
threads,
where
there's
just
one
thread,
it
can
only
be
on
one
cpu
at
most.
So
the
way
that
we
read
this
is,
for
example,
we
can
look
at
this
function
here,
our
header
alec.
It
says
it's
on
cpu
1.7
percent
of
the
time,
so
we
have
to
multiply
that
by
our
eight
number
of
cpus
to
tell
us
that
this
function
is
on
c
on
the
one
cpu
that
I
could
be
on
for
13
of
the
time.
A
A
A
So
this
traverse
thread
is
walking
the
tree
of
blocks
and
figuring
out
what
blocks
we
need
to
send
for
a
full
send.
That's
just
all
of
the
blocks
that
are
part
of
the
file
system
and
it's
outputting
the
block
pointers
that
we
need
to
send.
So
it's
just
the
block
pointers.
We
don't
actually
have
the
data
yet,
but
it's
telling
us
which
blocks
we're
going
to
need
to
retrieve
from
disk.
A
A
So
the
prefetch
thread
is
passing
on
this
exact
same
list
of
block
pointers
that
we
need
to
send
to
the
main
thread.
So
the
main
thread
is
going
to
now
issue
a
real
read
to
the
arc,
which
hopefully
it's
already
cached
and
we're
just
getting
the
cached
data,
and
then
it's
going
to
output
the
data
to
the
pipe
which
is
going
to
be
consumed
by
dd.
A
A
Some
cpu
in
the
main
thread,
probably
wouldn't
help
with
the
prefetch
thread,
but
the
other
thing-
oh,
I
should
also
mention
so
we're
doing
all
these
arc
reads:
we're
getting
all
the
data
into
the
arc
cache
eventually
that
data
is
gonna,
have
to
be
evicted.
So
there's
another
thread:
the
archivic
thread,
which
we
also
saw
on
the
flame
graph
over
here,
which
is
going
to
have
to
remove
that
data
from
the
arc
to
make
room
for
the
new
the
new
blocks
that
we're
reading
in
all
right,
so
pause
for
just
a
sec.
A
What's
so
special
about
this
workload,
so
we
already
mentioned
that
we're
using
small
record
size
or
small.
We
have
small
compressed
block
sizes.
The
second
big
thing
is
that
this
is
single
threaded.
I
know
that
there's
a
lot
of
threads
on
here,
but
because
every
block
needs
to
be
processed
by
every
one
of
these
single
threads,
so
any
one
of
these
threads
can
become
a
bottleneck.
A
A
A
Those
subsystems
are
are
pretty
scalable
but
they're
relatively
heavyweight.
There's
relatively
high
latency
for
each.
I
o.
You
can
get
really
good
throughput
from
zfs
if
you
have
a
lot
of
threads
hitting
it
at
the
same
time,
but
it's
not
great
for
single
threaded
throughput-
and
this
is
true
not
just
for
sender
receive,
but
if
you're
just
doing
like
a
single
dd
to
read
or
to
write,
you're
you're
going
to
see
the
same
kind
of
curve
relative
to
the
to
the
record
size
property
here.
A
A
So
this
is
what
we
have
now
and
how
can
we
fix
it?
So
the
change
that
I
made
was
to
change
this
prefetch
thread
into
what
I
now
call
the
reader
thread
and
what
it's
going
to
do
is
issue
a
zio
read,
so
we're
not
going
to
add
anything
to
the
arc,
we're
just
going
to
go
directly
to
the
zio
layer.
Read
that
block
and
then
pass
the
z
or
initiate
the
read
and
pass
that
zio
on
to
the
next
thread
we're
going
to
check
if
it's
in
the
arc
first.
A
A
So
this
is
a
great
idea:
let's
see
how
it
turned
out
in
practice.
So
usually
what
I
would
do
is
look
at
the
flame
graph
and
see.
Okay.
Did
it
make
kind
of?
Did
I
reduce
that
cpu
time
that
I
was
targeting
in
this
case
we
did
so
allocating
the
abd
the
arc.
Buff.
Sorry
yeah,
allocating
the
abd
is
much.
It
takes
much
less
time
three
percent
of
the
cpu
time
than
we
took
to
allocate
the
arc
header,
which
is
13
and
then
checking
the
zfs
send
throughput.
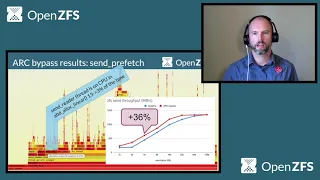
A
A
So
if
we
take
a
look
at
the
send
prefetch
thread,
they
were
seeing
before
where
we
saw
was
using
a
bunch
of
cpu.
What
was
it
doing
when
it
was
not
using
cpu?
So
by
using
off
cpu
flame
graph,
we
see
the
same
stack
of
function
calls,
but
this
time
the
width
is
telling
us
how
long
this
thread
was
blocked,
not
on
cpu,
because
because
we're
waiting
on
the
stack
trace
so
in
this
case
we're
waiting
on
a
condition
variable
in
bq
enqueue
and
what
this
is
doing
is
waiting
for.
A
A
So
the
way
that
we
figure
out
how
important
this
is,
is
we
ignore
this
percentage
here
and
we
instead
look
at
the
number
of
samples
which,
in
this
case
is
the
number
of
microseconds.
So
this
is
telling
us
that
for
two
and
a
half
seconds
2.5
seconds,
we
were
waiting
on
this
stack.
We
divide
that
by
our
sample
time.
So
I
was
running
this
running
this
data
gathering
for
10
seconds,
and
it
tells
me
that
we
were
off
cpu
for
25
of
the
time.
A
We
can
then
look
over
to
the
main
send
thread.
I
wonder
what
it's
on
cpu
bunch
of
time
it
it's
also
off
cpu.
What
was
it
doing
when
it
was
off
cpu?
So
we
spent
a
bunch
of
time,
one
14
of
its
time.
Waiting
for
locks
and
cv
is
associated
with
the
pipe
so
we're
trying
to
output
to
the
pipe
and
we're
having
to
wait
either
on
the
mutex
or
because
the
pipe
is
full.
A
A
What
the
writer
thirties
can
do
is
batch
up
this
in
the
the
stream
into
one
meg
chunks
and
write
those
chunks,
one
meg
at
a
time
to
the
output
stream
to
the
pipe.
So
the
end
result
is
we
have
you
know
one
500th
of
the
number
of
calls
to
the
pipe
potentially
1
500th
of
the
calls
to
the
mutex
and
having
to
potentially
go
to
sleep
and
wake
up.
The
the
dg
thread.
A
A
So
all
we've
done
so
far
is
like
reduce
the
cpu
usage
on
our
sending
system,
but
we,
but
we
can't
actually
get
the
job
done
any
faster.
So,
let's
take
a
look
at
zfs
receive
again,
let's
start
with
the
flame
graph
summarize
it
here
again
it
looks
kind
of
similar
a
bunch
of
idle
time,
a
bunch
of
time
being
in
the
zio
threads,
and
then
we
have
this
receive
writer,
which
is
two
thirds
on
cpu.
That's
just
just
a
single
thread
and
then
the
main
thread
which
is
more
than
half
on
cpu.
A
So,
let's
drill
down
on
that
receive
writer
thread
here
here,
I'm
displaying
the
on
cpu
and
off
cpu
flame
graphs
kind
of
next
to
each
other,
with
their
widths,
proportional
to
the
amount
of
time
that
we
were
spending
on
cpu
and
off
cpu,
and
actually
in
both
the
on
and
off
cpu
cases.
We
are
we
see
that
we've
had
two
big
categories:
one
is
dealing
with
debuffs,
which
is
kind
of
the
the
heart
of
the
dmu.
A
These
are
in-memory
data
structures
that
represent
each
block
and
then
the
other
big
chunk
is
dealing
with
transactions.
So
whenever
we're
making
a
doing
a
write
or
making
a
change,
we
need
to
have
a
dmu
transaction
that
manages
that
right
and
then
off
cpu
we're
basically
dealing
with
waiting
for
locks
associated
with
those
two
data
structures,
all
right.
So
what
are
these
debuffs?
A
A
So
what
we
really
care
about
is
our
data.
In
this
case
databases
don't
make
very
good
pictures.
So
in
this
case
our
data
is
a
jpeg
of
some
pretty
pandemic,
well-dressed
co-workers
and
we
have
the
arc
buff,
which
manages
the
which
keeps
track
of
that
and
the
arc
buff
is
associated
with
the
narc
header
so
at
so
the
main
thread
is
going
to
get
the
data
from
this
from
the
stream
and
put
it
into
this
arc.
Buff
then
we're
going
to
now.
We
need
to
associate
that
with
like
that.
A
Belongs
it
at
this
offset
of
this
file
the
debuff
tracks.
What
is
that
given
offsets
of
files
so
that
we
we
create
this
debuff?
Everything
in
zfs
on
disk
is
a
tree
of
blocks,
so
you
have
like
the
object
points
to
blocks
that
are
called
indirect
blocks,
each
of
which
has
a
bunch
of
block
pointers
that
point
to
maybe
more
indirect
blocks,
which
point
to
eventually
to
the
actual
data.
A
A
We
can
then
we'll
get
rid
of
the
dirty
records
link
the
arc
header
into
the
arc,
cache
hash
table
and
eventually
we're
going
to
evict
that
stuff
to
make
room
for
more
dirty
data
yeah.
I
know
there's
a
lot
of
stuff
if,
if
you
take
anything
away
from
that,
you
should
take
away
that
it's
a
lot,
there's
a
lot
of
things
here
and
there's
a
lot
of
things
pointing
to
other
things
and
each
one
of
these
is
a
relatively
heavy
weight.
A
So,
like
the
d
node,
it's
not
just
like
one
pointer
to
one
leaf
debuff.
It's
like
a
whole
data
structure,
avl
tree
that
points
to
all
of
them.
So
every
time
we're
like
instantiating
the
instantiating,
a
new
leaf
debuff.
We
have
to
associate
it
with
each
of
these,
which
means
like
getting
a
lock
associated
with
it,
adding
to
a
data
structure
which
is
probably
like
o
of
log
n.
So
these
are
relatively
heavy
weight
and
that's
not
even
the
worst
of
it.
A
A
A
A
We
don't
need
to
create
the
arc
buff.
We
don't
need
to
link
into
our
cache
table.
We
don't
need
to
evict
later
on.
So
this
is
great.
The
the
downside
is
this
is
this
is
like
it's
really
slick,
it's
really
lightweight,
but
we
can't
handle
reads
from
data.
That's
lightweight
dirty
because
the
way
that
we
find
like,
if
you're
doing
a
read,
we're
going
to
find
the
debuff
associated
with
that.
If
it's
not
there,
then
we're
going
to
instantiate
it.
There
is
no
debuff
associated
with
this
data.
A
A
We
would
see
that
what's
on
disk,
rather
than
what
was
written
but
not
yet
synced
to
disk.
So
if
you're
wondering
this
is
why
I
removed
the
ddip
receive
code.
I
know
we
talked
about
doing
that,
for
I
think
I
was
proposed
at
this
conference
like
four
or
five
years
ago.
I
finally
got
around
to
doing
it
because
I
didn't
want
to
deal
with
this
so
with
and
now
that's
been
removed,
zfs
receive
doesn't
ever
read
from
the
dirty
data.
A
A
A
What
else
can
we
do?
So,
let's
take
a
look
at
again
in
the
receive
writer
we
saw,
the
other
big
category
of
cpu
usage
was
dealing
with
transactions,
so
every
for
every
block,
in
this
case
every
four
kilobytes
we're
creating
a
new
transaction
and
that's
gonna.
That's
having
like
look
up
the
d
node,
do
a
bunch
of
accounting
make
sure
you
have
enough
space
to
do
it
and
we're
doing
that.
A
Every
single
four
kilobytes
and
what
I
notice
is
that
you
know
if
you
do,
if
you
have
a
big
sense
stream,
it's
probably
mostly
in
big
files,
especially
if
you
have
small
record
size,
the
you
probably
have
a
lot
of
records
there
in
each
file.
So
we
have
a
lot
of
write
operations
that
are
happening
to
the
same
file
and
most
of
these
things
are
finding
the
same
like
finding
the
which
file
we're
writing
to.
Let's
batch
that
up,
so
what
I
did
is
batch
up
contiguous
write
operations.
A
A
A
A
A
A
Although
my
implementation
needed
to
do
an
additional
b
copy
that
cost
ten
percent
still
we're
better
than
we
were
before
at
twenty
percent,
and
I
got
a
two
additional
twelve
percent
import
performance
improvement
on
the
zfs
receive,
but
so
the
way
that
pipes
work
you
each
side,
one
side
reads
and
the
other
side
writes
and
the
side
that's
reading.
It
only
reads
you
can't
like
push
things
back
into
the
pipe.
A
So
this
breaks
things
where
the
sense
zoom
is
followed
by
some
other
piece
of
data,
like
with
z
of
s,
capital,
r,
capital,
r
or
capital.
I
we're
generating
like
a
a
bundle
of
a
whole
bunch
of
different
snapshots,
so
to
really
address
this,
we
probably
need
to
change
the
send
stream
for
send
stream
like
over
the
wire
format.
So
I
didn't
do
that,
but
this
kind
of
proves
out
like
how
much
performance
benefit
we
could
get
if
we
could
make
this
real
all
right.
A
So,
in
conclusion,
this
is
the
baseline,
where
we
were
before
any
of
these
changes,
and
then
here
is
where
we
improved
performance.
We
actually
got
a
pretty
big,
pretty
good
performance
boost,
even
with
the
large
block
sizes,
but
almost
doubling
performance,
87
or
90
percent
up
to
840
and
740
megabytes
per
second.
A
So
where
are
we
at
with
these
changes?
So
the
bypass
bypassing
the
arc
and
the
right
transaction
batching
are
done
and
those
are
in
those
will
be
in
open,
cfs,
2.0.
The
other
changes,
the
batch
output
and
right
trend,
the
batch
output
and
lightweight
write
code
is
basically
done.
I'm
still
working
on
streaming
that
and
then
the
the
batch
input
needs
a
little
bit
more
work.
I
see
we're
running
short
on
time,
so
I
will
skip
the
future
work.
A
You
can
come
to
the
breakout
session
if
you
want
to
hear
more
about
other
crazy
ideas,
but
I
will
go
to
q.
A
all
right,
so
jan
asked
does
zfs
support,
reading
and
writing
tcp
sockets
within
kernel
tls.
So
the
way
that
it
works,
zfs
send
and
receive
are
passed
a
file
descriptor
from
userland,
so
yeah
you
can
attach
that
file
descriptor
to
a.
If
that
can
represent
a
socket.
I
we
I
haven't
done
that
in
practice,
that'd
be
something
really
cool
to
investigate.
A
A
Jan
also
asked:
what's
the
definition
of
idle
cpu,
I'm
not
sure
that
I
understand
that
there
are
different
definitions,
so
maybe
you
can
help
educate
me
on
that.
I
was
looking
at
both
the
flame
graph,
the
flame
graph,
where
I'm
gathering
all
the
stocks
and
not
excluding
the
idle
ones,
and
that
that
lined
up
pretty
well
with
you
know,
toff
or
iosat-x,
something
that
that
just
gives
you
a
summary
of
like
this
percent
cpu
system.
This
percent
was
idle.
A
Someone
asked
what
kind
of
load
this
was
run
with,
so
there
was
no
load
beyond
the
send
or
receive
that.
I
was
testing
and
I
talked
a
little
bit
about
the
test,
setup
and
methodology
here
so
like
when
I'm
talking
about
the
set
performance.
It's
just
like
it's
literally
running
the
cfs
send,
then
the
snapshot
so
we're
doing
a
full
sound,
not
an
incremental
and
then
piping,
that
into
dd,
with
the
block
size
of
one
megabyte.
So
so
dd
is
going
to
be
consuming
it
in
one
big
chunks.
A
Okay,
so
anonymous
is
asking
about
the
the
the
readability
of
the
lib
zfs
send
receive
dot
c
code
file.
This,
I
think,
all
of
these
changes
that
I've
talked
about
here
do
not
touch
lib
zfs.
These
are
all
kernel
changes.
I
did
do
a
bunch
of
cleanup.
That's
in,
like
smaller
minor
commits
that
are
already
in
there
to
the
to
the
kernel,
send
and
receive
code,
but
I
did
not
have
to
touch
the
useless
stuff.
I
was
thankful
to
not
touch
it
because
you
are
correct.