►
Description
Join Andrew Sullivan, Chris Short, and the occasional special guest for an hour designed specifically to help the OpenShift admins out there. Come with your questions, leave with solutions.
A
C
A
A
B
B
B
B
Yeah
all
right
so,
as
the
title
of
this
particular
stream
says
we're
going
to
be
talking
about
disconnected
openshift
today.
This
is
a
topic
that
has
come
up
a
bunch
of
times.
I
know
the
the
government
folks
or
the
the
public
sector,
that's
what
we
call
them
public
sector
folks
have
a
show
where
they've
talked
about
it
before
there's
a
whole
bunch
of
automation
and
all
of
that
other
stuff.
B
So
I
am
less
interested
in
talking
about
or
telling
you
about
disconnected
installs,
because
I
feel
like
that's
something
that's
been
covered
pretty
thoroughly,
although
I
will
do
a
quick
review
of
that.
But
really
what
I
want
to
talk
about
is
disconnected
operator,
lifecycle
manager.
So
that's
something
that
I
feel
like
gets
less
airtime.
It
gets
talked
about
less,
but
it
is
something
that
is
just
as
critical
right.
B
A
B
B
If
you
do
a
non-integrated,
aka
bare
metal,
but
not
bare
metal,
ipi
installation,
then
more
or
less
turn
off
the
nodes
change
the
disk
turn
it
back
on
and
you
might
have
to
connect
to
the
nodes,
but
in
theory
it
will
work.
Upi
is
probably
going
to
be
the
same
right
of
turn
off
the
nodes.
You
know,
of
course,
drain
coordinate
drain
it
first,
all
that
other
stuff
turn
off
the
node
change
the
disk,
bring
it
back
and
then
update
the
file
system
ipi.
B
On
the
other
hand,
the
only
way
to
do
it
is
going
to
be
to
create
a
new
machine
set
or
modify
the
existing
machine
sets
and
then
do
a
scale
down
scale
up
type
of
thing
now.
That
being
said,
so
is
it
a
support
area
because
it's
not
something
that's
tested
to
my
knowledge,
I
don't
think
that
we
on
the
engineering
side.
I
don't
think
that
they
test
any
of
those
scenarios,
so
they
don't
know
all
of
the
edge
cases.
They
don't
know
all
of
the
little
gotchas
and
all
the
little
things.
B
So
if
something
goes
wrong
in
that
process,
there's
a
chance,
you'll
get
the
response
of
well,
we
don't
know
so
we're
going
to
ask
you
to
go
through
the
process
we
do
know
which
is
to
create
a
new
node
and
add
it
to
the
cluster.
So
that's
my
my
long-winded
answer
to
that.
One
christian
chris,
anything
to
add.
C
Yeah
I
actually
took
that
question
you
you
went
to,
I
guess,
to
the
red
hat
core
os
side
of
things.
I
actually
thought
about
the
application
more
than
anything,
because
I
would
think
that
would
depend
on
whether
you're
using
a
csi
driver
or
not
right,
like
I
think,
through
csi,
you
can
grow
it
if
you're.
C
If
you're,
not,
I
think
you
would
grow
the
disc
at
the
at
the
storage
right
like
at
netapp
right
like
if
you're
using
an
app,
you
would
grow
it
there
and
then
all
of
a
sudden,
the
application
will
suddenly
just
see
more
storage.
So,
on
the
application
side,
I
would
say
it's
a
little
easier,
depending
on
what
you're
doing
versus
yeah
exactly
what
you
said
andrew
versus,
like
if
you're
like,
have
a
disc
full
on
one
of
your
nodes,
and
you
want
to
grow
it.
B
B
Essentially,
if
the
provisioner
supports
it,
you
can
turn
on
the
option
in
the
storage
class
and
then
you'd
be
able
to
go
in
and
resize
the
pvc
basically
say:
hey
you're,
now
this
size
and
theoretically
so
again,
assuming
the
provisioner
supports
it.
It
would
resize
everything
so
some
provisioners
and
in
particular
I'm
thinking
of
nfs,
but
you
could
probably
do
the
same
thing
with
like
an
iscsi
or
fibre
channel
one.
So
you
can
expand
the
storage
and
so
say
you
expand
the
nfs
export,
which
would
expand
the
storage,
but
kubernetes
would
be
unaware
of
that.
B
So
it
was
originally
created
as
a
five
gigabyte
pvc
and
then
you
expand
it
to
50
gigabytes.
The
application
would
see
and
have
access
to
5
or
50
gigabytes,
but
kubernetes
would
still
think
it's.
5
gigabytes
might
not
be
a
big
deal,
especially
if
your
pvc
reclaimed
policy
is
delete
right
when
that
pvc
is
released,
it
just
gets
deleted
and
nobody
knows
the
difference,
but
just
be
aware
of
that.
Both
of
those
are
possible.
D
A
B
B
C
B
Cincinnati
graph
data,
so
this
repository
is
what
contains
the
update
edges
right.
This
is
there's
a
file
inside
of
here
that
if
we
look
at
channels-
and
we
have
this
candidates,
we
have
fast-
we
have
stable.
So
these
represent
all
of
the
updates
from
and
to
edges.
If
you
will
right,
all
the
places
you
can
go
to
and
from
this
is
what's
actually
used
by
openshift
itself.
So
when
you
go
into
your
openshift
console-
and
you
have
all
of
those
options
to
update
to
it-
pulls
that
information
from
here.
B
B
C
C
B
D
B
It
was
changed
perhaps
that
person
was
mistaken,
so
that's
interesting,
so
yeah
jpj
feel
free
to
reach
out
to
reach
out
to
me
or
chris
or
christian.
You
know
ping
us
with
that
case
number
and
happy
to
take
a
look
and
see
what
we
can
do.
Maybe
not
live
on
the
stream,
but
we'll
see
what
we
can
do
there.
B
B
So
before
I
go
to
the
next
topic-
and
I
don't
see
any
other
questions
at
the
moment
so
yeah
again,
please
feel
free
to
ask
questions
at
any
point
in
time.
So
before
I
go
to
the
next
topic,
there
was
two
questions
or
two
things
that
have
come
up
over
the
last
week
that
I
wanted
to
talk
about,
and
this
is
stuff
that
I
see
fairly
frequently.
These
are
things
that
I
see
internally
that
I
like
to
bring
up
in
a
public
forum
so
that
we
can
talk
about
them.
B
No,
so
you
can
create
dhcp
reservations
after
the
nodes
have
been
provisioned,
but
you
can't
convert
them
to
static
ips.
The
reason
for
that
is
and
we'll
talk
about
that
next
is
simply
because
ipi
requires
dhcp.
You
know
when
you're
doing
node
scale
operations
right
all
those
other
things.
It
needs
to
be
able
to
pull
those
ip
addresses
and
make
those
nodes
network
connect
or
network
connected
without
intervention
from
anything
else.
C
Yeah,
so
actually
sorry
intro,
but
it's
it's
one
of
the
the
funny
things
we
kind
of
had
a
discussion
with
engineering
and
they
they
asked
a
simple
question.
Well,
how
do
you
expect
scaling
to
work
like
how
do
you
expect
the
node
to
get
an
ip
address
automatically
and
I
kind
of
pause?
I'm
like?
Oh,
that's
a
that's
a
good
question
like
you
almost
like
just
need,
dhcp
like
it
just
makes
sense
right
to
have
dcp
if
you
want
auto
scaling
so.
B
Technically
yes,
but
you'd
have
to
be
really
quick
on
the
keyboard
because
remember
the
openshift
installer
right,
the
binary
is
creating
those
nodes
on
your
infrastructure.
So
if
it's
vsphere
right,
it's
going
and
it's
it's
cloning
that
virtual
machine
template
and
it's
spinning
those
up
and
vcenter
just
randomly
assigns
it
a
mac
address.
B
So,
yes,
you
could
let
it
sit
there
and
spin
waiting
for
the
mac
address
and
then
real
quick
grab.
It
add
it
to
the
dhcp
server
right,
reload,
the
config
and
then
reboot
that
node,
but
that
I
I
just
that
seems
what's
what's
the
cutting
off
your
nose.
Despite
your
face,
it's
just
not
a
not
a
great
idea,
very
brittle,
very
hard
to
manage
very
hard
to
keep
up
so
upi.
B
Can
I
change
my
dhc
provision
host
to
static
ips?
Technically?
Yes,
so
there's
two
ways
that
I've
seen
talked
about
in
order
to
do
that.
So
the
first
one
which
is
most
common,
is
you
know,
hey.
I
can
just
create
a
machine
config
for
each
one
of
my
nodes
that
says
node
1
is
this
ip
node
2?
Is
this
by
p
node
3?
Is
this
ip
etc?
B
B
So
the
problem
here
is
that
becomes
complex
to
manage
as
well
right
and
it
can
become
brittle.
You
know
what
happens
if
I
accidentally
remove
that
particular
machine
config.
Well
now
my
my
node
is
going
to
revert
what
happens
if
I
have
a
conflict
and
a
future
config
that
maybe
red
hat
pushes
out
which
one
of
those
is
going
to
win,
so
it
can
be
a
little
bit
unpredictable,
so
it
becomes
complex.
It
becomes
a
little
bit
brittle
in
doing
that,
and
probably
something
that
you
want
to
avoid.
B
B
We
commonly
use
this
for
doing
things
like
configuring,
secondary
tertiary
interfaces
on
nodes,
but
for
configuring,
the
primary
interface
while
it
will
work
the
problem
is
what
happens
if
my
node
gets
into
an
unknown
state
right,
so
something
happens,
and
I
need
to
be
able
to
modify
that
network
config
on
the
management
interface,
the
interface
that's
connecting
to
the
control
plane.
Well,
more
or
less.
B
Could
you
work
around
that
sure
right
there
there's
ways
you
know,
maybe
if
it
is
on
the
network
just
with
a
bad
ip
address
or
something
like
that,
you
might
be
able
to
connect
in
and
change
it.
I
I
would
expect
that
it
to
self
heal.
If
that
were
the
case,
so
really
what
you're
talking
about
is
it's
disconnected
from
the
network?
How
do
I
go
in
and
reconfigure
the
network
and
remember
you
can't
log
in
on
the
console,
unless
you
specifically
do
something
to
to
enable
that
remember
it's
a
key-based
ssh
logins.
B
So
what's
the
correct
way
of
changing
a
node
from
dhcp
to
static,
essentially
destroy
and
recreate
the
node
and
and
deploy
it
from
day
one
using
that
static
ip
address,
it's
gotten
dramatically
easier
over
the
last
few
versions
to
to
do
that.
You
know
you
can
use
the
the
interactive
installer
if
you
need
to
do
advanced
network
configuration
right,
there's
all
kinds
of
ways
to
do
that.
So
definitely
keep
that
in
mind.
C
Yeah,
it's
definitely
you
have
to
pay
the
tax
somewhere
right
like
you
can't
it's
it's
unavoidable
right
like.
If,
if
you
want
to
use
static
ips,
you
have
to
essentially
go
through
the
the
process
of
setting
everything
up
from
the
beginning,
using
static
ips
right
or
if
you
want
to
use
dhcp
reservation.
Like
you
said
you
have
to
pay
the
tax
of
like
you
know,
spinning
it
up
looking
at
the
mac
address,
putting
that
in
right,
like
you,
just
have
to
pay
that
tax
somewhere
depending
on
you
know
what
what
you
want.
B
B
So
I
think,
from
my
perspective,
the
most
valid
knock
against
dhcp.
Is
it's
hard
to
do
highly
available,
dhcp
right,
correct
and
it's
it's
a
core
central
data
center
service.
At
that
point
right
I
need
dhcp
to
have
my
openshift
nodes
and
probably
other
things
up
at
all
times.
So
how
do
I
provide
a
dhcp
service
that
is
resilient
and
highly
available
and
so
on
and
so
forth?
B
So
you
might
need
to
work
with
your
architects
right.
You
might
need
to
work
with
whoever
is
implementing
and
running
that
design,
make
sure
that
it
is
capable
of
being
a
true.
You
know
one
of
those
services
that
that
that
is
highly
that
can
provide
an
sla
that
you
need
because
remember.
The
the
sla
that
you
can
provide
is
the
lowest
of
all
of
the
slas
that
you're
relying
on
so
right,
yeah.
B
B
If
you
deploy
ipi
with
vsphere
with
rev,
etc,
it
will,
by
default,
always
use
the
same
data
store
right
or
storage
domain.
So
I
have
my
you
know
when
I
go
through
and
I
do
my
vsphere
or
openshift
cluster
install
and
I
select
the
storage
domain
or
the
data
store
and
vsphere,
and
it's
data
store
one
it'll
upload
that
template
there
it'll
clone
that
virtual
machine
for
all
of
those
additional
or
for
all
of
the
nodes
that
happen
in
there.
What
happens
if
that
data
store
runs
out
of
space?
B
B
So
what
we
particularly
care
about
here
is
so
you
can
see
here
modifying
credentials
right
if
you
need
to
change
the
vcenter,
username
or
password,
etc,
so
adding
new
data
stores
for
provisioning,
so
this
is
re,
is
specifically
relevant
to
pvcs
right.
So
if
I
can
add
additional
data
stores
down
here
right,
I
have
additional
data
stores
there
so
on
and
so
forth.
However,
if
I
want
to
do
it
with
my
virtual
machines
with
the
ipi
worker
nodes,
you
have
to
modify
that
in
the
machine
set
definition.
B
B
B
B
So
essentially
you
need
to
have
a
template
vm
in
the
data
store
that
you
want
to
use,
and
then
you
specify
that
template
vm
for
this
and
it
will
automatically
or
it
should
automatically
clone
into
that
notice
down
here.
We
also
have
a
data
store,
so
you
want
to
make
sure
that
that
matches
as
well.
You
also
want
to
make
sure
that
that
data
store
is
defined
in
your
vsphere.conf.
B
B
Yes,
that
would
be
my
expectation,
so
it
it
may
be
possible.
I
haven't
tested.
It
may
be
possible
to
use
a
template.
That's
in
a
different
data
store.
However,
at
a
minimum.
I
would
expect
that
to
extend
the
amount
of
time
it
takes
to
do
or
to
create
the
new
notes,
because
that
can
no
longer
be
an
offloaded
clone
operation.
It
now
has
to
copy
the
data
in
between
the
two
data
stores.
B
B
A
D
B
B
B
So
technically
each
one
of
those
things
individually
is
possible
put
together
into
an
end-to-end
process
and
especially
one
that
is
stable.
If
you
will
stable
and
testable
that's
what
I
have
no
knowledge
of
whatsoever,
so
I
I
can
only
rely
on
what
engineering
tells
me
and
engineering
says
we
can't
do
this.
B
B
C
Yeah,
so
so,
actually,
I'm
actually
glad
you
said
that
we
say
a
lot
of
the
time.
You
know
I
I've
I've
evolved
from
saying,
not
supported
from
technically
possible,
not
supported,
because
I
think
a
lot
of
people
conflate
the
two
right.
I
had
just
quick
story.
I
had
a
kind
of
a
little
back
and
forth
with
a
customer
because
I
say:
well,
that's
not
supported
and
they're
like
well.
What
do
you
mean?
I
can
technically
do
x,
y
z,
I'm
like
yeah,
you
know
and
then
I
kind
of
backtrack
yeah.
C
A
C
B
A
B
A
A
B
D
B
So
the
support
folks
will
default
to
everything
that
is
documented.
So
if
it's
on
docs.openshift.com
fully
supported,
if
it's
not
there,
then
is
there
a
kcs
about
it
and
more
more
especially
or
more
specifically.
Is
there
a,
and
let
me
see
if
I
I've
got
this
one
up
here
right
is
that
kcs
verified
not
in
progress
right?
Not
any
of
those
things.
Is
it
a
verified
solution
so
a
lot
of
times
they
will
use
kcs
to
fill
gaps
in
documentation
of
things
that
have
been
tested
and
validated.
B
B
B
B
It
is
not
documented
in
an
obvious
place,
always,
but
it's
pretty
straightforward,
so
what
I
mean
by
it's
not
always
documented
in
an
obvious
place.
So
if
I
come
to-
and
I'm
just
gonna
pick
on
vsphere
here,
if
I
come
to
vsphere
you'll,
see
that
I
have
all
of
these
different
things
that
are
here,
including
restricted
network
vsphere
installation,
and
I
can
click
on
this
and
it'll
go
through
and
it
walks
me
through
the
process
which
is
going
to
be
99
the
same
as
a
standard
install
so
what's
different.
C
B
Yeah-
and
this
is
an
area-
and
I
would
very
much
welcome
feedback
of
when
you
look
at
our
documentation.
Some
things
are
documented
only
in
one
or
two
places,
but
they
globally
apply.
So
a
perfect
example
is
using
a
proxy
during
install
documenting.
That
is
only
done
as
far
as
I
know
in
the
installation
on
bare
metal
right
where
it
goes
in,
and
it
says
you
know
here's
how
to
how
to
provide
the
proxy
credentials
here.
Let
me
open
a
a
new
tab
here.
C
C
B
B
Installation
I
gotta
go
to
the
right
page
always
so
this
is
the
only
place
in
the
docs
where
this
is
listed,
but
it
applies
to
all
of
the
installation
methods
it
doesn't
matter
if
you're
connected
disconnected
if
you're
using
you
know
on-prem
if
you're
using
a
cloud
provider.
If
you
need
to
configure
the
cluster-wide
proxy
install.
This
is
how
you
do
it,
but
it's
only
in
the
bare
metal
installation
docs.
B
B
B
What
we
really
care
about
is
coming
down
here.
Apologies
for
the
scrolling,
so
we
need
our
pull
secret,
which
is
what
this
is
describing
and
we
need
to
then
define
some
some
variables.
So
these
variables
are
optional.
You
can,
of
course,
provide
them
in
line.
It
just
makes
it
a
little
easier,
crafting
our
command
and
then
down
here
we
have
these
oc
adm
release
mirror
commands.
B
D
C
C
B
D
C
C
B
B
B
B
B
B
B
B
C
C
D
B
All
right,
so
the
next
thing
that
we
need
to
do
is
actually
download
all
of
these
images.
So
if
we
scroll
up
here
right,
it's
telling
us
here's
all
of
the
images.
Here's
all
the
things
that
I'm
going
to
need
for
this
particular
release,
so
we
would
need
to
download
all
of
those.
So
I
have
this
command
here.
Hopefully
this
time
I
got
it
correct.
C
A
C
C
B
All
right
so,
let's
say
that
we
downloaded
all
that
information.
You
know
it'll
spit
out,
so
for
the
469
release,
it
is
6.4
gigabytes
worth
of
images.
I
know
that
because
I
did
this
yesterday,
so
I
I
have
moved
those
over
to
my
destination
network.
I
have
now
changed
I'm
on
my
disconnected
network
and
I
execute
this
command,
which
basically
says
ingest
all
of
these
files
and
push
them
into
my
disconnected
registry
right.
So
pretty
straightforward.
B
B
I
can
use
that
to
install
as
many
clusters
as
I
want.
It's
not
a
one-to-one
basis.
I
point
all
of
my
clusters.
At
it.
Everything
runs
great
everything's,
phenomenal
deployment
happens
as
deployment
does
so
what's
the
next
step.
So
normally
at
that
point,
so
I've
got
a
a
good
cluster.
I've
got
it
up
and
running.
So
the
question
is,
I
want
to
add
some
operators.
I
want
to
do
some
stuff
right.
Maybe
I
want
to
deploy
the
logging
service.
Maybe
I
want
to
deploy
ocs.
B
B
B
So
how-
and
why
does
this
work
so
as
of
openshift
4.6
olm,
the
operator
catalog
uses
a
different
format.
It
now
uses
an
index
image
that
contains
all
of
the
information
all
of
the
things
that
we
need
for
each
one
of
our
operators.
So
effectively
we
look
at
our
catalog
sources.
We
pull
that
index
image.
We
pull
all
of
the
child
if
you
will
so
all
of
the
images
needed
for
those
operators,
and
then
we
move
all
of
that
information
to
our
disconnected
network.
B
B
You
can
see
that
I
have
four
default:
catalog
sources,
certified
community,
red
hat
marketplace
and
red
hat
operators.
So
if
you're
familiar
with
operator
hub
through
the
administrator
gui
right,
those
are
the
four
little
check
boxes
of.
Where
do
I
want
to
get
stuff
from
and
in
order
to
see
which
operators
are
in
each
one
of
those?
I
can
use
the
command
get
package
manifest.
B
B
B
So
this
kcs
explains
which
operators
are
known
to
work
and
be
supported
on
disconnected
installs
so
of
all
of
the
operators
that
we
have
available
to
us.
So
here's
cluster
logging,
for
example.
We
see
because
there's
a
check
mark
here
that
it
is
supported.
It
is
known
to
work,
but
you'll
notice
that
there's
a
number
of
these
that
aren't
supported
and
disconnected.
B
C
B
Exactly
so,
like
cluster
logging,
we
know
we're
going
to
need
the
logging
operator
itself.
We
also
need
the
elasticsearch
operator,
you'll
notice,
both
of
those
have
check
marks.
So
how
do
I
actually
do
that
right?
So
there's
a
couple
of
different
steps
associated
with
that
so
first
and
we'll
come
back
to
this
guy.
B
So
we're
going
to
be
what
the
docs
call
pruning
the
index
image
down
here
so
kind
of
the
same
thing
here
in
the
documentation
talking
about
the
different
catalog
sources,
and
then
we
need
to
create
an
index
image.
So
first,
I'm
going
to
need
some
cli
tools.
First,
one
being
opm,
so
opm
is
one
that
was
new
to
me.
I
actually
didn't
know
that
this
one
existed
until
I
started
digging
into
this.
I'm
sure.
C
B
B
Yeah,
so
it's
it's
new
to
4.6
right,
and
this
is
what
we
use
to
manage
various
aspects
of
those
operator
indexes
and
catalog
sources,
so
you
can
see
installing
it
pretty
straightforward,
I'm
not
going
to
walk
through
this
process.
I've
already
done
it
all
we're
doing
is
doing
an
oc
image
extract
from
that
particular
pod,
or
excuse
me
that
particular
image.
This
is
the
same
way
that
you
would
extract,
for
example,
open
shift,
install
or
oc
command
line
tools,
etc.
B
D
B
B
B
B
So
I'm
going
to
use
my
source
index
so
real
quick.
How
do
I
know
what
this
particular
image
is?
So
if
I
do
an
oc
get
catalog
source
again
right?
I
have
my
catalog
sources,
so
maybe
I
want
to
pull
from
the
certified
operators,
so
I
can
do
an
oc
describe
catalog
source,
the
name
that
we're
going
to
use
and
we're
going
to
do
a
pipe
to
grep
for
image
capital.
I.
C
D
B
C
B
B
B
B
B
A
D
A
B
C
B
B
B
File
that
has
my
customized
index
so
we'll
still
need
to
go
through,
and
we
don't
have
time
for
that.
Unfortunately,
today
I'll
be
sure
to
link
all
of
the
information,
all
the
relevant
information,
but
we
would
still
need
to
pull
down
the
images
that
are
being
referenced
there
and
then
just
move
all
of
that
information
together.
B
So
I
will
take
this
opportunity
because
I
said
I'll
link
all
of
that
information,
so
we
are
starting
something
a
little
bit
new
in
that
after
this
show
expect
in
the
next
day
or
so
to
see
a
post
on
openshift.com
blog.
That
includes
all
of
our
show
notes
all
of
the
links
all
of
the
information
that
we
talked
about
here
during
the
stream.
B
So
that
way,
if
you
missed
any
of
that
in
chat
all
that
type
of
stuff,
it'll
be
a
great
place
to
go
and
find
that
information
as
well
as
any
other
hanging
things.
What
do
I
mean
by
that?
If
there's
any
outstanding
questions
right?
How
many
times
have
chris?
Have
we
had
a
thing
where
it's
like?
I
don't
know,
but
we'll
get
back
to
you.
That's
where
we'll
try.
B
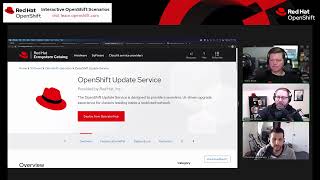
So
the
open
shift
update
service.
Let
me
post
this
link
in
here
as
well
as
over
here.
So
this
is
designed.
It
is
meant
to
provide
the
hands
off
right,
the
the
over
the
air,
the
click
to
do
an
update
cluster
for
your
disconnected
clusters
for
a
cluster.
That's
anywhere,
really,
you
could
even
point
your
connected
cluster
at
an
instance
of
this.
If
you
wanted
to,
for
example,
control
right
in
a
much
more
controlled
manner,
right,
don't
show
me
everything.
B
Unfortunately,
even
though
this
blog
post
was
made
roughly
three
months
ago,
even
if
I
were
to
scroll
down
here
down
to
how
do
I
do
this,
and
you
know
oh,
it
says
that
you
need
to
go
through
and
deploy
from
the
operator
catalog,
and
it
provides
this
really
nice
link
over
to
the
operator
that's
associated
with
this.
It's
not
actually
available
yet.
So
I
was
under
the
impression
that
this
went
ga
with
4.6.
B
However,
it
is
not
so
once
this
becomes
available,
we'll
talk
about
it
again,
but
for
right
now
just
know
that
if
you
want
to
have
the
openshift
update
service,
we
just
have
to
wait
a
little
bit
longer,
yep
all
right,
so
I
believe
we
are
out
of
time
christian.
Thank
you
so
much
for
coming
on
today.
I
appreciate
your
perspective
as,
as
always.