►
Description
This is a recorded public webinar from April 4, 2019, where Steve Kriss and Tom Spoonemore presents Velero, shows how it's being used for Kubernetes backup and migration tasks, and includes live demos.
Check out Velero here:
https://github.com/heptio/velero
Join the Velero Community Meetings every 1st and 3rd Tuesday, details here:
https://github.com/heptio/velero-community
A
A
Webcast
before
we
get
started,
there
are
a
couple
of
housekeeping
items
that
I
would
like
to
go
over.
First,
we
want
to
make
this
session
as
interactive
as
possible
and
encourage
you
to
ask
questions
at
any
time.
Using
the
question
answer
box
located
to
the
left
of
the
slides
window,
you
can
also
use
the
question-and-answer
box
to
get
technical
assistance
if
you
should
need
it.
The
tabs
located
in
the
question
answer
box
are
where
you
can
find
additional
information
about
today's
presentation.
A
Today's
presentation
features
streaming
audio
only
so
there
is
no
need
to
dial
into
a
teleconference
you'll
need
to
make
sure
that
your
computer
speakers
are
turned
up
in
order
to
hear
the
presenter
and
today's
content,
you
can
also
fine-tune
the
audio
by
using
the
volume
controls
inside
the
media
window.
This
presentation
console
allows
you
to
interact
and
customize
the
layout
to
fit
your
viewing
needs.
You
can
collapse
and
expand
to
any
window
on
the
console.
Just
like
you
would
on
your
desktop
by
dragging
the
corners
in
or
out.
A
In
addition,
you
can
also
maximize
or
close
any
of
the
windows
on
your
screen
by
clicking
the
corresponding
icon.
In
the
upper
right
hand,
corner
of
each
of
the
windows
at
any
time,
you
can
reset
the
console
to
the
default
layout
and
access
additional
presentation
functionality
using
the
widgets
at
the
bottom
of
your
screen.
Now,
I
would
like
to
turn
things
over
to
today's
presenter
to
get
things
started.
A
A
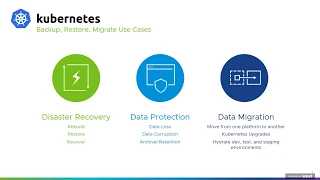
So
today,
we'll
be
covering
kubernetes
backup/restore
migration
use
cases
and
using
Valero
to
perform
those
there'll
be
a
short
introduction
to
Valero,
we'll
talk
about
strategies
for
protecting
your
cloud
native
applications
and
we
will
do
a
demo
of
Valero
doing
some
pre
unique
migration
use
cases.
Kubernetes.
A
So
kubernetes
is
very
similar
to
other
platforms
and
that,
obviously,
if
you
have
a
an
application
running
on
top
of
kubernetes
you're
going
to
want
to
backup
and
restore
those
applications
for
various
reasons,
disaster
recovery
is
a
primary
reason.
You
want
to
be
able
to
restore
your
application
in
case
of
some
kind
of
an
issue
with
it.
You'll
be
able
to
want
to.
A
You
will
want
to
be
able
to
rebuild
your
cluster
when
necessary,
so
that
you
can
recover
applications
and
in
the
event
of
some
kind
of
a
hardware
failure
or
some
kind
of
a
failure
of
the
application
itself,
there
will
be
data
protection,
use
cases
that
you
will
be
necessary.
It
will
be
necessary
for
you
to
address
things
like
data
loss
in
your
cluster
and
your
application
if
data
becomes
corrupt
or
for
one
reason
or
another,
its
lost
and
then
for
many
industries.
B
A
Also
we're
seeing
a
number
of
customers
that
will
that
have
a
dev
test
or
staging
environment
that
they
want
to
hydrate
with
data
from
one
of
their
other
environments,
either
their
production
environment,
or
maybe
they
have
a
staging
data
set,
and
they
want
to
add
that
or
hydrate
that
to
a
particular
target
environment.
So
these
are
all
use
cases
that
are
that
are
necessary
in
any
time,
you're
hosting
applications
on
your
kubernetes
clusters.
A
The
current
version
of
Valero
is
11
and
it's
the
first
release
under
the
new
name.
Valero
you.
If
you
haven't
heard
of
Valero
before
you
may
have
heard
of
it
as
hefty
Oh
arc.
Hefty
Oh
arc
is
the
previous
name,
and
it's
recently
undergone
a
name.
Change
so
Valero
helps
your
DevOps
teams
and
platform
operators
configure
scheduled
backups
trigger
ad-hoc,
restores
backups
and
performs
data
migrations.
A
The
other
thing
that
we're
advocating
for
and
we're
seeing
a
lot
in
the
kubernetes
community
is
this
concept
of
ephemeral
clusters,
and
that
is
similar
to
when
the
ends
came
on
to
the
fore
and
applications
were
hosted
on
those
VMs.
Well,
we
had
a
desire
to
create
applications
that
we
could
treat
like
cattle
as
they
say
where
you
can
immediately,
instead
of
actually
going
in
fixing
an
application.
You
just
you
just
kill
the
application,
and
then
you
can
respawn
it
fresh.
A
So
there's
much
more
to
consider
when
you're
backing
up
a
kubernetes
cluster.
There
are
master
nodes
that
are
present,
there's
the
sed
database,
that
is
maintaining
the
state
of
the
cluster,
and
there
are
work
nodes
worker
nodes
where
your
actual
applications
are
running
as
pods,
and
so
how
does
one
approach
backing
up
the
state
of
the
this
cluster?
That
is
the
question
that
that
velaro
is
here
to
answer
so
at
this
point.
I'll
turn
this
over
to
Steve
and
he
will
take
you
through
how
bolero
addresses
this.
B
Thanks
Tom,
so,
as
Tom
said,
things
are
no
longer
so
simple
as
having
an
application,
essentially
be
the
same
as
the
server
it's
running
on.
So
in
a
kubernetes
environment.
When
we're
developing
a
backup,
recovery
and
migration
strategy,
we
really
need
to
think
about
where
the
state
is
within
that
overall
system,
because
the
state
is
going
to
be
the
essential
part
of
how
we
backup
recover
or
migrate,
and
so
in
kubernetes
in
the
first
place
where
state
is
stored,
is
within
that
@cd
database.
This
is
the
persistent
storage
back-end
for
the
kubernetes
api.
A
B
B
A
cluster
running
and
you
have
nodes
that
become
unhealthy.
There
are
tools
through
kubernetes
through
the
cube
control
command
to
actually
safely
remove
those
nodes
from
the
cluster
and
then
from
there.
You
should
be
able
to
use
your
configuration
management
tool
of
choice,
could
be
terraform,
ansible,
chef,
puppet,
etc
to
be
able
to
create
a
new
node
from
a
standard
template
that
you
have
and
then
to
be
able
to
reattach
that
to
your
cluster
and
similarly
to
this
approach
for
replacing
nodes,
we
think
that
you
should
focus
on
automation
for
creating
new
clusters
as
well.
B
One
area
of
interesting
development
in
this
space
is
the
work
that's
going
on
in
the
upstream
kubernetes
community
around
the
cluster
API,
and
this
is
an
effort
to
introduce
a
kubernetes
style,
declarative
API
for
provisioning
new
kubernetes
clusters
themselves,
and
so
the
idea
is
that
you
would
define
an
API
object.
That
has
your
desired
specification
for
new
clusters
and
there
would
be
a
kubernetes
controller,
that's
actually
responsible
for
going
out
and
provisioning
all
the
infrastructure
and
doing
all
the
setup
work
to
create
that
cluster.
So
that's
a
really
interesting
way.
B
That
I
think
folks
will
start
to
think
about
spinning
up
new
clusters
as
needed,
but
so,
regardless
of
the
tool
that
you
choose
for
for
being
able
to
provision
new
nodes
and
new
clusters,
you
really
need
to
focus
on
on
making
those
nodes
and
those
clusters
very
uniform,
very
generic
and
very
reproducible.
And
if
you
do
that,
then
point-in-time
backups
become
less
important,
because
if
you
need
a
new
node
or
if
you
need
a
new
cluster,
you
can
use
your
automation
to
stamp
out
new
copies
of
these
resources.
At
any
time.
B
So,
let's
take
a
look
in
a
little
bit
more
detail
at
the
approaches
to
backing
up
these
stateful
components,
and
so
first
we'll
talk
about
possible
ways
to
back
up
your
kubernetes
resource
definitions
themselves,
which
are
stored
in
at
CD.
So,
first
of
all
you
can,
you
can
certainly
use
kind
of
generic
block
or
filesystem
level
backups
for
the
device
that
SCD
is
storing
its
data
on
this
is
kind
of
the
lowest
common
denominator
and
it's
not
a
bad
place
to
start
beyond
that.
B
Fcd
provides
a
command-line
tool
at
CDE
CTL,
and
this
tool
offers
snapshot
capabilities
of
at
CD,
and
so
at
CD
is
a
distributed
system.
You
have
multiple
nodes
that
are
making
up
the
overall
at
CD
cluster
and
so
having
more
application-aware
snapshots
will
give
you
better
application,
consistent
backups,
and
so
this
is
definitely
using
at
CD.
Ctl
snapshot
capability
is
definitely
an
improvement
over
a
generic
block
or
file
level
backups
and
then
the
kubernetes
api
is
actually
another
way
that
we
can
access.
The
information
in
that
CD.
B
So
we
know
at
CD
is
the
backing
store
for
the
kubernetes
api,
so
the
api
can
create
information
and
SCD,
but
it
can
also
be
used
to
list
all
of
the
kubernetes
resource
definitions
that
are
stored
in
that
CD,
and
so
this
is
another
possible
way
that
we
can
get
at
that
information
and
externalize
it
in
the
form
of
a
backup
and
then
on
the
persistent
volume
side.
There
are
a
couple
of
different
approaches.
So,
first
of
all,
you
should
certainly
look
at
your
storage
providers
native
capabilities.
B
Most
public
cloud
providers
have
snapshot
api's
for
creating
snapshots
and
then
replicating
that
data
across
availability
zones
and
regions
and
many
on-premises
storage
platforms
have
this
capability
as
well.
You
can
also
use
file
level,
backup
tools,
and
this
can
be
really
useful
if
you
need
to
do,
for
example,
single
file
restores.
So
this
is
another
approach
to
consider
here
and
then
I'd
also
like
to
mention
the
work
that's
going
on
in
the
upstream
kubernetes
community
through
the
storage
special
interest
group,
which
is
to
introduce
a
a
snapshot
API
to
the
kubernetes
ecosystem.
B
B
So,
let's
get
back
to
Valero
now
and
talk
a
little
bit
about
the
approaches
that
it
chooses
for
doing,
backup
and
restore
of
these
persistent
stateful
stateful
entities
and
talk
a
little
bit
about
its
feature
set.
So
first
of
all,
Valero
backs
up
and
restores
both
kubernetes
resources
as
well
as
persistent
volumes,
and
so
these
are
the
the
two
stateful
components
that
we've
been
talking
about.
B
B
The
first
one
is
that
using
the
API
to
access
this
data
really
enables
fine
grained,
backup
and
restore
of
potentially
individual
kubernetes
resources,
and
so,
for
example,
you
can
backup
individual
resource
types.
Maybe
just
your
deployments
or
your
config
maps,
you
can
backup
resources
only
from
individual
namespaces
and
you
can
even
use
label
selectors
to
specify
which
resources
you
want
to
backup
if
you're,
using
a
full,
sed
backup
approach.
You
don't
have
this
granularity
to
pick
and
choose
which
resources
you
want
to
backup.
B
So
a
great
example
of
this
is
that
Valero
enables
you
to
restore
kubernetes
resources
in
two
different
namespaces
than
where
they
were
backed
up
from.
So
this
is
a
really
great
way
to
possibly
create
a
copy
of
the
namespace
or
to
migrate
a
workload
from
one
namespace
to
another
and
again,
this
is
something
that
wouldn't
really
be
possible
if
you're
doing
full,
@cd,
backups
and
restores
and
then
on
the
persistent
volume
side.
Valero
is
able
to
back
these
up
and
the
primary
way
it
does.
A
B
Source
tool
that
those
backups
at
the
file
level,
so
this
is
a
really
useful
option.
If
maybe
your
storage
provider
hasn't
been
integrated
with
Valero,
yet
or
maybe
doesn't
have
a
snapshot
API,
you
can
use
the
rustic
integration
to
get
generic
backups
and
it's
also
really
useful
for
potentially
cross-platform
migration
scenarios,
where
you
can't
rely
on
a
single
storage
providers,
snapshot
format,
because
you
need
something:
that's
portable
across
providers.
B
So,
let's
take
a
look
at
a
simple
Valero,
workflow
and
and
what
that
might
look
like.
So
in
the
diagram
here
on
the
Left,
we
have
our
first
kubernetes
cluster
and
in
this
cluster,
we're
using
Valero
to
take
a
backup
of
a
particular
name
space
and
so
Valero
is
installed
in
this
cluster.
It's
communicating
with
the
kubernetes
API
to
fetch
all
of
the
resources
that
are
deployed
in
that
namespace,
and
it's
also
going
to
identify
any
persistent
volumes
that
are
used
by
that
namespace
and
we'll
take
snapshots
of
those
using
the
sword's
providers.
B
Api's
and
all
of
this
data
will
be
uploaded
to
the
cloud
somewhere.
So
the
kubernetes
resources
are
uploaded
to
object,
storage
and
snapshots
will
be
stored
in
the
storage
platform
and
then
on
the
right.
We
have
a
second
cluster
cluster
B,
which
is
actually
executing
a
restore
so
that
cluster
B
is
connected
to
the
location
in
the
cloud
where
cluster
a
is
backup
was
created,
and
so
cluster
B
is
able
to
execute
a
restore
of
that
backup
and
reconstitute
the
kubernetes
resources
in
cluster
B
and
get
restorations
of
the
persistent
volumes
from
those
snapshots.
B
And
so
this
is
a
great
demonstration
of
potentially
a
disaster
recovery,
Center
disaster
recovery
scenario,
where
maybe
we
we
lost
cluster
a
and
we
needed
to
restore
service
into
a
new
cluster.
It's
also
a
great
example
of
a
migration
scenario
where
we
simply
have
a
workload
or
a
namespace
that
we
want
to
move
from
cluster
a
to
cluster
B,
and
so
what
I'd
like
to
do
now
is
actually
jump
into
a
demonstration
of
some
of
the
capabilities
that
Valero
has
in
action.
B
So
I'd
like
to
show
two
examples
of
using
Valero
to
backup
and
restore
applications
running
in
a
kubernetes
cluster.
So
for
the
first
example,
I
have
a
kubernetes
cluster
running
in
AWS
and
I
have
a
wordpress
instance
running
within
that
cluster.
So,
if
I
take
a
look
at
the
deployments
that
are
running
in
my
default,
namespace
I'll
see
that
there's
a
WordPress
and
a
WordPress,
my
sequel
deployment
running
and
additionally,
we
have
a
couple
of
services
running
and
each
of
those
deployments
has
a
persistent
volume
claim
that
it's
using
as
its
back-end
storage.
B
Now
on
the
bottom
here,
I
have
a
cute
controlled
port
forwarding
set
up
so
that
I
can
access
the
WordPress
front-end
through
my
local
browser.
And
so,
if
I
switch
over
to
my
browser
refresh
the
page,
we'll
see
that
Steve's
awesome
blog
is
running
and
so
far
I
don't
have
any
posts.
So
the
first
thing
I'll
do
is
actually
create
a
new
post
title
at
hello,
world
and
I.
B
So
now,
I'll
go
back
to
my
terminal,
and
the
next
thing
I'd
like
to
do
is
create
a
backup
of
that
WordPress
application,
so
I'll
save
velaro,
backup,
create
and
I'll
call
it
WP
for
WordPress,
and
then
I'd
like
to
include
everything
in
the
default
namespace,
so
I'll
specify
include
namespaces
default
and
then
I'll
also
specify
the
weight
flag,
which
will
just
wait
for
the
backup
to
complete
so
I'll
go
ahead
and
run.
That
and
velaro
is
now
communicating
with
the
kubernetes
api
and
getting
all
the
resources
running
in
that
default.
Namespace.
B
And
it's
also
looking
for
any
persistent
volumes
that
are
being
used
by
the
resources
running
in
that
namespace
and
if
it
finds
them,
it
should
take
snapshots
of
the
underlying
Cloud
volumes.
So,
since
we're
running
on
AWS,
those
persistent
volumes
are
backed
by
EBS
volumes,
and
so
we
should
get
EBS
snapshots
of
those
volumes.
B
Now,
there's
a
bunch
of
output
here,
but
I
want
to
just
look
at
what's
on
the
bottom,
and
we
see
that
under
the
person
vol
section,
we
have
two
snapshots
that
appear
and
we
have
some
information
about
the
snapshot,
IDs
and
and
other
information
about
the
volumes
that
are
being
backed
up
so
so
far.
This
looks
pretty
good.
B
So
what
I'll
do
now
is
I'll
actually
simulate
a
disaster
by
going
ahead
and
deleting
the
WordPress
application
from
this
cluster,
so
I'm
gonna
say:
cube,
CTL,
delete
deployment
services
and
persistent
volumes
that
are
labeled
with
app
equals.
Wordpress
I'll
go
ahead
and
run
that
and
I'm
also
gonna.
Stop
my
port
forwarding
command
down
here
on
the
bottom.
B
And
so
these
all
of
these
resources
are
being
deleted
now
and
that's
complete,
and
so,
if
I
switch
back
to
the
browser
and
refresh
we'll
see,
we
no
longer
have
a
connection.
So
the
next
thing
I'd
like
to
do
is
switch
to
my
second
terminal
window
here.
So
I'm
gonna
click
on
that
and
this
terminal
is
connected
to
an
entirely
separate
kubernetes
cluster.
It's
another
cluster
running
in
AWS,
so
we'll
call
this
one
cluster
tube
and
what
I'd
like
to
show.
You
is
the
backup
locations
that
are
configured
for
Valero
running
in
this
cluster.
B
So
if
I
run
the
lera
backup
location
yet
we'll
see
that
there
are
two
backup
locations
configured
for
this
cluster
and
the
first
one
is
actually
named
cluster
one
and
the
bucket
that
that's
pointed
to
is
called
Valero
backups.
Now
this
is
the
bucket
that
actually
cluster
one
was
pointed
to,
and
so
the
backup
that
we
took
a
minute
ago
is
actually
stored
in
this
bucket
and
then
additionally,
I
have
a
second
backup
location,
that's
called
default,
and
so
any
new
backups
that
I
take
from
within
cluster
two
will
be
stored
in
this
backup
location.
B
But
the
important
thing
is
that,
since
we
have
a
backup
location
configured
pointing
to
cluster
ones
bucket,
we
should
be
able
to
access
the
backup
that
was
just
taken
from
cluster
one
within
this
new
cluster
two.
And
so,
if
I
run
a
Valero
backup,
get
command
will
see
that
the
WP
backup
which
I
just
took
is
available
in
this
cluster.
For
restore
now
I'll
show
you
that
I
don't
have
deployments
services
or
PVCs
running
in
the
default
namespace
apart
from
the
kubernetes
service,
which
is
not
part
of
the
WordPress
application.
B
So
this
restore
should
take
just
a
couple
more
seconds
to
complete
great.
So
our
restore
is
now
complete
and
so
now
I'll
go
ahead
and
look
and
if
I
run
cube,
CTL
get
deploy.
We'll
see
that
both
of
my
deployments
are
there
and
if
I
look
at
PVCs,
we'll
see
that
I
have
both
of
my
PVCs
that
were
just
created
and
finally
I'll
look
and
see
if
my
pods
are
up
and
running
yet
and
great.
B
So
we
have
a
wordpress
pod,
that's
now
running
and
that
my
sequel
pod,
that's
running
as
well,
so
I'll
set
up
the
port
forwarding
command
again
so
that
I
can
hopefully
access
the
WordPress
UI
through
my
browser,
all
right,
and
so
now
I'll
switch
back
to
the
browser.
And
if
I
refresh
this
page,
we
get
reconnected
to
Steve's,
awesome
blog,
so
that's
great
and
if
I
scroll
down,
we
have
our
hello
world
post,
so
hello
from
cluster
one.
So
this
WordPress
side
is
now
in
early
running
in
cluster
two.
B
We
backed
it
up
in
cluster
one
and
restored
it
into
cluster
two,
so
that
hopefully
gives
you
an
idea
of
how
you
could
either
do
a
disaster
recovery
into
a
new
cluster
running
within
NWS
or
if
you
simply
wanted
to
migrate
a
workload
of
how
you
could
migrate
from
one
cluster
to
another.
So,
let's
move
on
to
the
second
example,
where
I'd
actually
like
to
migrate
this
application
out
of
AWS
and
into
a
cluster
running
on
gke
on
Google's
kubernetes
engine.
B
Now
we
can't
use
EBS
snapshots
to
do
this
migration
because
Google's
cloud
doesn't
understand
anything
about
EBS
snapshots
and
so
Valero
has
a
generic
mechanism
for
backing
up
volume.
Contents
called
rustic
rustic
is
an
open
source
tool
for
doing
file
level
backups,
and
so
what
I'd
actually
like
to
do
now
is
take
a
backup
from
cluster
to
using
rustic
to
backup
the
contents
of
those
volumes.
B
Include
the
default
namespace
and
I'll
use
that
wave
flag,
so
Valero
again
is
is
getting
all
those
API
resources
that
exist,
but
rather
than
taking
EBS
snapshots
of
the
persistent
volumes
it
finds
it'll
be
using
rustic
to
backup
the
contents
of
those
volumes.
So
we'll
give
this
a
few
more
seconds
and
it
should
complete
great.
So
now,
if
I
run
the
bolero
back
up,
describe
command
for
WP,
rustic
and
I
pass
details.
B
What
we
see
at
the
bottom
is
rather
than
having
information
about
EBS
snapshots.
We
have
a
section
about
rustic
backups
and
we
see
those
two
volumes
that
we
asked
to
be
backed
up
are
included
there.
So
that's
great
I'm
gonna!
Stop
my
port
forwarding
command
here
and
I'm
gonna
go
ahead
and
delete
again
that
deployment
the
service
and
the
persistent
volume
claims
from
this
cluster
and
I'll
switch
back
to
the
browser
and
show
that
we
no
longer
have
a
connection
there.
B
B
Now,
if
I
look
at
the
backup
locations
that
are
configured
here
again,
we
see
two
backup
locations
and
the
first
one
is
called
AWS,
and
it's
pointed
to
that
velaro
backups
to
bucket,
which
is
where
all
backups
that
were
created
in
cluster
two
we're
going
and
so
because
that's
configured
I
should
be
able
to
see
the
backup
that
I
just
created
if
I
run
velaro
backup
get
so
we
see
WP
rustic.
So
what
I'd
like
to
do
now
is
just
do
a
restore
from
that
backup.
B
A
Okay,
so
it
was
very,
very
good
demo,
so
I
just
wanted
to
remind
everyone
that
Valero
is
a
open
source
project.
We
currently
have
about
75
contributors
and
2,300
stars
on
github.
We
would
love
to
have
you
all
download
and
try
Valero
and
also,
if
you
want
become
a
contributor
for
project
Valero,
follow
us
on
Twitter
at
project
Valero.
We
also
are
present
on
kubernetes
slack
channel
at
the
Valero
channel
and
you
can
get
involved
with
our
mailing
list
on
Google
as
well
project
Valero.
A
B
Yeah,
so
I
can
I
can
jump
in
for
that
one.
So
today
the
lair
o
considers
the
node
API
objects,
Nam
restorable,
resources,
where
we
essentially
consider
these
part
of
the
cluster
infrastructure,
and
so
we
don't
actually
do
any
restoration
of
them.
So
you
wouldn't
be
able
to
copy
these
over
from
a
from
a
back
up
onto
the
nodes.
B
We
are
considering
adding
some
additional
functionality
to
Valero,
though,
to
allow
you
to
sort
of
merge
the
contents
of
a
backup
into
a
running
cluster
so
that,
if
you
already
have
node
API
objects
in
your
cluster,
you
can
do
things
like
take
the
labels
from
the
backup
or
take
the
annotations
from
the
backup
on
that
node
object
and
apply
them
to
the
nodes
that
are
currently
in
the
cluster.
So
it's
definitely
something
that
we're
thinking
about,
but
today
nodes
are
kind
of
a
special
API
object
and
we
we
basically
do
not
restore
them.
B
Yeah,
so
so,
as
I
mentioned,
rustic
is
a
file
level,
backup
tool,
and
so
it
is,
it
is
taking
a
backup
at
the
file
level.
It
supports
incremental
backups
and
so
typically
the
first
time
you
use
rustic
to
backup
your
persistent
volume.
It
will
take
a
little
bit
longer
to
capture
all
of
those
contents,
but
then
on
an
ongoing
basis.
B
You'll
get
incremental
backups,
so
just
be
just
the
blocks
of
data
that
have
changed
or
the
files
that
have
changed
will
be
we'll
be
uploaded
and
so
related
to
that
Valero
supports
the
concept
of
pre
and
post
backup
hooks
that
can
be
executed
within
your
pods,
and
so
you
can.
You
can
run
whatever
commands
you
need
to
within
your
pod,
your
pod,
to
sort
of
help.
B
You
ensure
that
you
get
consistent
snapshots,
so
you
can
run
FS
freeze,
commands
before
backing
up
a
pod,
including
the
volume
and
then
run
an
FS,
basically
an
unfreeze
after
the
backup
or
if
you
have
application
specific
commands
that
you
need
to
run
to
quiesce
your
app
your
application.
You
can
do
that
before
and
after,
and
that
applies
for
both
snapshots
through
your
storage
provider,
as
well
as
for
rustic.
A
Another
clarifying
question
on
rustic
in
terms
of
incremental
nature
of
it,
so
is
it
full
plus
incremental,
and
is
that
you
know
after
after
the
full?
Is
it
forever
incremental
or
is
there
a
period
where
it
stops
being
incremental
and
it's
who
does
back
and
takes
another
foal
and
then
starts
doing
incremental
after
that.
B
Yes,
a
rustics
approach
is
to
the
first
time
it's
backing
up
a
particular
directory
or
a
particular
particular
volume.
It
will
take
a
full
backup
and
from
that
on,
if
the
the
rustic
repository
that
you're
backing
data
up
into
if
it
has
a
previous
backup
of
that
directory,
it
will
use
that,
as
as
the
basis
for
a
new
incremental
backup.