►
From YouTube: WebRTC WG meeting 2022-04-26
Description
See also the minutes of the call https://www.w3.org/2022/04/26-webrtc-minutes.html
02:47 WebNN Integration with real-time video processing
29:20 WebRTC Extensions
29:40 Issue #95
45:47 Issue #100
55:16 https://github.com/w3c/mediacapture-extensions/issues/47 Voice Isolation Constraint
1:04:27 support for contentHint in Capture Handle
1:16:11 WebRTC Extensions
1:16:23 Avoid user-confusion by avoiding offering undesired audio sources
1:38:25 Region Capture
A
B
A
A
A
I
can
do
that.
Okay,
thank
you
very
much
and
please
state
your
name
that
will
help
us
figure
it
out.
So
a
little
bit
about
document
status.
We
just
try
to
tell
everyone
that,
just
because
something's
in
a
w3c
rebound
doesn't
mean
it's
been
adopted,
we've
been
having
a
call
for
adoptions
on
this,
and
editors
drafts
don't
represent
working
group
consensus
working
group
drafts
do
and
it
is
possible
to
merge
prs
that
black
consensus.
A
If
you
attach
a
note
indicating
that
okay,
so
here
I
mentioned
what
we're
going
to
try
to
get
through
today,
it's
a
lot
of
stuff,
so
we
are
going
to
try
to
keep
time
fairly
strictly
and
I'll.
Try
to
do
it.
Maybe
harold
we'll
see
if
we
need
to
keep
on
track,
though
all
right.
So
first
item
is
m.
Webin
capture
transform
integration.
A
I
know:
do
we
do
you
wanna
present
this?
I
I
added
some
slides
just
for
background.
Maybe
I'll
present
those,
I
guess
dom.
You
opened
the
issue
on
november
10th
and
the
idea
was
to
build
a
prototype,
integrating
media
capture,
transform
with
tensorflow.js
background
blur
and
then
measure
performance,
and
the
focus
was
on
video
because
that's
where
we
think
the
the
issues
would
crop
up,
if
there
any
so
so
this
was
done,
and
this
is
what
a
discussion
of
what
it
all
means
is
coming
up.
A
So
if
you
look
at
the
thread,
there
are
several
issues
that
were
raised.
One
was
garbage
collection.
There
is
a
pr
that's
in
progress
about
that.
It
turns
out
that
it
helps
if
you
report
video
frame
external
memory
as
released
when
you
call
videoframe.close,
and
it
apparently
improves
the
garbage
collection
and
doesn't
create
as
big
a
spike
that
pr
is
not
merged.
Yet
so
you
wouldn't
see
that
another
thing
is
copy
removal,
and
I
guess
we'll
discuss
more
about
this.
A
A
A
G
Yeah
so
yeah,
so
my
name
is
ningxinhu,
I'm
working
for
intel
and
now
I'm
participating
in
the
double
swissy,
where
machine
learning
working
through
with
nc
there,
I'm
a
co-editor
of
the
our
webspec
there.
So
yeah
thanks
for
the
introduction
bernard,
so
I
think
for
yeah.
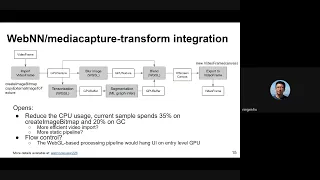
Actually,
this
slide
is
is
a
like
a
high
level
pipeline
and
some
components
there
to
build
up
this
video
processing
pipeline
specifically
for
the
background
blur
feature
there.
G
So
actually
the
boxes
here
actually
are
marked
with
some
some
like
gpu
texture
or
a
wix,
so
that
actually
this
is
a
web
gpu
version
with
weapon
capability
weapon
graph
interface
there.
So,
basically,
this
is
a
web
gpu,
plus
webm
processing
pipeline
and
in
the
screenshot
burner
just
show.
There
is
another
pipeline
that
using
webgl
for
the
processing
and
the
forza
pipeline's
segmentation,
and
here
the
the
ml
graph
infer
steps
in
the
pipeline
is
a
tensorflow
such
as
webgl
webgl,
backhand
there
so
yeah.
G
So
so,
basically,
so
this
pipeline
is
running,
we
have
two
versions:
one
is
running
in
the
mainstream.
Another
is
running
in
the
walker,
so
the
screenshot
and
the
other
link
just
shared
is
for
the
worker
but
the
best
case
pipeline
code
and
the
steps
are
same
so
yeah
so
in
in
the
transform
callback.
So
basically
we
got
the
video
frames
and
we
have
the
first
step
is
import,
that's
a
value
frame.
G
So
basically,
yes,
import
here
is
like
a
just
a
function,
but
actually
underlying
a
current
a
demo.
We
at
example
we
use
two
apis.
The
first
is
create
an
image
image
b
map
performs
at
the
video
frame.
Then
we
use
in
the
in
the
web
geocache
way.
I
use
the
the
texture
2d.
If
let
me
see
yeah
the
text
image
2d
to
upload
that
video
image
beam
map
or
to
a
web
geo
texture
and
in
the
web,
gpu
plus
weapon
case.
G
We
use
a
copy
external
image,
two
texture
api.
There,
then
we
have
a
gpu
texture
so
in
in
the
gpu
texture.
Basically
we
do
a
tool.
Processing
one
is
just
a
blur,
the
whole
image
and-
and
that
takes
a
video
frame
and
a
texture
and
and
apply
that
into
another
gpu
texture.
If
we
focus
on
here
the
webgpu
pipeline
yeah,
so
so
on,
another
pass
because
we
need
to
figure
out
which
pixel
is
the
background,
which
pixel
is
the
foreground
right.
G
So
we
first
we
need
to
run
some
machine
learning
models
here,
so
we
use
another
shader,
for
example,
in
this
english
pipeline
to
to
so-called
tensor
tensorize,
this
gpu
texture
into
into
a
tensor
that
can
be
taken
for
the
for
the
ml
execution.
For
example,
they
have
some
some
some
requirement
for
the
input
for
that
machinery
model.
G
So
we
need
that,
for
example,
do
some
normalization
and
some
turn
it
to
like
a
float
point
and
do
some
like
normalization,
the
something
like
this
so
yeah,
then
we
turn
into
all
this
pixel
in
the
texture
into
a
gpu
buffer.
Then
we
fill
that
into
the
webm
graph
here,
as
bern
mentioned,
the
way
depend
on
the
interoperable
api
between
webm
and
the
web
gpu,
so
the
webm
graph
there
can
take
a
web
gpu
buffer
as
an
input.
G
G
It
is,
for
example,
it's
a
background
or
it's
a
it's
another
object,
because
we're
using
a
deep
lab
of
history
model
that
can
tell
you
that
can
classify
that
each
pixel
into
up
to
20
21
classes.
So
if
I
remember
so
yeah
correctly,
then
another
shader
I'll
take
this
tool
together,
like
the
actually
the
three
inputs
together,
the
original
video
texture,
the
blurred
video,
the
gpu
texture
blur
the
texture
and
the
segmentation
map
and
based
on
that
to
to
create
to
carry
out
the
output.
G
That's
like
a
pixel
pixel,
a
pixel
from
from
the
origin
origin,
texture.
If
the
pixel
is
like
a
foreground
and
take
pick
up
the
pixel
from
the
blurred
texture.
If
this
pixel
is
classified
as
a
background,
then
this
all
seems
well
be
drawn
into
our
off-screen
canvas
at
the
last
stable
that,
after
this
all
done
so
this
example
will
and
create
a
video,
a
new
video
frame
from
this
canvas
and
feed
that
into
the
controller
that
passed
from
the
transform
callback.
G
Then
that's
the
best
case,
the
the
pipeline
yeah,
so
yeah
so
yeah.
So,
as
I
mentioned
that
the
the
the
webgl
pipeline
is
basically
similar,
but
the
segmentation
is
by
is
done
by
a
webgl
shader,
that's
implemented
by
tensorflow.js
webgl
backend,
and
there
is
also
to
do
that.
We
want
to
also
do
this
for
the
web
gpu,
because
tensorflow.js
also
has
a
web
gpu
backend,
but
due
to
some
gaps
there.
So
this
isn't
not
done
yet
will
be
down
at
the
next
step.
G
Yes,
the
some
bullets
here
share
that
we
basically
profile
the
the
the
sample
we
yeah
also
don't
address
that
there
looks
like
some,
not
so
very
low,
cpu
usage
there
and
no,
no
matter,
you
run
it
on
menstrual
or
in
a
walker,
so
yeah.
Basically
after
profiling,
we
see
that
there
are
like
a
35
percent
of
cpu
usage
in
this
in
this
sample.
Actually,
I
spent
on
the
cruise
image
map
and
another
20
spent
on
the
gc,
so
yeah
so
yeah.
G
G
There
are
I
I
was
told
there
are
copies
there,
because
there
are
some
like
color
convention
or
other
other
processing
that
turned
to
turn
our
video
frame
into
a
texture
with
the
cop
with
a
copy,
so
yeah,
so
that
that
maybe
one
area
we
want
to
improve.
I
was
told,
there's
some
new
api
like
import
external
image
to
texture,
something
like
this
we'll
be
introducing
web
gpu
as
an
extension
or
so
yeah.
G
So
we
will
test
that
out
if
it
is
in
place
and
and
also
on
the
on
the
cheesy
part,
so
yeah
burner
shared
that
there
are
some
effort
to
improve
the
video
firm
side.
Because
you
see
there
are
video
friends
and
we
got
a
video
friend
and
also
we
created
a
video
frame
as
and
right,
and
also
there
are
some
like
some
objects
allocated
to
to
to
run
this
web
gpu
pipeline.
G
For
example,
we
we
will
every
a
video
frame,
input
to
architecture,
we
create
a
view
and
also
we
rebounded
the
tools
to
the
band
group
of
the
web
gpu
pipeline
to
run
the
shader
so
yeah.
So
probably
there
can
be
improved.
That's
to
reduce
this
kind
of
dynamic
objects
allocation
during
this
process,
so
that's
another
area
and
probably
can
be
explored.
So
I
I
I
just
myself,
I'm
thinking
on
the
high
level
whether
we
can
have
some
like
some
some
configuration
or
a
setup
before
the
pipeline
running.
That's.
G
The
last
thing
is
about
some
some
some
performance
issue
I
observed
during
this
development.
I
observe
some
entry-level
gpu
that
should
run
the
webchild-based
pipelines
that
actually
put
a
high
pressure
on
the
gpu
for
this
like
for
this
pipeline,
so
it
may
cross
the
whole
browser's
browser's
hand
without
like
have
some
mechanisms
that
can
control
this
like
like
flow
control,
because,
for
example,
if
this
process
is
too
heavy,
it
probably
can
slow
down
the
frame
feeding
to
this
processing
pipeline.
So
yeah.
So
that's
the
thing
I
would
like
to
share
so
yeah.
A
G
H
Yeah
we've
got
got
two
queues,
I'm
probably
in
the
wrong
one.
So
just
I
know
this
is
very
subjective,
but
what's
the
was
the
performance
acceptable
like
do?
We
really
have
to
be
pushing
down
to
get
the
ex
the
performance
massively
better
or
or
is
this
like
in
the
right
ballpark,
and
we
just
need
to
tweak
it
a
little.
G
G
I
see
people
are
interested
that
how
this
is
like
a
video
processing
or
video
conference
application,
consume
your
power
or
or
drawing
your
battery
right,
so
so
that
that
thing
we
need
to
figure
out,
but
we
don't
know
that
yet,
but
maybe
dom
highlighted
the
emphasis.
The
cpu
usage
is
one
aspect
of
that,
so
yeah.
So
that's
my.
G
E
E
The
other
thing
we're
doing
is
evaluating
some
of
the
roadblocks.
Anyone
that
might
be
using
media
capture
transform
might
be
hitting
when
doing
video
processing,
in
particular,
when
trying
to
do
full
gpu
video
processing,
because
this
memory
copies
that
appear
here
are
not
specific
to
background
blur
or
to
machine
learning
processing.
They
are
really
anytime.
E
You
want
to
apply
some
gpu
processing
to
a
video
frame
and,
more
recently,
some
of
the
questions
around,
for
instance,
pixel
format
and
color
space
conversion
that
are
implicit
in
the
diagram
that
nintendo
presenting
have
surfaced
in
other
places
and
I
think,
will
impact
our
architecture
down
the
line.
So
that's
the
two
ways
I'm
looking
at
this
prototype
and
its
current
performance
results.
C
Yeah,
so
I'm
looking
at
the
gc,
which
is
20
and
so
on,
and
I'm
wondering
whether
that's
that's
something
that
is
like
that
can
be
fixed
by
implementations
underneath
javascript.
However,
there's
an
issue
with
creation
of
a
lot
of
objects,
very
repetitively
like
for
every
frame
you
you're,
creating
your
gpu
buffer
and
so
on
like
and
it's
happening
a
lot
and
what
you
usually
done
with
native
implementations.
Is
you
have
a
buffer
pool
and
I'm.
C
G
Yeah,
so
to
answer
the
first
question
that
the
gpu
buffer-
actually
I
allocated
before
the
processing
pipeline
running
so
basically
in
in
the
setup
stage.
So
all
the
gpu
buffers
are
allocated,
but
there
is
like,
as
I
mentioned,
that
there
are
some
theme
that's
created
for
everything
that
is
the
way
import
our
video
frame
into
our
gpu
texture.
Then
we
need
to
get
this
texture
and
vio,
and
the
band
into
the
like
the
band
group
of
that
processing
pipeline.
G
G
Probably
we
can
get
it
pre-allocated,
buffer
or
texture.
There
then
just
populate
that
buffer
without
creating
its
every
time.
Right
then,
the
gpu
I
mean
the
web
gpu
processing
pipeline
could
be
like
a
cool
lab
could
like
be
static
without
the
change
for
every
frame.
So
I
believe
that
will
avoid
many
new
objects,
location
so
yeah.
So
that's
my
take
so
I,
but
I'm
not
sure
that
underlying
implementation
side
optimization
would
help.
So
I
believe
so,
but
I
don't
have
a
many
experience
or
source
there.
So.
E
G
Hey
so,
oh,
there
are
two
two
items
currently
in
my
to-do
list.
One
is
like
to
enable
the
web
gpu
tensorflow.js
back
and
in
this
pipeline.
So
we
have
we
we.
We
can
understand
that
how
this
can
work
with
like
a
webgl.
We
already
have
that
and
work
with
the
pure
web
gpu
processing,
then
with
our
web
gpu
plus
weapons
there.
So
that's
one
thing,
so
we
have.
G
We
have
the
pr
in
working
progress
that
to
fix
that
in
the
tensorflow.js
webgpu
backend.
So
that's
one
item
another
one,
as
I
mentioned,
is
that
there
is
a
so
I
was
told
there
is
a
new
website
that
can
import
the
external
brand.
I
just
mentioned
that
to
import
a
video
frame
as
external
texture
to
to
to
to
web
gpu
so
yeah.
G
So
I
will
try
to
to
use
that
and
see
whether
we
can
reduce
the
the
the
image
bp
map
acosta,
which
cpu
to
see
how
how
far
we
can
go
and
yeah.
So
I
that's
the
immediate
two
steps
I
think
about
another
one,
probably
is.
We
can
also
measure
that
furnace
shares
that
p,
as
there
is
a
sale
in
chromium
that
to
fix
the
video
frame
or
improve
the
video
from
gc
scenario.
G
I
C
So
I
have
one
more
comment,
since
we
are
talking
about
cpu
efficiency
and
so
on
so
currently
you're
doing
ping
pong
between
main
thread
and
and
worker
fred.
So
I'm
guessing
that
it
might
be
small,
but
maybe
it's
not
negligible
as
well.
So
maybe
when
everything
will
be
done
in
a
worker,
you
will
transfer
the
the
mediastream
track
and
do
everything
in
a
worker.
Then
maybe
there
will
be
a
small
perf
improvement
as
well,
so
that
might
be
worth
experimenting
when
it's
available.
F
G
I'm
sorry
so
I
I
my
understanding,
we
we,
as
I
said
we
have
a
walker
version,
this
of
this
one,
so
in
zawa.
Actually,
I
believe
we
already
transferred
the
media
track
to
that
workers
and
all
the
like
a
process
is
happening
on
walker
in
walker,
without
transfer
objects
between
the
mainstream
and
the
worker
in
the
pro
in
the
processing
pipeline.
So
I'm
not
sure
is
that
you
suggest
that
we
we
do
or
or
we
we
already
have-
that
in
place.
So.
C
A
A
G
A
A
A
A
This
one
is
vp9
with
profile
id
one
and
then,
as
usual,
immediate
capabilities
you
put
in
the
width,
height
bit
rate
and
frame
rate,
and
then
you,
you
call
media
capabilities
in
this
case
the
decoding
side
and
you
get
back
a
result
and
your
rtc
rtp
media
capabilities
is
in
the
web,
rtc
codec
member.
So
this
is
basically
how
how
things
are
proposed
to
work.
B
A
A
So
here
are
the
here
are
the
questions
for
the
working
group,
so
you
know
basically
the
overall
question
is:
is
it
a
goal
for
media
capabilities
to
actually
encompass
get
capabilities
and
deprecate?
It
is
that
a
goal
and
if
so,
do,
should
media
capabilities
for
webrtc
provide
all
information
on
all
the
codecs,
so
telephone
event,
comfort,
noise
effect
rtx.
I
read
all
that
stuff
and
then
this,
if
it,
if
we
were
to
do
that,
would
the
results
make
sense.
A
C
F
B
C
C
For
instance,
it
is
a
synchronous
api
and
it's
it's
okay
with
cn
second
term,
because
they're
done
in
software
and
we
we
know
really
easily
whether
they're,
available
or
not,
but
for
hardware
codecs,
it's
more
difficult
to
do
that.
Synchronously
and
media
capabilities
being
promised
based
it's
a
bit
better.
So
that's
that's
my
answer.
So
no,
it's
not
a
goal
to
deprecate
it
to
fully
deprecate
it.
But
yes,
it's
a
goal
to
partially
duplicate,
get
capabilities.
K
E
I
Hey
sorry,
I
got
a
moment
away
from
my
kid
for
a
second.
I
just
want
to
say
that,
for
my
part,
is
the
media
capabilities,
editor
ewins
and
it
seems
like
you
and
and
sorry
I
forget.
The
name
of
the
person
who
just
spoke
are
mostly
aligned
and
I'm
I'm
fine
with
that
outcome.
For
media
capabilities
to
be
focused
on.
You
know
real
codex
if
you
will
and
to
leave
the
other
codex
to
the
domain
of
git
capabilities.
I
B
I
C
Yeah,
I
think
it's
a
desirable
outcome.
I
think
I
filed
an
issue
about
that.
So
it's
great
that
you're
working
on
it
and
yes,
we
should
be
able
to.
We
need
to
disambiguate
the
outcome,
because
it's
useful
for
webrtc,
but
it
might
be
also
useful
in
the
future
for
web
codex
plus
web
transport
for
webrtc,
like
applications
as
well.
To
get
back
to
florence
point
about
being
able
to
list
all
video
codecs
or
all
audio
codecs.
That
webrtc
supports.
I
think
it's
a
non-goal.
C
We
want
to
move
away
from
that.
Media
capabilities
is
really
about
you
as
an
application.
You
have
you're
an
sfu,
so
you're,
probably
supporting
a
few,
a
few
codecs
and
that's
the
ones
you
actually
want
to
to
check
with
media
capabilities.
It
will
be
a
few
calls
for
media
capabilities
and
you
have
promised
all
that
will
solve
most
of
the
issues
there.
So
I
don't.
C
A
usability
trouble
for
sfu
applications
for
peer-to-peer
cases.
I
would
think
that
you
might
not
need
set
codec
preferences
at
all,
because
you
want
to
expose
all
codecs
and
then
vsdp
negotiation
to
happen
and
pick
the
best
codec
between
the
two
peer-to-peer
endpoints,
so
that
that's
why
I
think
that
not
exposing
get
capable
real
codex
in
get
capabilities.
C
A
I
think
we
it
sounds
like
we
got
an
answer
to
the
questions
on
this
slide,
which
is
that
media
capabilities
doesn't
have
to
provide
information
on
all
the
fake
codecs
and
it's
not
a
goal
to
deprecate
capability,
get
capabilities
or
get
rid
of
get
capabilities,
but
just
to
provide
enhanced
info.
So
I
think
we
can.
We
can
move
on
to
issue
100.
E
D
D
D
D
K
And
I
would
say
that,
yes,
as
you
mentioned,
you
enjoys
two
different
scenarios
where
people
would
use
subcorrect
preferences.
One
would
be
when
a
peer
is
talking
to
an
sfu,
and
in
this
case
you
want
you
know
which
codecs
you
would
target,
and
then
you
can
make
specific
queries
to
medicare
capabilities.
K
If
I
understood
you
correctly
in
the
peer-to-peer
scenario,
you
might
have
a
different
behavior
and
I
believe
right
now,
if
you're
not
able
to
enumerate
all
the
codex,
you
will
not
be
able
to
call
set
correct
preferences.
Really,
you
would
need
to
hard
code
a
list
of
codecs
for
that
you
would
need
to
check-
and
I
don't
think,
that's
really
usable
and
we'll
need
something
different.
A
L
No,
I
mean,
I
think,
that
I
just
wanted
to
ride
the
issue
I
mean
because
I
see
the
sdp
was
huge
and
I
think
that
as
people
as
phillips
has
said,
this
has
very
or
similar
to
to
what
we
have
in
the
header
extension.
So
probably
we
can
reduce
or
use
a
similar
api
in
both,
but
I
don't
have
any
preference
of
the
over
the
solution
that
we
could
implement.
E
C
Yeah
in
general,
I
think
it
might
be
fine.
My
main
worry
is:
what
are
what
are
the
defaults?
Would
would
they
be
the
same
for
all
browsers
and
some
sombra?
Some
codecs
are
now
the
default,
but
but
at
some
point
we
might
want
to
make
them
off
of
by
default
like
legacy
codecs
and
so
on.
So
how
do
we
envision
this
evolution
and
this
this
might
create
web
compat
issues
as
well?
L
L
C
Just
to
mention
that
the
case
where
what
I'm
worrying
is
the
peer-to-peer
case
where,
if
the
defaults
are
different
between
two
user
agents
at
some
point,
even
though
both
user
agents
are
supporting
h264,
for
instance,
they
will
not
use
it
because
one
is
off
by
default
and
not
the
other
one,
and
there
will
be
no
available
video
codecs
that
are
in
common
in
vsdp.
So
that's.
B
L
But
I
think
that
here
at
least
my
proposal
was
to
have
by
default
in
the
offer,
but
if
you
receive
it
in
the
in
the
offer,
you
can
add
it
in
the
in
the
answer.
So
it
is
just
what
the
codes
do.
You
do
you
and
you
provide
in
the
offer.
So,
for
example,
in
in
this
case,
if
you
receive
an
offer
within,
I
will
say
it:
bpm
bp9
profile,
3,
and
you
will
be
able
to
to
answer
that
in
the
in
the
in
the
in
the
answer.
But
you
will
not
offer
it
by
default.
L
L
E
D
So,
looking
at
the
way
this
is,
you
need
two
interfaces.
One
is
the
the
list
of
co
of
codecs
you're
currently
willing
to
offer,
and
one
is
the
set
of
codecs
that
you
can
offer
where
you
get,
capabilities
probably
suffices
for
the
first
one
and
the
and
the
one
on
the
screen
probably
suffices
for
a
second
and
offer
by
default
is
not
needed
when
you
have
codecs
to
offer
it's
simply
what
codecs
to
offer
in
this
class
too,
and
as
for
the
interoperability.
D
K
L
L
Yeah
but
but
I
mean
maybe
we
can
just
add
the
header
extension
to
the
preferences
or
something
like
that.
I
mean
what
I
would.
I
think
that
it
would
be
good
is
to
have
the
same
way
to
enable
or
very
similar
apis
to
and
to
set
what
codes
are
being
offered
and
one
header
extension
and
not
have
two
different
completely
different
apis
for
that
yeah.
A
J
J
J
A
J
A
D
D
D
D
Let's
define
a
new
boolean
constraint,
either
true
or
false,
and
if
it's
true
define
the
result
as
attempt
to
remove
everything,
that's
not
a
human
voice
may
also
include
attempt
to
find
the
most
important
voice
and
enhance
that
which
might
be
the
the
guy
in
the
middle
of
the
camera.
It
might
be
the
guy
who's
tallest
or
the
one.
D
The
one
who's
been
given
the
floor,
that's
quality
of
implementation,
but
we
need
to
have
a
way
to
for
the
application
to
say:
hey
user
agent
help
me
isolate
just
a
voice
and
everything
you
can
throw
away.
That
is
not
voice,
whether
it's
doritos
chips
or
keyboard
clicks
or
the
siren
of
a
police
car
going
by
just
get
rid
of
it.
D
D
D
D
E
C
I
think
I
think
it
makes
sense,
but
we're
doing
that.
I
think
it's
really
reasonable
to
ignore
noise
separation
so
which
would
mean
that
you
ignore
it
like
before
playing
constraints
or
before
selecting
devices
and
so
on.
There's
echo
cancellation
as
well.
So
all
there
are
like
various
properties
for,
but
which
are
bricks
that
you
put
in
the
audio
pipeline
and
I'm
wondering
whether
some
of
them
are
can
be
done
serially
or
in
parallel
or
not,
and
one.
A
C
D
D
C
My
immediate
thought
on
this,
so
you,
you
would
be
able
to
say
echo
cancellation,
false
and
voice
separation-
true,
for
instance,
yes,
okay,
and
vice
versa,
I'm
guessing
some
implementations
might
might
find
it
hard
to
have
all
the
equations,
like
all
four
all
four
values,
implementable
and
we
don't
have
a
good
way
of
exposing
these,
these
kind
of
constraints
there,
except
by
having
applied
constraints,
rejecting
which
is
which
is
a
bit
sad.
So
it's
another
issue.
I
have
with
constraints,
I
guess,
but.
C
B
D
D
C
D
E
Yeah
we
haven't
done
so,
I
think
very
consistently
for
constraints,
but
I
wonder
if,
instead
of
a
boolean,
a
set
of
string
values-
and
that
gives
us
more
flexibility,
one
could
be
voice,
oscillation,
disabled
and
but
for
enabled
values.
I
could
be
a
single
speaker,
multiple
speakers,
and
there
could
be
variation
on
that
I
mean
I
I'm
not
aware
enough
of
the
various
ways
this
could
be
optimized,
but
boolean
has
no
extensibility
strings,
on
the
other
hand,
will
bring
us
potential
new
values
over
time.
D
B
M
You
of
the
two
features
so
number
one:
we've
got
content
hint,
so
in
a
perfect
world,
you
always
have
enough
bandwidth
to
send
at
the
top
possible
frame
rate
and
resolution,
and
everything
is
just
perfect,
but
we
don't
live
there,
and
so
it
happens
that
we
sometimes
need
to
sacrifice
one
if
not
both
and
which
one
is
preferable
to
their
grade.
First
depends
on
the
context.
So
if
you
know
that
you're
sending
text.
L
M
It's
exposed
on
track,
and
if
you
set
it
to
text
then
when
the
bandwidth
is
not
sufficient,
you
first
degrade
the
frame
rate
and
vice
versa,
not
vice
versa
and,
conversely,
for
motion,
you
first
degrade
the
resolution
and
only
later,
the
frame
rate
next
slide.
Please
now.
The
second
mechanism
we
have
is
called
capture,
handle
identity
and
that
one
allows
a
captured
tab
to
declare
its
identity
in
a
free,
free
kind
of
way,
any
string
that
it
would
like
and
it
can
expose
its
origin
etc.
M
So
I
think
that
by
now
it's
kind
of
obvious
how
we
could
marry
these
two
next
slide,
please,
namely
when
you
capture
something
and
you're
just
about
to
transmit
it.
If
you
were
to
know
what
you're
capturing
you
would
know
how
to
best
encode
it,
whether
you
want
to
optimize
for
resolution
or
for
frame
rate,
and
the
problem
is
that
unless
you
inspect
the
frames
and
even
when
you
do
you
don't
exactly
know
what
you're
capturing
enter
capture
handle
identity.
M
So,
for
example,
if
right
now
we're
in
meet,
if
I
were
to
capture
a
tab
with
slides,
then
the
slides
could
say:
you'd,
better
you'd,
better
optimize
for
text,
and
if
the
slide
knew
that
it
was
going
to
embed
a
youtube
video,
then
it
could
say
promotion
and
there
is
a
bit
of
a
zelda
code
over
there,
and
I
think
it's
relatively
clear,
it's
inside
of
the
green
rectangle.
So
basically
the
capturer
says
hey
what
is
suggested
and
if
I
trust
this
particular.
M
Tab
or
if
I
don't
care,
if
I
trust
everybody,
then
I
just
set
that
and
that's
it,
that's
the
suggestion
and
next
slide.
Please
one
thing
to
keep
in
mind
is
that
if
we
accept
this,
we
probably
also
want
to
make
sure
that
set
capture
handle
config
can
be
called
more
than
once,
which
is
a
point
of
slight
contention
between
between
us
and
the
reason
is
that
content
can
change
so,
for
example,
slides
sometimes
can
embed
text
and
sometimes
can
embed
videos
next
slide.
Please
discussion.
C
So
I
think
that
the
setting
the
track
hint
is
unnecessary
because
if
a
capture
is
is
setting
the
hint
on
on
its
side,
saying
hey,
I'm
a
page,
I'm
text,
then
the
user
agent
knows
that
it's
capturing
that
the
track
is
capturing
a
page
that
says
that
it
is
text,
and
so
it
already
knows
the
hint.
So
there's
no
need
for
a
capture
to
know
to
actually
know
the
hint.
C
The
hint
might
only
be
interesting
if
you're,
using
something
like
web
codec,
where
maybe
in
that
case
the
user
agent
has
not
control
of
the
the
encoder
and
so
might
it
might
become
useful.
But
I
I
don't
think
that
for
webrtc
I
don't
think,
there's
a
there's
a
need
and
it
might
actually
be
a
bit
sad
that
applications
would
have
to
say
track
content
hint
equals
something
it
should
be
automated.
It
should
be
the
user
agent.
That
would
say:
oh
I'm,
encoding
a
frame
that
was
labeled
as
text
so
yeah.
M
C
M
Okay,
so
that
means
that
basically
either
the
user
agent
always
believes
the
hint
the
suggested
hint
or
never
right,
because
the
user
agent
is
not
going
to
give
differential
treatment.
Whereas
if
you
expose
it
to
the
capturing
application,
it
can
decide
whether
it
wants
to
act
on
this
suggestion
or
ignore
it,
because
it
could
be.
C
Yeah,
the
usual
agent
has
access
to
video
frames,
so
I
guess
but
based
on
the
output,
it
might
say:
oh
no,
it's
not
good,
or
I
don't
know
but
yeah.
I
think
that
it
kind
of
makes
sense,
but
you
well,
you
have
a
point,
but
maybe
I
do
not
see
how
the
capture
would
know
better,
whether
to
use
the
hint
or
not.
M
That's
the
second
thing
you
also
mentioned
auto
detection.
As
far
as
I
understood
so
back
on
the
how
the
user
agent
versus
the
capturing
application,
which
one
has
more
information,
the
capturing
application
can
check
the
origin
and
if
it's
an
origin
that
it
allows
listed,
it
can
say:
okay,
I'm
going
to
take
this
suggestion
and
if
it
has
not
allow
listed
it
or
even
block
listed
it,
then
it
can
just
ignore
the
suggestion
and
that's
how
the
capturing
application
could
have
more
information
and
for
auto
detection.
M
So,
for
example,
if
I've
got
a
video
plane-
and
I
know
that
I'm
only
going
to
play
one
second-
then
I
am
not
going
to
change
the
suggestion,
but
the
user
agent
might
not
know
that
all
the
application
has
some
javascript
code.
That's
going
to
stop
the
video
one
second
after
so
it's
gonna,
you
know
oscillate
between
text,
motion
text
and
that
might
not
be
preferable.
So
in
general
I
prefer
to
have
more
flexibility.
C
A
So
I
had
a
comment
on
the
web
codex
case,
so
un
web
codex
doesn't
automatically
consume
content
hints
webcodex,
considers
content
hints
to
be
generic
higher
level
information
which
the
application
has
to
translate
into
specific
encoder
settings.
So
it's
not
something
that
you
could
give
to
the
user
agent.
The
application
would
actually
need
to
know
it.
The
capture
would
need
to
know
the
the
hint
and
then
it
like
as
an
example.
A
C
E
M
Right
that
is
correct,
so
we
already
have
set
capture,
handle
config
and
that
one
currently
just
accepts
origin
exposed
or
not,
and
an
arbitrary
string
of
the
identity,
and
I
suggest
that
we
add
one
more
field
and
that
field
is
is
called
suggested.
Content
hint
and
it
can
only
accept
you,
know,
strings
which
are
valid
continues.
B
Right,
so
what
I
would
propose
there
is
that
getting
that
information
from
the
captured
application
to
the
user
agent
at
least
sounds
valuable,
and
in
that
case
the
user
agent
could
do
this
automatically,
at
least
for
the
case
where
webcodex
is
not
used
and
for
web
codecs.
It
sounds
like
we're
talking
about
exposing
metadata
of
the
capture,
so
I
have
some
slides
which
we
probably
won't
get
to
today,
but
that
has
a
capture
capture
controller
that
might
be
a
good
place
to
surface
that
kind
of
information
which
would
be
similar
to
so.
B
B
M
So
here's
just
a
wall
of
text
that
basically
says
currently,
when
you
ask
for
a
screen
share,
you
can
say
that
the
web
application
can
say
that
it
also
wants
audio,
but
that's
a
bit
too
coarse,
because
sometimes
it
only
won't
stab
audio
but
not
system
audio.
For
example,
if
a
video
conferencing
application
might
decide
that,
okay,
if
it's
another
tab,
then
it's
very
easy.
M
I
can
just
transmit
that
remotely
no
echo
it
works,
but
if
it's
system
audio
echo
cancellation
might
not
work
as
well
as
it
wants
as
it
needs,
and
it
might
not
want
to
even
ask
for
it.
The
problem
is
that
currently
we're
kind
of
forcing
the
application
to
ask
for
both
and
users
sometimes
go
and
actually
try
to
turn
on
system
audio
and
when
the
application
just
ignores
that
audio
and
does
not
transmit
it
remotely
users
get
confused
next
slide.
Please
so
we
see
here.
This
is
how
it
looks
in
chrome.
M
Ideally,
we
only
want
we
want
to
to
allow
separate
controls
for
whether
the
checkbox
should
prompt
the
user
for
that
on
the
left
and
on
the
right
independently.
Next
slide,
please
same
thing.
So,
oh
sorry,
this
in
this
slide.
So
here
is
one
suggestion
of
how
we
can
do
that.
Could
you
could
you
please
reload
the
page
bernard.
M
M
Yes,
my
apologies
for
making
it
a
bit
harder
by
making
the
last
moment
change.
So
just
an
idea.
It
doesn't
have
to
be
exactly
this
api
shape,
but
that's
one
api
shape
we
can
have,
we
can
save
desired
sources
and
then
the
user,
the
web
application
can
say.
Okay,
I
only
want
browser
and
then
it
gets
what
we
see
here
or,
alternatively,
browser
and
monitor
just
monitor,
etc.
H
H
H
M
You're
right
that
this
was
not
the
optimal
example,
but
in
that
case
at
least,
you
would
avoid
asking
for
audio
and,
if
you're
capturing
the
entire
system,
but
you're
right
that
this
is.
It
is
not
easy
for
me
to
come
up
with
credible
examples
of
how
you
would
handle
it
of
other
applications.
That
would
really
need
this,
except
for
video
conferencing.
M
H
M
B
Yes,
so
I'm
actually
supportive
of
avoiding
capturing,
I
would
actually
prefer
browsers,
never
captured
system
audio,
because
I
feel
that's
a
big
privacy
issue
that
users
are
not
aware
of.
So
something
like
this
might
be
desirable.
I
was
wondering,
but
instead
of
creating
a
new
constraint,
I
feel
like
we
already
have
one
that
we
could
use
here,
which
is
called
the
display
surface.
I'm
wondering
if
you
thought
about
reusing
that
here
and
because
we
have
a
similar
debate
about
display
surface.
M
B
M
B
B
M
E
If
we
don't
include
monitor
in
the
list
of
supported
items,
that
doesn't
mean
you
couldn't
capture
it.
If
you
don't
specify
anything,
there
may
still
be
the
capture
system
audio
option
in
the
ui,
but
you
can't
ask
specifically
for
system
audio
as
a
new
feature
that
this
api
would
expose.
Is
that
what
you're
saying
anywhere.
B
Yes,
so
I
mean
chrome
is
still
fine
to
implement
it.
The
way
it's
doing
now.
It's
just
don't
want
this
to
become
a
web
compat
issue
where
applications
are
starting
to
depend
on,
let's
say
browsers
in
the
future,
want
to
change
their
default
to
not
include
system
audio.
This
shouldn't
be
a
way
to
request
it.
E
E
E
B
C
M
I
think
that
eventually
some
browsers
are
going
to
support
capturing
window
audio
as
well,
and
in
that
case
I
want
applications
to
be
able
to
specifically
say
whether
they
want
that
or
not.
I
don't
see
a
reason
to
only
go
for
tab.
I
understand
about
system
audio
and
I
think
that
it's
a
reasonable
compromise
to
say
that
if
you
don't
specify
any
desired
sources,
you
get
all
of
them
like,
if
you
just
say
audio
true.
B
E
That
just
so
that
it
sounds
like
what
we
have
in
fact
is
not
so
much
that
you
want
to
specify
your
display
surface,
but
whether
the
audio
source
is
strongly
tied
to
the
display
surface.
You've
picked
or
not,
and
I
don't
know
that
it
makes
sense
to
say
browser
or
window,
because
in
fact
you
would
only
pick
one
of
those
display
surface
in
the
end.
So
it
may
be
that
what
we
are
saying
is
audio
source
displays
your
face
or
audio
source,
anything
which
would
open
for
system
audio
anyway.
B
The
weird
part
here
is
that
the
correct
answer
to
specify
this
to
avoid
system
audio
is
a
bit
convoluted.
You
have
to
say
desired
sources,
or
you
would
also
you
have
to
remember
to
always
include
browser
and
window
just
in
case
a
browser
in
the
future
decides
to
add
the
audio
window
right,
but
it's
perhaps
a
less
ideal
surface
if
that's
the
main
goal,
so
maybe
something
more
specific
like
avoid
system,
audio,
true
or
false,
would
be.
C
I
think
that
yeah
sorry,
it
seems
to
me
we
we
should
continue
this
discussions
on
github.
It
seems
that
the
scoop
is
not
yet
very
clear
as
well,
whether
it's
tab,
whether
it's
system,
audio
and
so
on.
So
that's
the
first
thing
that
should
be
done,
it's
the
scope
and
then
once
the
scope
is
clear
and
those
consensus
moves.
M
A
C
E
C
B
C
C
So
the
good
thing
about
having
separate
properties
separate
constraints
is
that
then
the
user
agent
say
hey,
I'm
supporting
the
this
property,
which
might
say:
oh,
oh
you're,
actually
supporting
a
recording
window.
For
instance,
audio
of
a
window.
Oh
you're,
supporting
a
recording
audio
of
the
system,
oh
you're,
supporting
a
recording
audio
of
tab
and
currently.
C
M
H
D
D
H
But
if
you
knew
that
echo
cancellation
would
work,
then
maybe
you
want
window
and
if
you
know
that
it
don't
doesn't,
maybe
you
don't
want
to
offer
it
like
that.
The
way
this
was
presented,
and
certainly
from
my
experience,
the
reason
you
don't
want
people
to
pick.
This
is
because
it
sounds
terrible,
or
at
least
in
in
large
part.
So
right,
I
feel
like
we
by
not
exposing
that
we're
kind
of
in
in
in
the
constraint
we're
kind
of
hiding
pretending
the
problem.
Isn't
the
problem
where.
M
It
really
is
well
we're
addressing
the
problems
that
we're
able
to
address
right
now
when
we've
got
imperfect,
echo
cancellation,
that's
number
one
and
number
two
is
we
don't
need
to
do
everything
with
one
api
right,
so
an
application
could
using
a
different
api,
find
out
okay,
but
which
sources
would
be
echo
cancelled
well,
and
then
it
could
request
those
or
if
it's
got
other
criteria
for
making
a
decision
about
which
sources
it
wants
it
can.
You
know,
use
both
sources
of
information
to
make
the
decision.
H
But
the
other
thing
that
can
go
bad
is
is
er
cancelling
and
the
browser
the
user
agent
is
conscious
of
what
it's
currently
capable
of,
and
therefore
that
information
is
already
visible
to
it
and,
frankly
to
nobody
else,
and
so
I
I
contend
that
it
would
be
really
useful
to
allow
that
hint
to
cover
this.
The
explicitly
cover
the
can
it
be
echo,
cancel
properly
or
not.
M
H
B
Yeah,
so
I
think
we
have
the
res
the
situation
that
I'm
concerned
about
is
if
this
api
surface,
as
described
right
here,
would
appear
to
allow
someone
to
pass
in
only
the
monitor
value
and
thus
be
able
to
sway
the
user
to
picking
a
full
screen
capture
when
they
otherwise
would
have
picked
a
tab
capture.
That
would
be
really
bad.
So
as
long
as
we
can
have
some
language
to
prevent
that,
I
don't
think
I
care
that
much
about
the
api
surface.
B
C
Okay,
so
crop
target
and
region
capture
is
a
new
new
api
and
it's
activating
actively
being
developed
in
chrome,
so
it
we
have
some
issues
that
might
have
an
impact
on
api
shape
and
it
would
be
great
if
we
could
have
an
understanding
of
the
api
shape
as
soon
as
possible.
So
there
are
like
three
different.
There
are
four
issues,
but
three
of
them
are
being
discussed
right
now.
One
is
whether
we
want
to
expose
the
creation
of
crop
target
either
to
elemental
media
devices.
C
C
So
first
issue
is
whether
we
want
to
attach
the
api
to
element
itself
or
media
devices.
So
a
crop
target
is
basically
an
object
that
is
encapsulating
a
pointer
to
an
element,
a
remote
identifier
of
an
element,
so
we
could
either
call
element.getcroptarget
and
then
you
you
get
your
crop
target
or,
as
it
currently
done
in
chrome,
port
type.
You
would
call
something
like
navigator,
dot,
media
devices,
the
produce
scroll
target
and
pass
the
element
as
a
parameter.
C
C
The
advantages
for
element
is
first
in
terms
of
documentation,
search
ability.
We
we
already
have
partial
interfaces
so,
for
instance,
there's
element
request
full
screen
and
request.
Full
screen
is
a
kind
of
media
api
and
it's
it's
okay,
to
put
it
directly
on
the
element,
because
it's
tied
to
the
element
itself
and
the
second
bonus
is
that
the
element
and
the
crop
target
are
tied
together,
but
they
are
not
tied
to
the
media
devices
itself
and
by
putting
it
at
the
element
level
and
not
the
media
devices.
C
For
instance,
media
devices
is
attached
to
a
single
document,
so
you
could
call
media
devices
for
the
scroll
target
on
an
element
that
is
not
attached
to
the
same
document
as
the
media
devices
object,
and
this
might
have
an
impact.
For
instance,
the
media
devices
might
be
neutered
if
its
own
document
is
detached
and
then
it
would
throw
or
it
would
reject
the
promise.
Even
though
the
element
is
perfectly
fine
and
of
course,
an
element
might
be
added
or
removed
from
documents.
C
The
third
point
is
that
meta
devices
is
secure.
Context
and
element
is
not,
and
you
might
still
want
to
create
a
crop
target
for
an
element
in
non-secure
context.
That's
still
something
that
might
be
possible
to
use.
So
my
recommendation
is
to
move
to
element
because,
as
I
said,
there's
not
a
lot
of
downsides
and
it
seems
easier
to
just
call
get
crop
target
without
any
any
paradigm
fruits.
B
M
Yes,
I'm
voting
for
media
devices
and
the
reason
is,
as
you
have
stated,
that
it
is
right
next
to
get
display
media
it
provides
nice
encapsulation
of
related
apis
and
right
now,
element
has
you've
chosen.
One
example
of
something
that
is
exposed
an
element.
The
problem
is
that
you've
got
hundreds
of
examples.
I
think,
because
there
are
so
many
things
that
are
currently
exposed,
an
element,
and
I
think
that
that
is,
it
would
be
good
to
stop
that.
C
C
Quote
target
is
used
by
media
stream
track.
It's
not
used
by
get
display
media,
for
instance.
So
I
do
not
see
why
media
devices
is
tied
to
to
do
that
and-
and
it's
really
tied
to
to
an
element
not
to
its
many
devices.
So
I
would
prefer
that
you
prefer
to
have
some
quirks
for
a
benefit.
That
is
what
you're
claiming
documentation.
M
So
you've
made
two
claims
here:
number
one.
It
is
actually
related
to
get
display
media
because
you
can
only
crop
something
that
you
got
through
get
display
media
and
that's
why
it
needs
to
be
adjacent
in
my
mind,
and
the
number
two
is
that
there
don't
necessarily
have
to
be
any
side
effects
to
putting
it
on
midi
devices
because
call
it
on
with
one
midi
devices
or
call
it
with
another.
M
M
C
C
I
believe
that
if
media
devices
is
neutered,
so
if
its
document
is
detached,
you
will
have
difficulty
shipping
anything
but
rejecting
the
promise,
because
that's
something
that
is
very
natural
and
is
being
used
a
lot.
So
it
would
be
counterintuitive
to
actually
undo
current
chromatin
chrom's
behavior
and
do
what
you're
suggesting.
C
B
Yeah,
oh
no
yeah,
I
was
hoping
others
would
have.
I
just
want
to
say
that
I
don't
see
that
the
media
devices
object
has
anything
to
do
with,
what's
being
captured
on
the
captured
site
right.
This
is
where
we're
in
this
could
be
a
page
that
doesn't
even
have
https
so
yep,
and
so
let's
see
here,
stick
your
context.
Yes,
so
this
seems
like
a
no-brainer
to
me,
I'd
like
to
hear
how
we
would
we
would
solve,
and
why
are
we
not
concerned
about
capture
of
non-secure
context.
M
I
don't
think
that
non-secure
contexts
are
very
interesting
use
cases.
I
think
that
those
are
disappearing
quickly
and
I
don't
think
that
anything
that
you
get
from
a
non-secure
context
should
even
be
trusted
in
any
way.
So
when
you
get
a
crop
target
from
that,
I
would
just
ignore
it.
If
I
were
a
well-structured
application.
E
I
mean
I
I'm
not
very
deep
on
the
topic,
but
I
I
tend
to
agree
that
element
feels
like
a
more
natural
target,
if
only
because
what
you're
really
doing
is
getting
when
you,
you
don't
even
have
to
pass
the
element
as
a
parameter
as
a
result
and
yeah
right
now.
I
guess
I
I'm
not
finding
a
lot
of
strong
advantages
to
using
media
devices.
I
I
think
the
ergonomic
argument
plays
both
ways
so.
C
J
M
Not
really,
but
I
will
check
to
see
whether
it
is
something
that
we
could
compromise
on,
if,
though,
so
we
can
continue
on
github
or
get
back
to
this.
I
also
think
that
this
is
not
the
most
important
issue
that
we
have
here
because
worst
case
scenario.
If
we
change
the
decision
later,
it's
not
a
difficult
transition
to
say:
okay,
we
also
expose
it
to
an
element
and
then
to
say
a
bit
later
and
now
we
only
expose
it
to
an
element.
B
M
C
C
So
there
are
two
things
there:
if
you're
using
an
attribute,
then
you're
somehow
mandating
that
the
symbol
single
crop
target
is
generated
by
by
element.
So
while
for
a
method,
the
usual
thing
that
happens
is
that
you
will
get
a
different
target
every
time
you
call
the
method,
that's
typical
from
for
web
apis,
which
means
so
one
thing
to
note
is
that
it's
already
possible
to
generate
several
crop
targets
that
will
reference
to
the
same
element
given
crop
target
is
serializable.
C
L
M
So
I
would
go
with
the
method,
and
the
reason
is
that
there
could
be
a
cost
to
actually
doing
that
and
they
want
to
dissuade
applications
from
just
inspecting
that
for
no
reason
and
the
way
that
there
is
a
cost
for
this,
is
that
currently
what
we
do
is
as
soon
as
you
meet
the
crop
target.
We
mark
the
element
throughout
the
rendering
pipeline,
and
that
means
that
the
element
gets
rare
data.
M
Like
that
yeah,
the
lazy
tagging
would
not.
Actually,
if
we
put
things
on
element
itself,
then
lazy
tagging
would
be
okay,
it's
a
bit
of
a
longer
discussion
because
it
also
depends
on
which
document
it
is
and
then
when
the
element
gets
moved.
Okay,
because
basically,
what
you're
saying
is:
if
you
do
lazy
tagging,
then
you
don't
actually
take
the
element.
You
just
put
the
tag
on
the
document
itself.
M
B
B
We
should
prefer
simple
solutions
and
the
way
I
view
simplicity
is
mostly
to
prefer
the
priority
constituencies
being
the
user
and
the
web
developers
and
all
the
concerns
we've
heard
so
far
to
pick
something
other
than
that
have
been
implementation,
concerns
which
I
think,
as
long
as
this
is
implementable,
the
right
way
we
should
implement
it.
The
nicest
simplest
api.
M
I
just
want
to
say
that
I
see
the
constituencies
as
a
weighted
average
and
not
as
a
you
know,
first-past-the-post
kind
of
thing.
I
think
that,
yes,
it
is
important
users,
don't
care
here.
Web
developers
barely
care
about
these
small
differences.
It's
going
to
be
equally
useful
for
them
anyway.
So
then
it
actually
matters
a
lot
for
implementation.
D
I
just
want
to
make
sure
that
I
have
said
that
I
disagree
with
yaniva
on
every
single
point
I
think,
get
I
think,
messing
with
element
is
bad
for
the
web
platform.
It's
already
it's
already
doing
far
too
much.
It's
a
god.
It's
a
god
object
and
the
exposing.
The
fact
that
that
these
mechanisms
have
costs
is
a
guy
is
a
guidance
to
the
users
that
to
towards
don't
don't
use
them.
If
you,
if
you
don't,
if
you
don't
want
to
pay
that
costs
and
doing
the
promise
is.
D
D
B
All
right
I'd
like
to
respond,
so
I
basically
disagree
with
what
everything
harold
said.
So
the
the
cost
here
sounds
like
it's
in
chrome,
there
shouldn't
be
a
cost.
I
think
that's
a
bug,
because
the
real
name
for
this
should
really
be
to
isolate
properties.
Here,
the
attribute
should
be
really
transferable
reference.
That's
all
it
is
because
the
element
itself
it
wouldn't
be
needed
if
we
could
reference
the
element
directly
so
and
that
should
not
be
a
costly
operation.
B
This
is
just
so
that
we
have
something
to
pass
to
a
different
process
that
might
be
calling
crop
to
where
the
crop2
method
is
asynchronous,
and
so
there's
all
the
time
in
the
world
at
that
level
to
inspect
these
these
elements,
which
they
really
are,
whether
you
know
them
through
a
reference
object
like
this,
which
is
really
what
it
is.
So
there's
really
no
need
for
for
a
promise
or
a
method,
or
for
this
to
be
on
media
devices.
C
C
So
if
you,
if
you
look
at
what
web
ap
how
web
apis
are
consistent,
and
if
we
want
to
keep
consistency
between
these
api
and
the
other
web
apis,
then
we
should
use
what
other
apis
are
doing
and
over.
The
good
thing
about
other
apis
is
that
they
are
implemented,
and
we
know
for
sure
that
it's
feasible
to
to
do
without
too
much
implementation
issue
dominique
dumb
you're
on
the
view.
E
C
M
No,
no,
no,
because
right
now,
if
I
it's
the
other
way
around,
if
I
have
a
crop
target
and
they
post
it
and
it
exposes
more
information
in
the
future
than
me
as
a
web
developer.
Who
currently
saw
that
it
was
not
exposing
any
information
and
I
tested,
and
I
thought
I
was
safe
in
the
future.
Suddenly
it
turns
out
that
they
passed
more
information
than
I
intended
for
information.
C
It
might
be
used
in
places
you,
you
might
not
have
thought
it
would
be
used.
Yes,
and
if
we
change
the
name
and
we
change
the
the
way
we
look
at
that,
then
we
should
take
that
into
account.
Thinking
yeah.
There
might
be
new
apis
new
places
and
it
should
be
safe,
that
should
it
should
be
safe
to
use
the
same
object
on
on
the
two
apis.
B
D
If
we,
the
one
problem
here,
is
that
you're
suggesting
inclu,
suggesting
and
creating
a
completely
general
mechanism
that
can
have
many
possible
possible
applications
and
using
that
as
as
and
which
can
have
lots
of
implications.
That
cannot
be
evaluated
because
they
don't
exist
yet
and
using
that
to
block
a
very
narrow
and
specific
interface
that
is
going
to
be
used.
For
one
thing,
only
I'm
not
sure
where
we
are
the
right
group
to
and
to
introduce
very,
very
wide
wide-ranging
interfaces
like
an
element
reference
that
can
be
used
used
across
that
process.
E
It
feels
to
me
that
there
is
a
narrow
crop
target
discussion
on
the
broader
platform
integration
question,
and
maybe
we
can
start
with
the
solution
to
the
narrow
thing
and
evaluate
whether
there
is
a
migration
passed
to
maybe
the
right
solution.
If
there
is
a
different
right
solution
and
working
on
the
right
solution,
I
think,
as
harald
suggested
probably
requires
reaching
out
to
group.
That
would
be
the
right
place
for
this
broader
solution,
but
that
again
would
require,
I
think,
working
through
this
other
potential
api
users
of
this
broader
concept.
B
Well,
I
I
think,
that's
a
mischaracterization
of
one
position
here,
though
I
think
we're
saying
we're
not
saying
this
should
be
a
broader
solution.
We're
saying
these
are
the
standard
web
patterns
that
api
hasn't
influenced
api
design
for
a
long
time
and
there's
no
need
to.
We
shouldn't
depart
from
those
standards
without
good
reason,
and
I
don't
think
we've
heard
good
reason
from.
E
C
M
C
C
C
C
I
think
that
we
should
try
to
solve
these
issues
on
time
and
I'd
like
to
focus
on
these
three
issues
there,
which
is
think
or
not
sync
element
or
not,
or
media
devices,
an
attribute
or
method,
because
these
three
are
pretty
specific
isolated
and
we
should
be
good.
We
will.
We
are
the
university
working
group
that
should
make
the
decision
there,
and
my
understanding
is
that
we
have
identified
that.
B
F
M
Okay,
but
let's
say
that
they
come
back
and
the
answer
is
not
totally
conclusive
and
nobody
changes
their
mind.
I
suggest
that
one
way
that
we
could
proceed
is
that
we
can
have
this
particular
api
accepted.
We
go
with
that
and
we
consider
migration
paths
in
the
future
when
it's
when
mozilla
and
apple
have
also
implemented.
This
are
ready
to
ship
it
and
say
hey.
This
is
now
a
synchronous
for
us,
and
so
that's.
M
M
D
E
D
H
D
B
M
That
is
correct,
but
if
you
knew,
for
example,
that
you
could
have
it
tomorrow,
if
your
opinion
changed
then
like
I'm
not
sure
there
are
browsers
right.
Browser
vendors
have
one
set
of
criteria
and
web
developers
have
another
and
different
web
developers
might
change
their
mind
based
on
okay.
How
quickly
can
I
have
it,
and
I
it's
unclear
to
me
how
to
evaluate
such
opinions.
E
Well,
I
mean
I
can
give
you
the
way
this
has
been
looked
at
in
the
tag
before
the
future
is
longer
than
the
past,
and
so,
if
it's
gaining
one
month
of
variability
against
having
a
bad
api
forever
or
a
bad
api
that
is
hard
to
move
away
from,
then
then
I
think
the
calculation
points
towards
taking
an
additional
month.
But
of
course
nothing
is
that
black
and
white,
but
just
to
say
that
time
to
market
is
a
pretty
weak
argument
for
rushing
a
design
in
general
for
the
platform.
M
E
Yeah
and
that,
I
think,
is
a
reasonable
argument.
I
mean
there
is
a
cost
in
the
mental
model.
If,
indeed
you
don't,
you
can't
use
your
existing
understanding
of
the
platform
to
navigate
that
specific
api,
but
I,
in
this
particular
case,
I
don't
disagree
with
you
that
the
mental
cost
is
pretty
limited.