12 Nov 2013
Speaker: Patrick McFadin, Chief Evangelist at DataStax
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-apache-cassandra-20-data-model-on-fire
Functional data models are great, but how can you squeeze out more performance and make them awesome! Let's talk through some example Cassandra 2.0 models, go through the tuning steps and understand the tradeoffs. Many time's just a simple understanding of the underlying Cassandra 2.0 internals can make all the difference. I've helped some of the biggest companies in the world do this and I can help you. Do you feel the need for Cassandra 2.0 speed?
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-apache-cassandra-20-data-model-on-fire
Functional data models are great, but how can you squeeze out more performance and make them awesome! Let's talk through some example Cassandra 2.0 models, go through the tuning steps and understand the tradeoffs. Many time's just a simple understanding of the underlying Cassandra 2.0 internals can make all the difference. I've helped some of the biggest companies in the world do this and I can help you. Do you feel the need for Cassandra 2.0 speed?
- 1 participant
- 41 minutes

12 Nov 2013
Speaker: Oleg Anastasyev, Lead Platform Developer at Odnoklassniki.ru
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-being-closer-to-cassandra-at-okru
Odnoklassniki uses cassandra for its business data, which doesn't fit into RAM. This data is typically fast growing, frequently accessed by our users and must be always available, because it constitute our primary business as a social network. The way we use Cassandra is somewhat unusual - we don't use thrift or Netty based native protocol to communicate with Cassandra nodes remotely. Instead, we co-locate Cassandra nodes in the same JVM with business service logic, exposing not generic data manipulation, but business level interface remotely. This way, we avoid extra network roundtrips within a single business transaction and use internal calls to Cassandra classes to get information faster. Also, this helps us to create many small hacks on Cassandra's internals, making huge gains on efficiency and ease of distributed server development.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-being-closer-to-cassandra-at-okru
Odnoklassniki uses cassandra for its business data, which doesn't fit into RAM. This data is typically fast growing, frequently accessed by our users and must be always available, because it constitute our primary business as a social network. The way we use Cassandra is somewhat unusual - we don't use thrift or Netty based native protocol to communicate with Cassandra nodes remotely. Instead, we co-locate Cassandra nodes in the same JVM with business service logic, exposing not generic data manipulation, but business level interface remotely. This way, we avoid extra network roundtrips within a single business transaction and use internal calls to Cassandra classes to get information faster. Also, this helps us to create many small hacks on Cassandra's internals, making huge gains on efficiency and ease of distributed server development.
- 3 participants
- 48 minutes

12 Nov 2013
Speaker: Matt Casters, Chief Architect & PDI/Kettle Project Founder at Pentaho
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-blending-cassandra-data-into-the-mix
Traditionally, data is delivered to business analytics tools through a relational database. However, there are cases where that can be inconvenient, for example when the volume of data is just too high or when you can't wait until the database tables are updated.
This presentation by Pentaho Kettle founder Matt Casters will demonstrate a solution of data 'Blending', which allows a data integration user to create a transformation capable of delivering data directly to Pentaho - and other - business analytics tools. Matt will demonstrate taking data from Cassandra, and blending it with other data from both SQL and NoSQL sources, and then visualizing that data. Matt will explain how it becomes possible to create a virtual "database" with "tables" where the data actually comes from a transformation step.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-blending-cassandra-data-into-the-mix
Traditionally, data is delivered to business analytics tools through a relational database. However, there are cases where that can be inconvenient, for example when the volume of data is just too high or when you can't wait until the database tables are updated.
This presentation by Pentaho Kettle founder Matt Casters will demonstrate a solution of data 'Blending', which allows a data integration user to create a transformation capable of delivering data directly to Pentaho - and other - business analytics tools. Matt will demonstrate taking data from Cassandra, and blending it with other data from both SQL and NoSQL sources, and then visualizing that data. Matt will explain how it becomes possible to create a virtual "database" with "tables" where the data actually comes from a transformation step.
- 3 participants
- 40 minutes

12 Nov 2013
Speaker: Gary Dusbabek, Apache Cassandra Committer and Systems Architect at Rackspace Hosting
Slides: http://www.slideshare.net/gdusbabek/blueflood-open-source-metrics-processing-at-cassandraeu-2013
Rackspace needed a metrics system that could ingest 30 million signals generated from the Cloud Monitoring system. It had to offer custom data retention levels and still be able to offer graphs to customers in real-time. Gary and his team created a distributed system of shared-nothing nodes on top of Cassandra that split the responsibilities of: ingesting data, processing rollups, servicing data points for reads. Depending on the need, nodes can be easily reconfigured to support all or some of those functions. In this session you you will learn about techniques for scheduling rollups and still maintaining numerical accuracy, how to handled non-numerical data points, how to utilize open-source technology (Apache Cassandra, Scribe, Thrift, and Node.js) to deliver results relatively quickly and much more.
Slides: http://www.slideshare.net/gdusbabek/blueflood-open-source-metrics-processing-at-cassandraeu-2013
Rackspace needed a metrics system that could ingest 30 million signals generated from the Cloud Monitoring system. It had to offer custom data retention levels and still be able to offer graphs to customers in real-time. Gary and his team created a distributed system of shared-nothing nodes on top of Cassandra that split the responsibilities of: ingesting data, processing rollups, servicing data points for reads. Depending on the need, nodes can be easily reconfigured to support all or some of those functions. In this session you you will learn about techniques for scheduling rollups and still maintaining numerical accuracy, how to handled non-numerical data points, how to utilize open-source technology (Apache Cassandra, Scribe, Thrift, and Node.js) to deliver results relatively quickly and much more.
- 1 participant
- 36 minutes

12 Nov 2013
Speaker: Theo Hultberg, Chief Architect at Burt
Slides: http://www.slideshare.net/planetcassandra/theo-hultberg
I'm not a database driver expert, I'm just a Ruby developer who really likes Cassandra, but I've written a CQL driver. It wasn't hard, and it feels really good to now have an understanding of how my applications talk to Cassandra. To know what happens when I connect, prepare a statement, or how my data is encoded on its way to the database. When my CQL collections got big and I got weird results back, I could use my knowledge to quickly debug the issue. I'd like to give you an overview of the new native protocol from the driver perspective, maybe it can help you understand Cassandra the way it has helped me.
Slides: http://www.slideshare.net/planetcassandra/theo-hultberg
I'm not a database driver expert, I'm just a Ruby developer who really likes Cassandra, but I've written a CQL driver. It wasn't hard, and it feels really good to now have an understanding of how my applications talk to Cassandra. To know what happens when I connect, prepare a statement, or how my data is encoded on its way to the database. When my CQL collections got big and I got weird results back, I could use my knowledge to quickly debug the issue. I'd like to give you an overview of the new native protocol from the driver perspective, maybe it can help you understand Cassandra the way it has helped me.
- 4 participants
- 50 minutes

12 Nov 2013
Speakers: Rokesh Jankie, CTO at QAFE Inc. & Hallo Khaznadar CAO at QAFE Inc.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-capitalizing-on-data-in-telecommunications-the-cassandra-way
Telecommunications mediation is the process of handling Call Data Records (CDR's) coming through specialized hardware switches that are connected to the infrastructure of the telecommunications company. The standard industry requirements of these processes are the archiving of original raw data for auditing purposes, decoding and persisting of the extracted Call Data Records for applying rating, billing, reporting and feeding processed data to other sub systems specific to each telecoms platform. The number of CDR's and their size has exploded since mobility got an enormous boost in recent years. A new and non-traditional approach is needed to achieve these requirements. By combining QAFE-based architecture platform with the hardware power of the cutting edge Oracle Exalogic and the scaleable, flexible and highly performing DataStax enterprise, we achieved astonishing results. The solution not only allowed us to achieve industry standard requirements but also opened up the door for new requirements, realizing crucial functionality for the industry. Specifically the ability to perform analytics, reporting and KPI's in a time period spanning several years. In the presentation, there will be focus on the combination of a private cloud solution (public clouds are not an option here due to legislation) and DataStax enterprise. A working benchmark can show performance numbers of the real time processing and the storage of big amounts of CDR's from several sources.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-capitalizing-on-data-in-telecommunications-the-cassandra-way
Telecommunications mediation is the process of handling Call Data Records (CDR's) coming through specialized hardware switches that are connected to the infrastructure of the telecommunications company. The standard industry requirements of these processes are the archiving of original raw data for auditing purposes, decoding and persisting of the extracted Call Data Records for applying rating, billing, reporting and feeding processed data to other sub systems specific to each telecoms platform. The number of CDR's and their size has exploded since mobility got an enormous boost in recent years. A new and non-traditional approach is needed to achieve these requirements. By combining QAFE-based architecture platform with the hardware power of the cutting edge Oracle Exalogic and the scaleable, flexible and highly performing DataStax enterprise, we achieved astonishing results. The solution not only allowed us to achieve industry standard requirements but also opened up the door for new requirements, realizing crucial functionality for the industry. Specifically the ability to perform analytics, reporting and KPI's in a time period spanning several years. In the presentation, there will be focus on the combination of a private cloud solution (public clouds are not an option here due to legislation) and DataStax enterprise. A working benchmark can show performance numbers of the real time processing and the storage of big amounts of CDR's from several sources.
- 5 participants
- 46 minutes

12 Nov 2013
Speaker: Paul Makkar — DevOps at Sky
Slides:
How to bring up a new data center and take down the old one with zero downtime, using Apache Cassandra.
Slides:
How to bring up a new data center and take down the old one with zero downtime, using Apache Cassandra.
- 1 participant
- 39 minutes

12 Nov 2013
Speaker: Aaron Morton, Apache Cassandra Committer & Co-Founder/Principle Consultant at The Last Pickle Inc.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-internals
From the microsecond your request hits an Apache Cassandra node there are many code paths, threads and machines involved in storing or fetching your data. This talk will step through the common operations and highlight the code responsible. Apache Cassandra solves many interesting problems to provide a scalable, distributed, fault tolerant database. Cluster wide operations track node membership, direct requests and implement consistency guarantees. At the node level, the Log Structured storage engine provides high performance reads and writes. All of this is implemented in a Java code base that has greatly matured over the past few years. This talk will step through read and write requests, automatic processes and manual maintenance tasks. I'll discuss the general approach to solving the problem and drill down to the code responsible for implementation. Existing Cassandra users, those wanting to contribute to the project and people interested in Dynamo based systems will all benefit from this tour of the code base.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-internals
From the microsecond your request hits an Apache Cassandra node there are many code paths, threads and machines involved in storing or fetching your data. This talk will step through the common operations and highlight the code responsible. Apache Cassandra solves many interesting problems to provide a scalable, distributed, fault tolerant database. Cluster wide operations track node membership, direct requests and implement consistency guarantees. At the node level, the Log Structured storage engine provides high performance reads and writes. All of this is implemented in a Java code base that has greatly matured over the past few years. This talk will step through read and write requests, automatic processes and manual maintenance tasks. I'll discuss the general approach to solving the problem and drill down to the code responsible for implementation. Existing Cassandra users, those wanting to contribute to the project and people interested in Dynamo based systems will all benefit from this tour of the code base.
- 3 participants
- 36 minutes

12 Nov 2013
Speakers: Michaël Figuiere, Software Engineer at DataStax & Alex Popescu, Senior Product Manager at DataStax
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-made-simple-with-cql-drivers-and-devcenter
Is Cassandra too complex for newcomers? Besides the many improvements that have made their way into C* to dramatically simplify it and the finalized Cassandra Query Language, the SQL-like query language that should look familiar, new drivers have been created with a modern and efficient API. Last, but not least, DataStax is introducing *today* DevCenter 1.0, an IDE whose goal is to simplify developer's workflow even further and to improve their productivity. This presentation will show you how putting to work the new drivers and DevCenter can make your daily life with Cassandra nicer!
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-made-simple-with-cql-drivers-and-devcenter
Is Cassandra too complex for newcomers? Besides the many improvements that have made their way into C* to dramatically simplify it and the finalized Cassandra Query Language, the SQL-like query language that should look familiar, new drivers have been created with a modern and efficient API. Last, but not least, DataStax is introducing *today* DevCenter 1.0, an IDE whose goal is to simplify developer's workflow even further and to improve their productivity. This presentation will show you how putting to work the new drivers and DevCenter can make your daily life with Cassandra nicer!
- 2 participants
- 46 minutes

12 Nov 2013
Speaker: Matt Kennedy, Solution Architect: Big Data at Fusion.io
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-on-flash-performance-efficiency-lessons-learned
Flash Memory technology, deployed as server-side PCIe or solid state disks (SSDs), is emerging as a critical tool for performance and efficiency in data centers of all scales. This presentation will discuss how the use of Flash impacts Cassandra deployments in terms of configuration, DRAM requirements and performance expectations. Ideas on leveraging C*'s cutting-edge data-center awareness to blend flash and disk storage nodes for cost and workload efficiency will also be shared. Flash media itself will be examined from a physical perspective to understand endurance issues. Data on write amplification under bulk-load and operational workload conditions will be presented to explain the impact to Flash of C*'s Log Structured Merge Tree architecture and the associated compactions. Finally, we will examine strategies to make Cassandra more Flash-aware using both conventional techniques as well as emerging Non-volatile memory (NVM) programming capabilities. Lessons learned from real-world customer deployments will be shared to complete this presentation.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-cassandra-on-flash-performance-efficiency-lessons-learned
Flash Memory technology, deployed as server-side PCIe or solid state disks (SSDs), is emerging as a critical tool for performance and efficiency in data centers of all scales. This presentation will discuss how the use of Flash impacts Cassandra deployments in terms of configuration, DRAM requirements and performance expectations. Ideas on leveraging C*'s cutting-edge data-center awareness to blend flash and disk storage nodes for cost and workload efficiency will also be shared. Flash media itself will be examined from a physical perspective to understand endurance issues. Data on write amplification under bulk-load and operational workload conditions will be presented to explain the impact to Flash of C*'s Log Structured Merge Tree architecture and the associated compactions. Finally, we will examine strategies to make Cassandra more Flash-aware using both conventional techniques as well as emerging Non-volatile memory (NVM) programming capabilities. Lessons learned from real-world customer deployments will be shared to complete this presentation.
- 1 participant
- 43 minutes
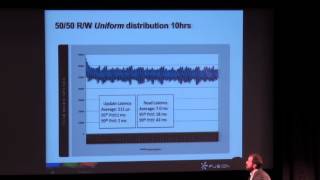
12 Nov 2013
Speaker: Matthieu Nantern, Software Engineer at Xebia
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-delivering-christmas-gifts-in-france-since-2012
Every year more and more people buy their Christmas gifts online and that gifts are delivered by the postal service of France "La Poste". At the end of the infrastructure a (not so) little MySQL was struggling for survival against that overwhelming load. Then, in 2011, MySQL hit its limit... Come hear the true story of La Poste switching its parcel management, PHP-based application, from MySQL to Cassandra in 3 weeks. You'll be taught about the details of the project constraints, how to use Cassandra from PHP, the migration plan, how to manage resilience testing, deploy your Cassandra with Puppet, and all the wonderful knowledge we accumulate through this project.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-delivering-christmas-gifts-in-france-since-2012
Every year more and more people buy their Christmas gifts online and that gifts are delivered by the postal service of France "La Poste". At the end of the infrastructure a (not so) little MySQL was struggling for survival against that overwhelming load. Then, in 2011, MySQL hit its limit... Come hear the true story of La Poste switching its parcel management, PHP-based application, from MySQL to Cassandra in 3 weeks. You'll be taught about the details of the project constraints, how to use Cassandra from PHP, the migration plan, how to manage resilience testing, deploy your Cassandra with Puppet, and all the wonderful knowledge we accumulate through this project.
- 1 participant
- 36 minutes

12 Nov 2013
Speaker: Eric Zoerner, Senior Software Developer at eBuddy
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-denormalizing-your-data-a-java-library-to-support-structured-data-in-cassandra
In this session you'll learn about the design and implementation of a new open source general-purpose Java library that supports storing structured data in Cassandra. Instead of mapping the data to multiple tables like an ORM would or embedding data using serialization, this approach decomposes structured data of arbitrary complexity into separate columns of simple values, allowing the data to be retrieved or updated in parts using hierarchical paths. Implementations are included for Cassandra using both the Thrift and CQL3 APIs. In addition, Eric's experiences are shared regarding the challenges of using CQL3 vs. Thrift for schema-less data.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-denormalizing-your-data-a-java-library-to-support-structured-data-in-cassandra
In this session you'll learn about the design and implementation of a new open source general-purpose Java library that supports storing structured data in Cassandra. Instead of mapping the data to multiple tables like an ORM would or embedding data using serialization, this approach decomposes structured data of arbitrary complexity into separate columns of simple values, allowing the data to be retrieved or updated in parts using hierarchical paths. Implementations are included for Cassandra using both the Thrift and CQL3 APIs. In addition, Eric's experiences are shared regarding the challenges of using CQL3 vs. Thrift for schema-less data.
- 1 participant
- 44 minutes

12 Nov 2013
Speaker: Mick Semb Wever, Programmer at FINN.no
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-from-cql-to-timeseries-event-tracking-and-aggregation-using-cassandra-and-hadoop
FINN.no's is a classifieds website and Norway's busiest website. This session will go through various product development where c* has shown to be the best choice, focusing on our primary c* use-case: our in-house tracking solution that's collects raw time-series data in c* and aggregates minute-by-minute it using hadoop into various new datasets from advert-centric statistics to user-centric behavioural analysis. I'll cover the final technical design chosen after a number of development iterations touching on technologies: scribe, thrift, kafka, hadoop, pig, mahout; the hurdles faced along the way, and the throughput and performance of today's systems.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-from-cql-to-timeseries-event-tracking-and-aggregation-using-cassandra-and-hadoop
FINN.no's is a classifieds website and Norway's busiest website. This session will go through various product development where c* has shown to be the best choice, focusing on our primary c* use-case: our in-house tracking solution that's collects raw time-series data in c* and aggregates minute-by-minute it using hadoop into various new datasets from advert-centric statistics to user-centric behavioural analysis. I'll cover the final technical design chosen after a number of development iterations touching on technologies: scribe, thrift, kafka, hadoop, pig, mahout; the hurdles faced along the way, and the throughput and performance of today's systems.
- 2 participants
- 39 minutes

12 Nov 2013
Speaker: Andy Cobley, Lecturer at University of Dundee
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-hardware-agnostic-cassandra-on-raspberry-pi-28053540
Abstract: The raspberry Pi is a credit-card sized $25 ARM based linux box designed to teach children the basics of programming. The machine comes with a 700MHz ARM and 512Mb of memory and boots off a SD card, not much power for running the likes of a Cassandra cluster. This presentation will discuss the problems of getting Cassandra up and running on the Pi and will answer the all important question: Why on Earth would you want to do this!?
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-hardware-agnostic-cassandra-on-raspberry-pi-28053540
Abstract: The raspberry Pi is a credit-card sized $25 ARM based linux box designed to teach children the basics of programming. The machine comes with a 700MHz ARM and 512Mb of memory and boots off a SD card, not much power for running the likes of a Cassandra cluster. This presentation will discuss the problems of getting Cassandra up and running on the Pi and will answer the all important question: Why on Earth would you want to do this!?
- 2 participants
- 33 minutes

12 Nov 2013
Speaker: Jonathan Ellis, Apache Cassandra Project Chair and CTO/Co-Founder at DataStax
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-keynote-by-jonathan-ellis
Keynote Presentation on Cassandra 2.0 & 2.1 by Jonathan Ellis at Cassandra Summit EU 2013
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-keynote-by-jonathan-ellis
Keynote Presentation on Cassandra 2.0 & 2.1 by Jonathan Ellis at Cassandra Summit EU 2013
- 2 participants
- 55 minutes

12 Nov 2013
Speaker: Ernesto Ongaro, Senior Sales Engineer at Jaspersoft
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-leveraging-the-power-of-cassandra-operational-reporting-and-interactive-analysis
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-leveraging-the-power-of-cassandra-operational-reporting-and-interactive-analysis
- 4 participants
- 36 minutes

12 Nov 2013
Title: Stratio Search: In-Memory Search with Cassandra Persistence
Speaker: Álvaro Agea Herradón
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-stratio-search-inmemory-search-with-cassandra-persistence
Title: Analytics on top of Cassandra and Hadoop
Speaker: Dmitry Mezhensky
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-analytics-on-top-of-cassandra-and-hadoop
Title: Effective Cassandra Development with Achilles
Speaker: DoyHai DOAN — Freelance Developer
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-effective-cassandra-development-with-achilles
Title: Ontorion: Scalable Information Management
Speaker: Pawel Zarzycki — CEO at Cognitum
Slides: http://www.slideshare.net/planetcassandra/ontorion-scalable-information-manag
Speaker: Álvaro Agea Herradón
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-stratio-search-inmemory-search-with-cassandra-persistence
Title: Analytics on top of Cassandra and Hadoop
Speaker: Dmitry Mezhensky
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-analytics-on-top-of-cassandra-and-hadoop
Title: Effective Cassandra Development with Achilles
Speaker: DoyHai DOAN — Freelance Developer
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-effective-cassandra-development-with-achilles
Title: Ontorion: Scalable Information Management
Speaker: Pawel Zarzycki — CEO at Cognitum
Slides: http://www.slideshare.net/planetcassandra/ontorion-scalable-information-manag
- 7 participants
- 33 minutes

12 Nov 2013
Speaker: Richard Low, Analytics Tech Lead at SwiftKey
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-mixing-batch-and-realtime-cassandra-with-shark
Everything Cassandra does is designed for a real-time workload of high volume inserts and frequent small queries. Cassandra has Hadoop and Hive integration, but performing long running ad-hoc queries with these tools is difficult without impacting real-time performance or requires duplicate clusters. This talk will explain how I'm integrating Cassandra with Shark, a drop-in Hive replacement developed by Berkeley's AmpLab. It's designed to give fine grained control over all resource usage so you can safely run arbitrary ad-hoc queries on your existing cluster with controlled and predictable impact.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-mixing-batch-and-realtime-cassandra-with-shark
Everything Cassandra does is designed for a real-time workload of high volume inserts and frequent small queries. Cassandra has Hadoop and Hive integration, but performing long running ad-hoc queries with these tools is difficult without impacting real-time performance or requires duplicate clusters. This talk will explain how I'm integrating Cassandra with Shark, a drop-in Hive replacement developed by Berkeley's AmpLab. It's designed to give fine grained control over all resource usage so you can safely run arbitrary ad-hoc queries on your existing cluster with controlled and predictable impact.
- 2 participants
- 36 minutes

12 Nov 2013
Speaker: Dave Gardner, Architect at Hailo
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-no-whistling-required-cabs-cassandra-and-hailo
Hailo has leveraged Cassandra to build one of the most successful startups in European history. This presentations looks at how Hailo grew from a simple MySQL-backed infrastructure to a resilient Cassandra-backed system running in three data centres globally. Topics covered include: the process of migration, experience running multi-DC on AWS, common data modeling patterns and security implications for achieving PCI compliance.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-no-whistling-required-cabs-cassandra-and-hailo
Hailo has leveraged Cassandra to build one of the most successful startups in European history. This presentations looks at how Hailo grew from a simple MySQL-backed infrastructure to a resilient Cassandra-backed system running in three data centres globally. Topics covered include: the process of migration, experience running multi-DC on AWS, common data modeling patterns and security implications for achieving PCI compliance.
- 2 participants
- 42 minutes

12 Nov 2013
Speaker: Patricia Gorla, Systems Engineer at Opensource Connections
Slides: http://www.slideshare.net/planetcassandra/patricia-gorla
For any venture, storing your data is just the first step in making sense of it. How do you make your system discoverable? How do you tune your relevancy to accommodate real-time updates? In this session, we explore pairing Cassandra with Solr using Datastax Enterprise Search, and look at different search paradigms to help your users find patterns in your data.
Slides: http://www.slideshare.net/planetcassandra/patricia-gorla
For any venture, storing your data is just the first step in making sense of it. How do you make your system discoverable? How do you tune your relevancy to accommodate real-time updates? In this session, we explore pairing Cassandra with Solr using Datastax Enterprise Search, and look at different search paradigms to help your users find patterns in your data.
- 6 participants
- 34 minutes

12 Nov 2013
Speaker: Michael Masterson Director of Strategic Business Development at Compuware APM
Even with the fastest Cassandra cluster beneath the hood, it's the app that ultimately governs performance. Learn from customer examples on how to address the root cause of slow performance.
Even with the fastest Cassandra cluster beneath the hood, it's the app that ultimately governs performance. Learn from customer examples on how to address the root cause of slow performance.
- 2 participants
- 45 minutes
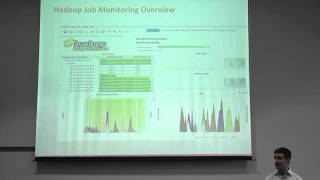
12 Nov 2013
Speaker: Jimmy Mardell, Senior Software Engineer at Spotify
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-playlists-at-spotify-using-cassandra-to-store-version-controlled-objects
All systems at Spotify have to deal with huge amounts of data. Playlists in particular is a unique challenge. We need to store more than one billion playlists, and make them accessible for not only the playlist owner but also subscribers. Furthermore, we need to handle concurrent changes to collaborative playlists and offline scenarios. The devised solution treats every playlist as a versioned object. We use Cassandra to store these objects in an efficient way, allowing fast read- and write queries. The road there was not pain free however. I will talk about the data model we ended up using, and lessons learned along the way.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-playlists-at-spotify-using-cassandra-to-store-version-controlled-objects
All systems at Spotify have to deal with huge amounts of data. Playlists in particular is a unique challenge. We need to store more than one billion playlists, and make them accessible for not only the playlist owner but also subscribers. Furthermore, we need to handle concurrent changes to collaborative playlists and offline scenarios. The devised solution treats every playlist as a versioned object. We use Cassandra to store these objects in an efficient way, allowing fast read- and write queries. The road there was not pain free however. I will talk about the data model we ended up using, and lessons learned along the way.
- 1 participant
- 40 minutes

12 Nov 2013
Speaker: Al Tobey, Open Source Mechanic at DataStax
Slides: http://www.slideshare.net/planetcassandra/practice-makes-perfect-extreme-cassandra-optimization
Ooyala has been using Apache Cassandra since version 0.4. Our data ingest volume has exploded since 0.4 and Cassandra has scaled along with us. Al will cover many topics from an operational perspective on how to manage, tune, and scale Cassandra in a production environment.
Slides: http://www.slideshare.net/planetcassandra/practice-makes-perfect-extreme-cassandra-optimization
Ooyala has been using Apache Cassandra since version 0.4. Our data ingest volume has exploded since 0.4 and Cassandra has scaled along with us. Al will cover many topics from an operational perspective on how to manage, tune, and scale Cassandra in a production environment.
- 1 participant
- 46 minutes
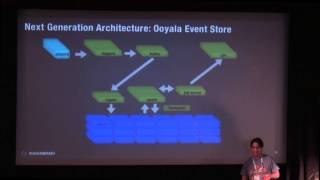
12 Nov 2013
Speaker: Tim Moreton, Founder & CTO at Acunu
Cassandra is a superb platform for building scalable real-time analytics applications. And the highest value applications will be those that put simple visualizations of critical KPIs in the hands of business users.
But there's a tension between your development team crafting complex, denormalized data models in CQL and your business users constantly evolving their understanding of the data and their analytic needs.
Acunu Analytics helps to resolve that gap by using Cassandra to continuously maintain OLAP cubes that support instant, SQL-like queries and offering those up through a BI dashboarding tool.
In this talk, I'm going to explore these concepts, and dig into how we've automated the process of going from a stream of JSON events to a live dashboard of the indicators business users need.
Cassandra is a superb platform for building scalable real-time analytics applications. And the highest value applications will be those that put simple visualizations of critical KPIs in the hands of business users.
But there's a tension between your development team crafting complex, denormalized data models in CQL and your business users constantly evolving their understanding of the data and their analytic needs.
Acunu Analytics helps to resolve that gap by using Cassandra to continuously maintain OLAP cubes that support instant, SQL-like queries and offering those up through a BI dashboarding tool.
In this talk, I'm going to explore these concepts, and dig into how we've automated the process of going from a stream of JSON events to a live dashboard of the indicators business users need.
- 3 participants
- 40 minutes

12 Nov 2013
Speakers: Patrick McFadin, Chief Evangelist at DataStax & Al Tobey, Open Source Mechanic at DataStax
It's time to play "Stump the Experts", with Al Tobey, Open Source Mechanic at DataStax, and Patrick McFadin, Chief Evangelist at DataStax. Bring your urgent Cassandra questions to this session and have our expert panel answer them for you.
It's time to play "Stump the Experts", with Al Tobey, Open Source Mechanic at DataStax, and Patrick McFadin, Chief Evangelist at DataStax. Bring your urgent Cassandra questions to this session and have our expert panel answer them for you.
- 15 participants
- 55 minutes

12 Nov 2013
Speakers: Jonathan Halliday, Core Developer at JBoss & Rui Vieira, Postgrad Student at Newcastle University
Slides: http://www.slideshare.net/planetcassandra/jonathan-halliday
Performing ranking queries to find the most relevant documents, most popular urls, etc on huge datasets is trivial —if you're willing to wait a while for the answers. For those with less time to waste, this session describes techniques for performing such queries efficiently. We'll describe the ranking queries problem, outline the Cassandra CQL3 data structures and code that can be used to solve it and describe the trade-offs available. We describe intravert, an innovative server-side programming solution for Cassandra, and show how it can be used to reduce network usage and improve performance by filtering data closer to source.
Slides: http://www.slideshare.net/planetcassandra/jonathan-halliday
Performing ranking queries to find the most relevant documents, most popular urls, etc on huge datasets is trivial —if you're willing to wait a while for the answers. For those with less time to waste, this session describes techniques for performing such queries efficiently. We'll describe the ranking queries problem, outline the Cassandra CQL3 data structures and code that can be used to solve it and describe the trade-offs available. We describe intravert, an innovative server-side programming solution for Cassandra, and show how it can be used to reduce network usage and improve performance by filtering data closer to source.
- 1 participant
- 35 minutes

12 Nov 2013
Speaker: Pavel Pontryagin, Senior Engineer at Peter-Service
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-using-cassandra-in-a-telco-storage-system
Data volume grows and in telecommunication area it is painful to support and scale RDBMS systems. This presentation shows how we switched from SQL to NoSQL. This will be an overview of aspects: * how we model schema for call data using NoSQL vs SQL. * what hardware architecture we use * NoSQL vs SQL insert-select performance * how we store graph data using C*.
Slides: http://www.slideshare.net/planetcassandra/c-summit-eu-2013-using-cassandra-in-a-telco-storage-system
Data volume grows and in telecommunication area it is painful to support and scale RDBMS systems. This presentation shows how we switched from SQL to NoSQL. This will be an overview of aspects: * how we model schema for call data using NoSQL vs SQL. * what hardware architecture we use * NoSQL vs SQL insert-select performance * how we store graph data using C*.
- 3 participants
- 27 minutes
