►
From YouTube: Ops Section Overview
Description
Originally recorded for GitLab Sales KickOff - https://gitlab.com/gitlab-com/sales-team/sales-enablement-videocast-series/issues/26
A
A
What
we,
what
are
what's
available
in
get
lab
right
now
and
then
we'll
jump
to
me,
giving
an
overview
of
where
this
section
is
headed.
It's
a
place
where
we're
investing
a
lot.
We
have
a
lot
of
growth
plans
for
where
we
wants
to
take
the
product
and
this
part
of
the
product
in
the
future.
So
with
that,
why
don't
I
hit
it
over
to
William
who's?
Gonna
talk
about
our
key
figures.
B
When
we
talk
about
configure
configuration
management,
there
are
a
lot
of
tools
in
the
market
that
that
would
fit
under
the
configure
part
of
DevOps,
and
so,
when
we're
talking
about
configuration,
we're
we're
really
talking
about
a
layer
almost
above
that,
where
we're
managing
configuration
tools,
so
you
can
think
of
this
as
kubernetes
folks
that
are
using
kubernetes.
We
think
it
lab
and
we
are
allowing
you
to
configure
your
kubernetes
clusters.
B
This
involves
serverless
and
infrastructure
is
code
and
the
way
we're
thinking
about
if
structures
code
is
creating
again
a
management
layer
to
manage
I,
see
organ
structures,
code
tools,
and
you
can
think
of
this
as
the
laying
the
groundwork
for
your
CI
CD.
So
a
great
analogy
here
is:
if
CI
CD
is
the
plane
and
you
are
coming
in
to
land
your
plane.
The
configure
stage
is
about
the
runway.
It's
the
infrastructure,
the
environments
where
you're
deploying
your
code.
B
So
with
this,
we're
targeting
folks
like
developers
and
operations
engineers
and
who,
what
we're
not
doing,
is
building
a
configuration
tool
for
things
like
VMs
and
bare-metal
servers.
The
tools
like
chef,
puppet
ansible,
terraform,
we're
not
looking
to
replace
those
tools,
we're
looking
to
integrate
with
those
tools
with
our
configure
stage,
and
so
as
such.
B
Ops
teams
we're
not
targeting
central
IT
system
into
those
types
of
personas,
and
we
are
looking
at
some
legacy
infrastructure
things
like
virtual
machines,
not
just
kubernetes,
but
but
we
are
looking
at
some
of
what
we
would
call
legacy
infrastructure
which
we
mean
non
containerized
or
infrastructure.
That's
not
kubernetes.
In
a
little
bit
longer
term.
Two
to
three
years,
we
are
looking
to
open
us
a
broader
set
of
personas.
We
want
to
displace
incumbent
monitoring
and
configuration
solutions
and
have
that
single
application
for
cloud
native
and
legacy
apps.
B
C
Okay,
so
when
we
talking
about
monitoring
within
gitlab,
essentially
we're
talking
about
monitoring
the
software
that
you're
developing
and
deploying
using
it
lab
it
could
be
your
kubera
T's
clusters
or
applications
that
you
are
deploying
using
it
lab
itself.
Self
monitoring
which
so
far
used
to
be
part
of
the
monitor,
monitor
stage
itself
is
not
going
to
be
part
of
the
monitor
stage.
It
would
be
moved
to
the
enablement
stage
as
a
as
of
Fi
21
from
a
persona
point
of
view.
C
Essentially,
we
are
targeting
developers
and
the
box
engineers
who
are
using
it
lab
as
a
single
application
from
all
the
way
from
creating
the
code
to
are
to
deploying
and
monitoring
the
code
in
production.
It
specifically
for
developers
who
are
looking
building
using
cloud
native
applications.
We
don't
intend,
in
the
short
term,
to
target
the
central
IT
teams,
Ops
teams
and
therefore,
in
the
short
term,
we
don't.
C
We
are
not
looking
at
being
the
single
consolidated
to
a
tool
set
for
an
patience
team
right
in
the
long
term,
our
goal
in
the
two
to
three
years
timeframe.
Our
goal
is
really
to
cover
cloud
native
application
and
platform
teams
that
support
those
cloud
native
applications.
So,
in
addition
to
the
DevOps
engineers
and
cloud
native
applications
that
we
spoke
about,
we
would
also
intend
to
support
the
platform
teams
that
are
supporting
development
of
such
applications
or
monitoring
applications
for
those
cloud
native
apps
who
will
find
value
in
it
today.
C
A
Thanks
Sam
yeah
and
yeah,
while
I
share
my
screen,
the
observability.
The
core
thing
is
a
really
important
thing
for
us.
It's
important
that
we
enable
individual
developers
to
have
full
control
over
their
observability
suite
and
having
our
system
in
core
means
that
it's
a
tool
that
developers
can
use
deeply
ingrained
with
their
existing
set
of
tools,
while
also
being
able
to
contribute
back
to
it
right.
It's
an
open
source
project.
You
can
improve
it
in
the
way
that
you
would
improve
your
application
code.
So
we're
really
excited
about
that.
A
I
just
meant
I
wanted
to
briefly
go
over
some
of
the
existing
features
in
the
ops
section.
I'm
gonna
show
some
slides
that
have
screenshots
and
talk
through
them,
but
there
are
also
plenty
of
example.
Projects
that
get
lab
comm
is
dogs
that
get
the
get
lab.
Team
is
dog
fooding
or
some
projects
that
the
top
section
stage
teams
use
in
order
to
demo
the
sets
of
features
that
we're
talking
about.
So,
if
you
have
questions,
feel
free
to
reach
out,
we
can
give
you
some
concrete,
real-world
examples.
A
The
first
step
in
the
ops
section
is
really
about
the
attachment
of
kubernetes
clusters,
and
so
we
made
an
early
bet
in
kubernetes
and
we
make
the
adoption
or
use
of
kubernetes
really
easy
for
developers
and
development
teams.
You
can
easily
add
a
cluster
from
one
of
the
currently
two
major
cloud
providers.
It
quickly
integrates
with
their
managed
kubernetes
services,
so
you
can
create
a
gke
or
an
AWS
cluster
right
there
on
the
side
of
your
project.
A
There's
a
operations,
kubernetes
tab,
click
on
that
and
you
get
the
ability
to
quickly
create
kind
of
prescribed
cluster.
Once
you
create
that
cluster,
you
can
install
kubernetes
apps
using
helm.
We
have
a
portfolio
of
apps
today
that
we
think
are
important
to
enable
you
to
get
the
full
use
out
of
that
cluster
and
get
it
and
have
it
be
fully
integrated.
Once
you've
installed
some
of
those
apps,
including
the
one
that
enables
monitor
you
can
start
seeing
the
health.
This
is
all
right
within
the
github
application.
A
You
can
start
seeing
the
CPU
and
memory
usage
from
within
that
cluster,
and
then
we
subsequently
once
we
have
this
information
about
an
attached
cluster
for
your
project
or
in
you
can
also
attach
them
at
the
group
level.
You
start
getting
this
really
rich
integration.
You're
attached
cluster
immediately
becomes
available
through
a
set
of
CI
variables
or
environment
variables
that
you
can
easily
deploy
your
application
to
it.
A
When
you
have
an
attached
cluster,
we
can
use
Auto
DevOps
scripts,
which
perform
prescriptive
CI
jobs
that
not
only
test
your
code
but
also
deploy
that
to
that
cluster
in
specified
environments
creates
review
apps
for
you
automatically.
These
are
all
just
with
a
couple
of
clicks
of
a
button.
Once
you've
got
a
kubernetes
cluster
attached
to
your
project,
we
give
you
rich
environment
views,
including
a
view
into
what
help
what
pods
are
deployed
into
a
specific
environment.
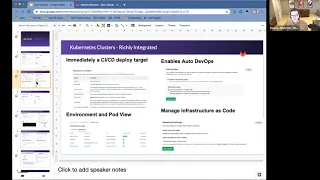
A
The
example
in
that
image
here
is
a
group
level
cluster
with
multiple
projects
attached
to
that
same
cluster,
all
with
different
environments,
in
this
case,
there's
some
production
and
review
apps,
but
you
could
imagine
multiple,
staging
or
production
environments
per
application.
All
viewable
here
with
the
pods
that
are
there,
you
can
quickly
drill
into
pod
logs
the
specific
projects
code,
the
environments
state
all
from
right
within
get
lab
all
because
you've
attached
that
cluster
and
we
have
it
really
well
integrated
and
then,
lastly,
you
can
even
define
the
clusters
criteria
or
configuration
in
code.
A
You
can
assign
a
cluster
management
project
that
says
this
is
a
descriptive
state
of
the
cluster
that
I'd
like
to
be
using
and
manage
that
just
like
you
would
any
other
code.
William
talked
about
infrastructure
is
code
and
we
don't
want
to
replace
those
other
existing
configuration
management
tools.
We
almost
think
of
them
like
languages
right.
You
can
write
their
language
in
stored,
the
description
of
that
language
in
a
repository,
and
we
can
manipulate
that
just
like
we
would
any
other
code
and
in
this
case
we're
using
it
to
manage
your
kubernetes
cluster.
A
The
other
side
that
william
mentioned
was
server
list,
and
so
we've
had
our
service
category
available
for
almost
a
year
now,
and
we
have
some
great
integration
where
you
can
quickly
get
started,
there's
great
templates
for
getting
started.
You
can
define
a
server
list
that
you
mol
file
that
defines
what,
in
this
case,
I'm
defining
functions
where
you
can
define
the
functions
that
are
to
be
deployed.
You
easily
install
Kay
native
as
the
service
we
use
primarily
to
manage
several
steps.
We've
recently
added
support
for
AWS
lambda.
You
can.
A
We
get
started
on
the
kind
of
functions
based
architecture
if
your
teams
are
creating
brand
new
apps
that
fit
that
architecture
and
once
you've
created
them.
We
give
you
good
insight
into
you,
the
number
of
invocations,
the
URL.
What
pods
are
being
deployed
for
these
functions
all
again
right
within
Gil
app,
so
these
are
both
examples
of
more
modern
technologies
that
we
make
really
easy
to
adopt
for
teams
that
might
not
be
as
as
familiar
with
them
in
the
monitor
section.
We
have.
You
know,
panels
for
dashboards
that
display
metrics.
A
We
have
come
with
a
bunch
of
out-of-the-box
metrics
when
you
attach
a
kubernetes
cluster
and
install
the
Prometheus
monitoring
service
metric
service,
you
immediately
get
a
set
of
dashboards
for
various,
both
system
level
and
application
level.
Metrics
that
are
important
to
be
observing.
We
give
you
immediate
access
to
your
kubernetes
pod
logs,
so
you
can
kind
of
tail
the
logs
coming
off
your
community's
cluster
and
a
specific
pod
that
an
application
might
be
running
in
when
trying
to
troubleshoot.
A
We
give
you
a
good
view
and
it
and
integration
with
two
other
open
source
projects,
sentry
and
Yeager
for
error,
tracking
and
tracing
and
again
in
all
of
those
instances,
it's
not
just
over
displaying
the
information,
we're
a
single
application
for
your
DevOps
platform
from
an
Operations
perspective.
That
means
really
rich
context
being
provided
throughout
that
experience.
So
when
you
look
at
an
error,
you
get
to
see
the
most
recent
good
web
commits
that
might
be
associated
with
that
error.
A
We
can
jump
you
to
the
file
blame
or
the
history
of
file
when
you're,
looking
at
a
stack
trace
when
you're.
Looking
at
your
ops
dashboard,
we
can
show
you
the
alerts
for
specific
applications
or
projects
right
there
on
the
dashboard.
When
you're
looking
at
the
various
environments,
you
can
quickly
jump
to
them.
The
metrics
views
of
that
environment
to
see
if
that
environment
is
performing
is
healthy.
A
These
are
all
part
of
not
just
having
the
tools
for
doing
observer
ability,
but
integrating
them
really
and
then
the
last
one
is
incident
management
and
again
this
is
really
about
being
able
to
embed
rich
context.
We
use
get
lab
issues
for
incident
management.
When
you
set
up
alerts,
you
can
have
them
automatically
create
issues
from
a
prescribed
template
and
those
templates
aren't
just
content.
You
can
embed
information
that
was
generated
by
the
alert
and
from
the
alert
payload
right
into
the
incident
template.
You
can
also
directly
embed
charts.
A
So
maybe
there's
a
type
of
incident
that
you
regularly
look
at
a
certain
chart.
Maybe
a
database
query
chart
whenever
you
see
an
alert
of
this
type
embed
that
right
there,
and
then
we
also
have
the
ability
to
integrate
with
zoom.
This
is
an
example
where
there's
a
quick
action
for
adding
a
zoom
link
to
any
issue
so
that
you
can
quickly
collaborate
in
the
in
the
times
where
you're
firefighting
and
trying
to
triage
a
application
issue
or
performance
degradation.
A
You
can
quickly
jump
on
a
call
with
your
team
and
collaborate,
so
those
are
just
a
handful
of
the
current
features
within
the
ops
section,
as
I
mentioned,
the
general
theme
is
we
give
you
the
ability
to
get
started
with
these
operations
principles
quickly
as
a
developer,
and
then
we
make
it
really
integrated
into
the
rest
of
your
development
experience
with
that
I'm
going
to
jump
to
where
we're
headed.
So
that
was
an
overview
of
where
we
are.
Let's
talk
about
where
we're
headed.
A
A
They
can
they
can
have
that
tight
integration,
but
they
still
work
with
different
tools,
and
so
we
want
to
bring
them
together
under
the
same
tool
and
increasingly
that's
not
just
taking
an
old
style
of
working
for
operators
and
having
them
attempt
to
do
it
in
a
more
DevOps
friendly
fashion.
It's
about
having
developers
take
on
more
operations.
Test
developers
are
consistently
being
asked
to
for
more
tasks
that
were
traditionally
the
in
the
domain
of
operators.
A
So
are
we
think
of
these
opportunities
as
critical
to
informing
our
long-term
strategy,
which
again
is
to
complete
the
DevOps
loop?
Be
a
single
application
for
the
developer?
Who's
who's
team
and
organization
is
responsible
for
the
entire
DevOps
loop.
That's
not
bimodal
IT,
where
they're
handing
off
an
application
to
an
Operations
team
and
give
them
the
tools
to
perform
that
locally
and
make
it
a
great
experience.
So
it's
not
a
jumping
between
different
tools
that
they
might
have
to
do
today
in
the
short
term.
A
You
know
some
of
our
themes
include
doing
all
of
this
on
the
principles
that
get
lab
is
founded,
which
is
that
we
define
things
in
code.
We
started
with
great
source
control
management
and
then
created
CI,
which
you
define
encode
and
source
control.
Just
like
you
would
your
application
we're
doing
the
same
thing
with
infrastructure
and
observability.
We
want
to
give
you
as
a
developer.
A
My
ability
that
comes
with
knowing
that
you
define
something
in
code
in
written
form
and
that
that
is
immutable
from
that
point.
On
that
you
can.
The
only
way
that
that
is
going
to
change
is,
if
you
change
it,
with
a
merge
request
right
and
so
we're
gonna
rely
on
those
same
principles
as
we
pursue
the
operations
features
that
we
do.
We
are
working
to
make
sure
your
alerts
are
configured
as
code
that
the
metrics
that
you
set
up.
A
We're
also
really
interested
in
the
feedback
loop.
Now
it's
my
belief
that
when
we
talk
about
the
feedback
loop
for
DevOps,
we
typically
think
primarily
about
the
the
applications,
performance
or
availability,
but
there
are
so
many
other
characteristics
of
an
application
that
it's
really
important,
that
developers
get
the
feedback
for.
You
can
think
of
things
like
user
feedback
forums
or
real
user
monitoring
places
where
it's
the
quicker
iteration
you
get
from
feedback
from
real
users
to
developers
who
can
then
respond
to
that
feedback.
The
better
and
we're.
Really.
A
By
being
a
single
platform,
we
have
an
opportunity
to
make
that
feedback
loop,
smarter
to
ensure
that
there's
great
tracking
between
the
two
to
ensure
that
there's
not
context
lost
between
feedback
coming
in
from
one
end
of
the
DevOps
cycle
and
then
that
moving
into
planning
and
creating
on
the
other
side
and
then
the
last
one
is
one
that
I've
touched
on
a
couple
of
times,
which
is
operations
for
all.
We
understand
that
there
is
a
skills
gap
for
people
with
operational
knowledge.
We
want
to
make
it
as
easy
as
possible.
A
We
think
that
the
tools
available
today
give
IT
organizations
development
organizations
an
opportunity
to
to
quickly
adopt
some
of
these
patterns
and
mean
that
they
don't
have
to
be
operational
experts
in
order
to
operate
large-scale
applications.
And
so
we
want
to
keep
in
mind
that
we're
not
building
a
tool
for
the
person
who's
been
doing
operations
for
20
years
and
is
deeply
ingrained
in
it.
A
We're
building
a
tool
for
the
developer,
who's
getting
started
and
needs
to
operate
infrastructure
while
also
doing
their
day
job
of
writing,
new
application
code
and
features,
and
so
that's
a
really
important
distinction
in
our
approach
to
it.
We
we
are
here
to
make
it
easier
and
get
get
started.
It's
a
aligns
well
with
get
labs
value
of
convention
over
configuration.
A
We
want
to
make
sure
things
work
well
out
of
the
box
that
they
work
for
the
new
user
for
the
millions
of
people
who
are
coming
to
cloud
native
and
coming
to
kubernetes
and
coming
to
DevOps
today,
and
so
it's
important
that
we
make
that
really
easy.
Then
the
last
one
is
there's
a
general
theme
that
I'd
that
people
say
kind
of
pejoratively
this.
A
This
no
ops
team,
but
there
are
going
to
continue
to
be
abstractions
away
from
infrastructure
so
that
people
have
to
think
less
and
less
even
about
kubernetes,
which
helps
you
not
have
to
think
about
servers
and
where
your
application
is
running,
and
so
things
like
server
lists
and
other
paradigms
will
come
up
where
they
enable
developers
to
think
even
less
about
infrastructure.
Kubernetes
and
our
approach
to
kubernetes
already
does
a
lot
of
that.
If
you
set
up
a
kubernetes
cluster,
you
don't
have
to
think
to.
A
If
you
set
up
a
group
level,
kubernetes
cluster,
your
developers,
don't
have
to
think
too
much
about
where
their
application
is
landing.
They
get
a
lot
of
rich
context
about
how
it's
performing,
but
don't
think
too
much
about
the
infrastructure,
but
there
will
continue
to
be
more
and
more
layers
of
abstraction
that
we
want
to
make
sure
we're
supporting
the
kind
of
available
architectures
for
developers.
So
what
does
that
mean
for
our
one
year
plan?
You
know,
I
get
that
we
have
a
high
focus
on
dogfooding.
A
We
will
continue
to
focus
on
dog
fitting
throughout
this
year,
ensuring
that
our
own
operations
teams
are
using
these
tools.
We've
started
to
do
some
early
pilot
projects
for
doing
so,
but
we
think
that
dog
pruning
is
one
of
the
primary
ways
that
we're
going
to
increase
our
rate
of
iteration,
which
is
really
obviously
important
to
get
lab,
is
one
of
our
core
values.
A
Logging
we're
focusing
on
getting
our
logging
features
to
viable.
We
want
to
build
the
kind
of
dashboarding
and
less
dashboarding
for
looking
at
something
in
a
in
a
NOC
style
view,
but
more
dashboarding
for
if
you're
doing,
exploration
right,
the
dashboards
are
valuable
for
when
triaging
an
issue
you
need
to
explore
and
get
a
sense
of
what
actually
is
going
on,
we'll
continue
to
focus
on
instant
management,
IAC
enterprise
level,
cuban
kubernetes
management
and
server
lists.
So
those
are
the
things
that
we
are
focusing
on.
A
The
things
that
we're
not
focusing
on
is
you
know
we
are
recognizing
that
there
is
a
movement
in
the
industry
towards
more
platform
teams.
I
talked
about.
If
you
had
a
group
level
kubernetes
cluster,
that
gets
your
individual
developers
out
of
the
whole
notion
of
managing
kubernetes
or
attaching
a
kubernetes
cluster
to
their
individual
project,
we're
clearly
seeing
that
as
a
trend
from
our
users
and
from
the
industry,
and
so
we
want
to
focus
more
of
our
support
on
kubernetes,
about
managing
a
cluster
that
supports
multiple
projects
and
multiple
users
rather
than
the
individual.
A
I'm
attaching
a
kind
of
individual
kubernetes
cluster
just
for
my
singular
project
and
then
we're
not
going
to
be
as
heavily
invested
in
these
kind
of
out-of-the-box
monitoring
configurations
for
your
system
level.
Metrics.
We
really
want
to
focus
our
monitoring
and
metrics
capabilities
on
the
business
level,
metrics
that
impact
developers,
users
and
waking
them
up
at
night
for
those
types
of
metrics.
That
also
includes
kind
of
the
in-app
instrumentation
of
your
code,
with
a
bunch
of
different
legacy,
programming
languages,
we're
talking
about
cloud
native
developers.
A
So
we
are
focusing
on
more
modern
programming
languages
as
a
result.
So
that
is
an
overview
of
the
stage,
our
kind
of
thematic
viewpoint
on
it,
our
one-year
plan
and
also
kind
of
what
we
we
are
and
are
not
planning
on
working
on
during
that
one
year.
Plan
I
hope
that
that
is
informative,
I,
look
forward
to
any
and
all
feedback
about
our
plan.
Obviously,
everything
at
gate
lab
is
is
a
work
in
progress,
so
I
would
appreciate
any
contribution
and
feedback.