►
From YouTube: IETF104-TUTORIALGIT-20190324-1345
Description
TUTORIALGIT meeting session at IETF104
2019/03/24 1345
https://datatracker.ietf.org/meeting/104/proceedings/
A
Okay:
let's
go
ahead
and
get
started,
I'd
like
to
welcome
you
to
the
github
tutorial
I'm
Carolyn,
Donahue
I'm,
with
the
ietf
education
team,
I'd
like
to
seems
a
bit
echoey.
Doesn't
it?
Oh?
You
can't
hear
me
now.
You
can
hear
me
okay,
folks,
in
the
back,
can
you
hear
me
a
bit
better?
Oh
so
I
just
need
to
be
louder.
Okay,
so
we
can
cut
this
part
out
at
the
video
anyway
I'm
Carolyn
Donahue,
with
the
ietf
education
team,
I'd
like
to
welcome
you
to
the
tutorial
I'd.
A
Also
like
there's
going
to
be
a
survey
link
in
there.
I'd
really
appreciate
any
survey
results
that
you
have
any
any
thoughts
you
have
on
the
tutorial
itself,
additional
tutorials
that
could
possibly
be
offered,
and
the
other
thing
is.
The
edgy
team
is
actually
looking
for
additional
help
and
additional
resources.
A
So
if
you
are
willing
to
a
help,
provide
any
tutorials
or
be
helped
Shepherd
other
tutorials
or
do
other
work
associated
with
the
ietf
like
helping
organize
the
ietf
education
materials
on
the
website
or
on
the
wiki,
there's
just
a
long
list
of
opportunities,
and
we
would
love
to
have
you
with
that.
I'd
like
to
introduce
Mike,
Bishop
and
he'll,
be
talking
to
you
about
the
github.
B
All
right,
yes,
all
right
is
that
better
all
right
just
have
to
eat
the
mic,
so
my
name
is
Mike
Bishop.
Hopefully
those
closed
captions
are
not
too
distracting
and
might
be
helpful
for
someone
and
it
miss
transcribes
anything
like
my
name.
We
can
laugh
at
it
we're
talking
about
the
tools
that
are
available
for
using
markdown
and
github
to
keep
track
of
you
internet
graphs,
so
we'll
be
looking
at
basic
concepts.
B
But
if
I
can
just
get
a
show
of
hands
how
many
people
are
already
using
markdown
to
write
their
graphs,
fair
number
and
who's
familiar
with
git,
whether
an
ID
context
or
not,
most
people
I
will
skim
that
section
very
quickly
then,
and
do
you
use
github
already
for
things
similar
number?
Okay,
so
we'll
focus
mostly
on
how
to
get
things
set
up
and
not
as
much
on
the
tools
themselves,
but
I
will
still
take
a
quick
look
around
how
the
different
working
groups
are
using
things.
B
So
things
were
not
focusing
on
the
XML
RFC
v3,
not
diving
into
that
very
much.
There's
an
excellent
talk
about
that
previous
time
slot,
but
most
of
this
is
going
to
output,
be
two
for
the
time
being
and
you're
also
shielded
from
the
exact
version
of
the
output.
I.
Don't
want
to
get
into
the
details
of
whether
working
group
should
use
github.
B
There's
a
working
group
later
this
week
on
the
best
practices,
if
they're
going
to-
and
you
know
the
pronunciation
of
the
boss-
that
did
not
intend
to
form
a
working
group
and
did
let's
sleep
Evelyn,
so
I
think
the
best
tagline
for
using
markdown.
It
is
certainly
less
cryptic
than
XML.
It's
intended
to
be
something
that
somebody
can
read
through
and
it's
easily
consumable
in
the
base
text
format.
But
then
we
have
tools
that
can
take
that
text
format
and
spit
out
nice.
B
Easy
work
with
HTML
that's
convenient
for
reading
and
the
text
format
that
we
all
know
and
perhaps
love
the
front
helps
generate
all
the
boilerplate,
and
this
is
the
same
thing
that
you
would
find
at
a
beginning
of
an
XML
document
produced
XML
RFC,
basically
grab
somebody
else's
document
and
adapt
accordingly.
I
would
not
try
and
know
what
all
the
different
things
are
that
you
have
to
put
up
here
to
have
a
beginning
document.
B
There
are
a
couple
different
ways
that
you
can
do
references
this
was
alluded
to
in
the
previous
session.
You
can
be
very
explicit
and
write
it
out
yourself,
and
this
is
Gamal.
As
one
comment
noted,
you
have
to
get
the
spacing
exactly
right
if
you're
going
to
do
it
that
way,
but
each
document
has
a
normative
and
an
informative
section
at
the
beginning,
or
you
can
explicitly
list
out
the
documents
and
just
let
it
pull
from
the
database
of
all
the
RFC's.
All
the
internet
drafts.
Yes,
good.
B
B
B
So
you
can
take
the
you,
can
put
the
naiton
number
of
the
RFC
and
just
let
it
pull
in
and
populate
that
from
the
online
database
or
what
you
can
do
is
just
do
the
inline
references
and
not
even
mention
anything
up
front,
but
when
you
need
to
make
a
reference
to
a
document,
then
you
just
put
the
two
curly
braces
with
normative
or
informative
exclamation
mark
for
a
normative
question
mark
for
an
informative
reference.
The
other
nice
thing
about
that
is
that
you
can
give
a
different
name
to
that
reference.
B
So
I
want
to
call
RFC
7540
hgp
to
instead
of
always
referencing
by
number
I,
think
that
makes
for
a
nicer
output,
and
all
of
these
things
are
supported
by
the
XML,
but
you
can
use
crammed
down
and
markdown
formats
to
lead
into
it
so
just
skimming
through
here
within
the
middle
and
the
back
sections,
you
used
the
hashes
to
do
level
top
level
second
level,
third
level
headings.
If
you
go
past
third
level,
you
can
get
really
deep,
but
anything
below
third
level
doesn't
show
in
the
table
of
contents.
B
B
So
the
idea
is,
we
have
these
tools
that
let
you
start
with
markdown
and
use
cramdown
or
in
mark
or
some
other
options
to
turn
into
XML,
and
then
you
can
take
XML
tar
FC
that
can
give
you
the
HTML
output,
the
text
output.
You
can
use
PostScript
to
turn
text
into
PDF
and
those
are
all
great
as
standalone
tools
that
you
can
use.
B
C
B
B
B
B
So
I'll
try
and
commit
that,
and
it's
good
to
tell
me
that
I
actually
made
a
reference
to
69
1999
and
it
will
refuse
to.
Let
me
commit
it
because
I'm
making
a
reference
to
an
RFC
that
doesn't
exist.
So
one
nice
feature
here
is
that
it
will
actually
send
if
you
check
the
document
when
you
try
and
commit
it.
B
So
I'll
fix
that
and
go
back
and
now,
if
I
cam
in
it
it's
in
the
repo
it's
there
and
so
that
that
lets
you
get
different
outputs
and
you
have
the
check
before
you
go
in
other
things
that
you
can
do
just
from
the
local
repo.
If
I
tell
it
make
diff,
then
if
I
had
RFC
DIF
installed
sorry,
then
it
would
build
the
output
of
the
comparison.
B
B
B
B
B
So
if
I
wanted
to
go
in
and
take
a
change,
I'm
actually
not
going
to
go
into
how
to
use
up,
because
most
people
said
they
were
familiar
with
that,
but
the
process,
when
you
start
hooking
github
in
along
with
circle
CI.
That's
when
you
get
really
nice
automation
around
all
of
these
things.
So
you
have
your
local
copy
of
the
ID
template
and
you're
making
edits
and
each
time
you
can
build
it.
B
It'll
do
us
enemy,
check
and
produce
the
local,
HTML
and
text
that
you're
interested
in
when
you're
ready
to
push
that
to
github
fun.
Other
people
can
see
the
markdown
changes
that
you've
made,
but
github
enables
change
triggers,
so
external
tools
can
observe
when
something
changes
and
their
repository.
And
so,
if
you
set
up
a
trigger
with
circle,
CI
or
Travis,
which
are
both
supported,
CI
mechanisms,
then
you
can
have
them
run
their
own
container
with
a
copy
of
the
ID
template
and
what
they
will
build.
B
On
github
IL
and
the
name
of
the
repo
now
quick
actually
has
it
set
up
to
redirect
to
a
particular
domain
name,
but
that
the
generic
form
is
your
github
username,
dot,
github
and
dot
io
/,
repo
name
and
the
ID
template
will
build
for
the
master
branch
at
the
top
and
then
for
every
branch.
It
will
show
you
all
the
built
documents
of
the
current
state
of
that
branch.
B
B
Alright
and
it
can
upload
it
to
the
data
tracker
and
so
your
actual
workflow,
when
you're
ready
to
submit
your
document,
is
simply
build.
It
tag
it
and
push
the
tags,
and
then
you
get
the
email
that
asks
whether
you
in
fact
were
the
one
who
submitted
that
document
and
if
you
want
to
approve
it
for
publication.
B
B
So
when
you're
trying
to
set
up
a
repo
from
scratch,
a
lot
of
this
is
really
convenient
once
you
get
it
running,
but
the
difficult
piece
is
getting
bootstrapped
trying
to
take
an
empty
repo,
get
it
set
up
the
the
ID
template
setup.
Script
is
quite
good
about
telling
you,
when
you
haven't
done
something
correctly,
but
when
I
was
getting
started
with
it,
I
would
often
just
do
a
loop
of
run
set
up.
It'll
tell
me:
oh,
you
haven't
done
this
yet
and
then
I
need
to
go
fix.
It
fix
it.
B
There
are
some
setup
scripts
that
rich
sauce
has
written
that
are
intended
to
help
help
you
get
the
repo
set
up
in
the
first
place,
so
it
will
create
an
account
on
github
for
a
working
group,
and
it
will
let
a
working
group
or
an
individual
with
an
existing
account,
set
up
a
new
repo,
but
it
still
comes
out
as
an
empty
repo.
You
can
upload
a
upload,
a
template
to
it.
B
B
B
D
B
For
the
document,
so
one
of
the
things
that
we'll
be
discussing
in
the
get
working
group
for
best
practices
is
whether
you
should
have
a
single
repo
for
all.
The
documents
like
we've,
mostly
done
with
clique
or
whether
it's
better
to
have
individual
repos
per
document.
I
have
mostly
done
one
large
repo,
but
I
know.
The
tls
working
group
has
a
separate
repository
for
document
and
either
one
works
functionally.
It's
a
quick
one.
The
template
can
handle
having
multiple
drafts
present,
so
it
will
build
each
draft
that
it
lines.
B
B
You
run
make
and
point
it
to
that
setup,
location
and
then
what
the
template
is
going
to
do
is
first
check
that
your
draft
actually
is
present
and
build
and
has
already
been
pushed
up
to
github.
So
it
wants
to
make
sure
you
have
a
a
good
link
and
then
it
will
start
populating
a
readme
file
that
contains
the
name
of
your
draft
and
tells
people
what
working
group
its
affiliated
with
Tulse.
Then
the
discussion
should
happen
on
the
reading
on
the
mailing
list.
It
populates
a
contributing.
B
B
So,
at
the
end
of
that
set
up,
if
we
look
at
the
commits,
we
see
that
the
setup
script
added
a
new
commit
that
creates
all
these
files
and
it
added
a
gh-pages
branch,
which
is
where
the
built
documents
created
by
the
change
nun
by
the
CI.
The
continuous
integration
are
going
to
live.
But
if
we
go
back
to
our
github
repo
all
this
lives.
B
B
B
Now
we
should
be
able
to
see,
yes,
it
does
run,
and
so
what
this
is
going
to
do
is
every
time
you
push
to
the
repo.
It
will
build
the
documents
and
if
the
documents
don't
build
correctly
than
circle
will
send
you,
so
that
is
a
convenient
way
to
keep
them
keep
track,
particularly
if
you
have
lots
of
people
collaborating
on
a
working
group
repo
that
if
somebody
breaks
the
build
you
find
out
about
it.
B
If
we
go
to
the
gh
pages,
it
doesn't
actually
push
back
because
circle
needs
permission
to
do
that,
so
you
set
that
out,
you'd
be
going
to
github
settings
and
they
hide
it
under
developer
settings
to
get
the
access
to
its
an
access.
Token
there's
something
that
is
not
your
password
that
can
be
used
to
talk
to
github
on
your
behalf,
so
you'll
create
one
with
whatever
permissions
you
want.
The
only
permission
that
it
requires.
B
B
So
that
in
the
settings
for
each
project
that
goes
in
as
environment
now,
since
I
already
have
it
set
up,
I
will
go
to
a
different
repo
and
copy
it
over.
The
name
of
the
name
of
the
variable
is
gh
token,
and
you
paste
end
the
token
that
you
got
from
get
out
the
other.
The
other
place
where
those
tokens
are
useful
is
you'll
need
them
at
the
command
line
to
interact
with
get
up.
B
B
B
So
if
you
look
at
the
commit
history,
first
thing
it's
going
to
show:
you
is
with
each
commit,
so
you
know
when
CI
tries
to
build
it,
even
if
it
doesn't
have
the
token
and
that
will
report
back
to
github
whether
that
version
in
that
commit
was
able
to
build
successful.
So
you
can
easily
see
this
one
it
wasn't
able
to
build.
B
One
thing
to
note
is
that,
in
order
for
circle
to
do
this
and
do
the
auto
submission
to
the
data
tracker,
it
has
to
be
an
annotated
tag,
which
means
you
have
to
give
it
a
message
to
go
with
the
tag,
but
the
actual
content
of
that
message
doesn't
matter
at
all,
so
you
have
to
pass
something.
It
will
fail
if
you
don't,
or
rather
it
will
bring
up
the
editor
and
ask
you
to
type
it.
B
You'll
see
that
that
tag
is
also
something
that
it
will
build
on,
and
the
last
step
we're
gonna
just
build
is
that
it's
going
to
use
curl
to
upload
it
to
the
data
tracker,
which
will
generate
an
email
to
all
the
listed
authors
and
I've
already
told
Ben
that
you
should
not
respond
to
any
emails
from
the
day
detector
about
this
draft
today
and
I'm
going
to
cancel
the
submission
when
I
get
the
email.
That
assumes
that
I
guess
on
the
fast
version
that
when
the
data
tracker
doesn't
reject
it.
B
So
the
last
step
is
part
of
the
build
process.
You
can
see
the
upload
to
data
tracker
and
it's
looking
for
a
200.
Ok
coming
back,
and
if
it
doesn't
get
a
success
on
the
submission,
then
what
it
will
do
is
email
me
that
the
built
failed
on
that
tag
to
say
it.
Couldn't
it
couldn't
submit
to
the
data
tracker.
You
may
need
to
do
that.
B
So,
to
recap:
how
we
do
that
setup?
First,
you
need
all
the
local
tools
you
have
to
have
get
and
make
for
the
template
to
work.
Xml
RFC
depends
on
Python
from
down
RFC
two-six
two-nine
requires
roogie
and
those
can
be
installed
with
their
appropriate
handlers.
Actually
apt
is
able
to
take
all
of
these
directly.
So
if
you
just
go
and
ask
for
those
four,
you
can
get
more
current
versions
of
XML
by
RFC
off
of
the
pipe
I
installer
and
cramdown
can
come
off
of
rubygems
on
the
cloud
side.
B
You
need
to
create
your
repo
either
script
or
manually,
and
you
need
access
tokens
to
give
to
circle
and
then
on
circle.
You
need
to
set
it
up
to
follow
the
repo
and
you
need
to
have
the
access
token
in
the
environment
variables
if
you
want
it
to
actually
populate
back
to
the
repo
on
your
path,
so
full
disclosure,
while
I,
have
made
some
contributions
to
the
IV
template
I'm,
not
the
one
who
wrote
it.
That
would
be
Martin
Thompson.
B
So
if
this
looks
like
a
tool
that
will
make
authoring
internet
graphs
easier
for
you,
I
would
say,
buy
him
drink.
I
have
found
it
to
be
a
lot
simpler
than
trying
to
mess
with
the
XML,
which
I
did
at
the
beginning
of
my
time
and
the
IETF.
But
at
this
point
I
am
marked
down
for
basically
everything
mostly
for
reviewing
the
slides.
B
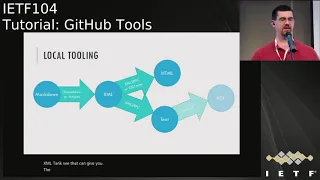
Later
I've
got
some
basic
like
what
community
would
use
and
get
for
different
tasks,
and
that
is
the
end
of
whatever
we're
a
lot
we're
way
under
time,
because
I
skimmed,
through
the
things
that
look
like
most
people,
were
familiar
with.
But
if
there's
anything
that
you
want
me
to
go
back
and
go
into
more
detail
on
I'm
happy
to
do
that
happy
to
stick
around
the
news
or
questions.
E
B
B
B
We
know
we
have
experienced
that
circle
is
more
reliable
for
building
things
and
also
it
passes
more
information
into
the
environment
of
the
build
that
the
template
is
able
to
pull
on.
If
you
open
up
some
of
the
make
file
scripts
they're
part
of
the
template,
you
can
see
comments
like
if
this
is
Travis.
This
is
not
populated.
We
have
to
attempt
to
guess
it.
C
E
Actually,
on
that,
I
could
continue
yeah,
please
the
the
reason
I
asked
about
github
and
I
mentioned
it
lab
as
well
is
because
a
good
lab
it
could
be
self
hosted
and
it
wouldn't
be
on.
You
know,
startups
going
out
of
business
or
things
like
that
I
mean
had
the
Microsoft
owning
github
is
pretty
reassuring,
I
guess
in
the
long
run,
but
for
some
of
the
other
tools
that
are
related
to
it.
It
might
make
sense
for
the
IDF
tools
to
also
be
open-source
and
be
able
to
be
self
hosted
by
by
authors.
Yeah.
B
So
a
lot
of
that
discussion
is
likely
to
happen
in
the
get
working
group
later
this
week.
Their
Charter
is
to
come
up
with
best
practices
for
get
the
git
and
github
use
at
the
IETF,
we're
chartered
to
focus
specifically
on
github,
but
the
question
of
whether
any
of
the
tools
need
to
be
self
hosted
and
managed
by
the
IETF.
Even
if
there
are
third-party
at
once,
is
definitely
going
to
come
up.