►
From YouTube: 4. Introduction to cuDF
Description
From the NERSC NVIDIA RAPIDS Workshop on April 14, 2020. Please see https://www.nersc.gov/users/training/events/rapids-hackathon/ for all course materials.
A
Great,
so
for
the
next
45
minutes,
before
lunch
or
lunch,
if
you're
in
the
Pacific
Standard
time
zone,
we
are
gonna,
be
going
over
one
of
the
notebooks
that
was
sent
out
for
the
flipped
classroom
aspect
of
this
workshop.
This
is
gonna,
be
an
introduction
to
the
ku
DF
library
and
for
those
who
have
had
a
chance
to
work
on
the
homework.
Thank
you
for
that.
We'll
be
reviewing
it
and
also
taking
questions
on
that
as
well.
For
those
who
have
not
had
a
chance
to
get
started,
that's
okay!
A
We
are
not
going
to
be
going
into
depth
about
all
aspects
of
it,
so
we
we
encourage.
You
to.
You
know,
take
some
time
on
your
own
to
do
this
as
well,
but
we
will
be
covering
the
entirety
of
both
of
these
notebooks,
so
I'm
going
to
quickly
share
my
screen
again
and
also
if
there
are
questions
that
you
feel
like
asking,
please
do
use
the
chat.
I
think
that
that
system
worked
really
well
in
the
last
session
is
what
the
last
session
as
well.
A
A
Okay,
so
again,
hopefully
some
of
you
had
a
chance
to
work
on
this.
If
not
that's,
okay,
this
is
gonna,
be
a
fairly
comprehensive,
but
you
know
high
level
overview
of
the
KU
DF
library,
it's
geared
for
new
users
and,
if
you're
familiar
with
pan
there's
a
lot
of
this
should
look
very,
very
familiar,
so
we're
gonna
start
by
introducing
pandas
and
then
move
on
to
ku
DF
in
case
some
folks
are
not
as
familiar
with
pandas.
A
A
Pandas
is
for
structured
and
unstructured
data,
usually
in
the
form
of
text,
not
really
images
in
video,
it's
more
about
structured,
structured
data
and
it's
a
data
frame
tool
that
lets
you
do
things
like
this,
so
in
this
case
we're
using
pandas
0.25,
which
I
think
is
the
current
release
all
right.
Sorry,
it's
the
release
before
the
current
one.
Are
there
now
at
1.0?
And
so,
unless
you
do,
things
like
create
a
data
frame.
A
Put
some
values
in
a
column
and
put
some
more
values
in
a
column,
this
is
sort
of
very
basic
Python
syntax
for
creating
floats
in
you
know,
a
range
of
numbers
and
you
end
up
with
this
object.
This
is
a
data
frame
that
has
two
columns
each
of
these
things,
and
you
can
do
things
to
it.
Like
summations
can
do
aggregations
and
you
can
do
all
sorts
of
different
things.
A
These
are
actually
guidelines
in
that
West,
McKinney
who's,
the
lead
developer
and
creator
of
pandas
has
put
together
and
the
reason
for
that
is
complicated,
but
it
relies
on
the
way
Pam.
Does
this
internal
structure
called
the
block
manager
handles
things,
but
the
result
of
that
is
you
know.
Pandas
is
an
incredibly
powerful
tool,
but
it
can
run
into
problems
with
efficient
computation
and
problems
with
blowing
up
memory.
A
So
coup
DF
is
the
GPU
version
of
this
designed
to
solve
a
lot
of
those
problems
and
to
be
faster
and
stay
on
the
GPU
and
you'll
notice.
Now
that,
in
the
nest
in
this
code
block
right
here
that
I'm
about
to
run,
this
is
gonna.
Look
just
like
this
code
block.
You
know
we're
doing
the
exact
same
code
right
here
that
we
did
with
pandas
with
kudiye.
A
We
do
it
with
kudiye
it's
the
same
code
said
we
use
a
cou
DF
data
frame,
the
CUDA
data
frame
and
we're
using
ku
DF,
actually
I'm,
actually
I
apologize
I'm,
actually
using
a
version
ahead
of
this
the
stable
release,
we
release
nightly
versions
as
well.
Every
time
we
make
a
new
change,
there's
a
new
version
that
you
can
get
if
you
want
to
get
the
tip
of
the
sphere
development
version
I
apologize
for
not
pinning
mine
to
the
0.13,
but
all
the
features
will
work
in
that.
A
A
The
syntax
is
the
same.
This
is
important
because
it
allows
you
to
be
productive,
and
sometimes
it
also
allows
you
to
just
drop
in
replace
some
of
your
existing
code
and
put
it
on
the
GPU.
It
reduces
the
cognitive
burden
and
lets
you
focus
on
the
actual
workflows,
and
so
now
we're
going
to
go
through
through
the
basics
of
crude
EF,
and
there
are
some
exercises
which
we
can
go,
which
we
will
go
over
for
those
who
have
not
yet
had
a
chance
to
look
at
this.
Their
solutions.
A
Excuse
me,
the
solutions
to
the
exercises
are
in
the
notebooks.
So
it's
when
you
do
this
later
or
if
you
do
it
later,
try
not
to
cheat
and
look
at
the
solutions,
but
they
are
there.
If
you
need
them,
and
so
you
can
do
things
like
create
series.
You
know
a
series
is
an
individual
column
of
data.
Just
like
pandas,
you
can
do
it
with
nulls.
You
can
do
it
out
and
nulls
kudiye
supports
extensive
list
of
operations
that
fully
support
nulls.
You
could
also
create
the
data
frames
like
before
you
can
create
them.
A
You
know
you
can
think
of
a
data
frame
as
just
being
this
one
is
just
three
separate
columns.
You
know
this
is
one
column.
There's
three
columns
here
in
this
case
you're
just
some
integer
columns.
You
can
also
create
AB
data
frame
in
a
different
way.
I
see
there
may
be
some
questions
Laurie.
If
there's
any
questions
that
you
think
are
worth
stopping
for
it.
Please
just
just.
B
A
So
if
you
noticed
here
that
these
data,
you
know
these
data
frames
are
being
created
on
the
CPU
right
we're
doing.
This
is
a
standard
Python
operation
we're
creating
this
in
the
CPU.
We
can
also
create
this
directly
on
the
GPU
by
using
other
tools
and
we'll
show
an
example
of
that.
But
keep
that
in
mind
now
you
might
already
have
a
data
frame.
Maybe
you
have
a
panda's
data
frame
on
the
CPU
and
you
want
to
make
that
your
ku
DF
data
frame.
You
can
do
that
too.
A
Ku
DF
provides
a
from
pandas
API
that
lets
you
take
pandas
dataframe
and
put
it
on
the
GPU
in
the
same
way.
Now,
just
like
you
would
do
with
pandas,
you
can
do
things
like
call
head
and
note
that
I'm
using
prints-
but
you
know,
there's
no
need
to
use
print
ear.
Just
depends
on
different
people's
machines
and
has
more
consistent
to
use
print.
You
can
use
head
to
get
the
first
two
rows
or
to
get
the
first
five
rows,
you
can
do
a
sort.
A
This
is
the
same
API
as
pandas
for
those
of
you
who
are
aware
you
can
sort
by
one
of
these
columns
in
this
case
that
column,
B
I
can
also
decide
if
I
want
to
sort
ascending
in
this
case.
I
didn't
want
to
sort
of
send
it,
but
by
default
you
will
that's
consistent
with
pandas.
Now,
just
like
pandas
as
well,
you
can
do
things
like
select
columns.
You
can
select
rows,
you
can
select
all
sorts
of
things
and
you
can
use
this
syntax.
You
know
for
those
of
you
familiar
with
Python.
A
This
is
the
get
item
syntax.
So
essentially,
this
is
using
a
get
item
operator
of
this
data
structure.
This
is
a
canonical
Python
data
structure,
there's
TV
a
Python
method
of
a
class,
and
it
defines
this
protocol,
which
is
essentially
actually
called
to
get
item
protocol
and
it
lets
you
grab
things
from
this
data
structure.
So
this
is
column
a
we
can
also
grab
column
C.
A
We
can
also
select
by
label
this
dot.
Loc
got
Lok.
This
is
the
same
kind
of
API
for
pandas.
In
fact,
it
is
actually
the
same
API
and
it
lets
us
grab
specific
rows
and
specific
columns
by
name.
If
we
were
so
inclined,
we
can
also
grab
by
only
position.
We
don't
have
to
grab
by
name.
You
can
get
the
first
row
notice
that,
like
pandas,
the
first
row
here
is
returned
as
its
own
column.
That's
consistent
with
pandas.
You
can
also
grab
the
first
several
rows
of
the
first
two
columns
again.
A
This
is
spec
position
rather
than
by
name,
and
you
can
also
use
direct
access.
It's
you
know
it's
generally
better
to
use
these
I,
lock
the
index,
location
and
lock,
but
you
can
use
direct
access
and
so,
as
an
exercise,
you
know
actually
I
think
I
may
have
already
put
the
solution.
This
one
I
apologize,
but
you
can
try
to
select
only
rows
at
index,
4
and
9,
and
so
you
can
do
this.
A
You
might
want
to
pass
4
&
9
like
this,
but
you'll
get
an
error
because
it's
expecting
this
to
be
inside
of
a
list,
that's
similar
to
pandas,
and
that's
going
to
give
you
those
two
rows.
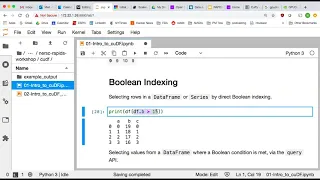
You
can
also
do
more
complicated
things
like
create
filters
on
data
sets
by
using
boolean
indexing,
and
what
that
essentially
does
is
lets
you
filter.
So
in
this
case
we're
gonna,
say
I'd,
like
all
of
the
rows
in
which
the
value
for
column
B
is
greater
than
15.
A
That's
what
we
got
and
as
expected,
if
you
were
to
take
this
out,
this
would
create
that
boolean
index.
You
know
it's
true
for
these.
It's
false
for
these,
just
like
in
in
pandas
world,
there's
also
a
query
API.
You
know
you
can
use
the
query
API.
Instead
of
doing
things
like
this,
you
can
say:
I
want
things
where
B
equals
3.
Okay,
you
can
also
pass
variables
to
this.
You
know
if
you
have
a
local
variable
to
find
you
can
pass
it
in,
and
you
know
this
is
something
that
is
generally
pretty
useful.
A
You
can
also
do
this
with
the
local
dict
keyword.
You
could
pass
this
as
a
keyword
argument
to
look
with
local
dict
and
you
would
just
pass
it
there.
You
know
you
could
rename
this
something
else,
and
so
this
lets
you
do
all
sorts
of
kinds
of
operations.
The
standard
boolean
operations
are
also
boarded,
and
so,
as
an
exercise
you
know,
I
will
go
through
this
trying
to
select
the
rows
in
the
data
frame
where
the
value
and
B
is
greater
than
C
plus
6.
So
I
want
to
select
where
the.
A
Plus
bfb
is
greater
than
DFC
plus
6,
and
there
we
go
once
we
get
down
to
here.
You
know
this
is
6.
Plus
6
is
12.
Once
we
got
to
7,
it
would
no
longer
be
true,
and
so
we
don't
get
that
as
a
result,
and
you
could
see
the
solution
if
you're,
following
along
on
your
own
notebooks
missing
data,
is
also
supported.
We
can
do
things
like
filling
in
missing
values.
We
can
do
things
like
descriptive
statistics,
I
create
a
series,
in
this
case
just
from
0
to
9.
A
A
We
can
also
apply
functions
and
in
the
next
notebook
part
of
the
homework,
we
will
see
more
depth
about
how
you
can
do
this,
but
you
can
naively
do
a
lot
of
things
with
just
basics.
You
can
add
10
to
every
value
in
a
series
now
keep
in
mind
that
currently,
as
of
today,
qu
DF
does
not
support
applying
custom
functions
on
string
columns.
It
only
supports
this
today,
4
columns
that
are
not
strings
so
numeric
or
daytime,
but
generally
numeric
columns,
but
it
works.
And
it's
nice.
A
We
have
a
full
support
of
string
methods,
but
we
don't
yet
support
user-defined
functions
for
string
methods,
but
so,
for
example,
you
know
I
encourage
you
to
check
out
the
documentation.
I
have
our
home
page
documentation
right
here.
This
is
the
rapids
site,
Doc's
dot,
rapids
AI,
and
there
are
links
to
this
in
the
jupiter
notebook
to
see
the
kudi
F
or
the
strings.
Api
guides
themselves.
But
you
can
do
things
like
lowercase
your
strings.
A
You
can
do
all
sorts
of
different
things
such
as
uppercase
them
and
as
expected
it
will
follow
the
same
API.
So
we
can
uppercase
our
strings,
which
look
like
this
with
that
Str
accessor.
This
is
something
that
those
of
you
who
are
familiar
with.
Pandas
should
recognize.
This
is
the
string
accessor
and
it's
how
pandas
exposes
its
string
functionality.
Kuh
DF
is
the
same.
It's
the
same
API
and
there
you
go
off
to
the
races
things
like
concatenation.
A
A
This
should
look
very
familiar
for
those
of
you
who
have
used
pandas
before
you
can
append,
essentially
just
a
large
in
a
single
type
of
concatenation.
You
can
do,
joins
and
merges
in
this
case
we're
just
creating
some
data,
we're
doing
a
left
joint,
just
like
pandas
on
the
key
and
we're
getting.
The
result.
Note,
though,
that
our
order
has
changed
by
default.
A
Parallel
joins
will
not
preserve
order,
because
that
would
add
an
explicit
step
to
the
operation
which
may
reduce,
which
would
hurt
performance.
You
can
enforce
this,
but
by
default
the
default
join
will
not
enforce
order,
so
the
exercise
is
to
do
an
inner,
join
and
so
to
do
an
inner
join
in
this
case
just
like
before
you
would
do
DF
a
dot
merge
with
DF
b
we're
gonna
say
I
want
to
do
an
inner
join,
not
a
left
join
and
we're
gonna
join
on
this
key.
A
Now,
if
the
keys
were
different,
we
could
actually
use
a
different
syntax
where
we
started.
We'd
have
to
use
a
different
syntax
note
that
the
inner
join
does
not
return
the
other
values
that
they
didn't
actually
have
a
collision
on.
It
only
returns
the
ones
that
collided
the
three
rows
if
the
keys
were
different,
we'd
have
to
use
the
left
on
and
the
right
on
arguments
now.
In
this
case
the
keys
are
the
same,
so
it
doesn't
actually
cope.
Sorry,
it
doesn't
actually
matter,
but
they
were
different.
You
know
if
this
was
key.
A
Five
key
four,
and
this
was
key.
Three
then
we'd
have
to
do
it
like
this.
That's
a
joint
like
pandas.
We
also
support
group
bys
and
this
sort
of
split
apply
combined
paradigm
for
those
of
you
who
use
our.
You
may
be
familiar
with
this.
You
know:
Hadley
Wickham
isn't
a
lot
of
really
good
research
and
and
infrastructure
development
around
this
kind
of
design,
oriented
data
flow,
and
it's
a
really
fantastic
paradigm,
and
we
support
this
fully.
You
can
do
things
like
aggregations.
A
Do
group
buys
call
some.
You
can
do
more
complicated
group
ice
where
you
want
to
do
things
differently
to
different
columns.
You
can
also
do
multiple
things
to
this
column
by
putting
in
a
list-
and
you
know
I
could
do
count
here.
As
you
can
see,
it's
quite
comprehensive,
oh
well,
I
guess
I
sort
of
got
ahead
of
myself,
but
you
can
do
this
multiple,
multiple
at
once.
You
can
also
group
by
multiple
columns.
A
A
Now
we
also
have
time
series
work
that
we
support,
which
is
great
the
time
series
work
is
using
the
GPU
based
you
know
the
date
time
variable
and
date
time
data
structure,
and
so
you
know
this
is
a
coup
DF
data
frame
that
we
put
a
pandas
date
range
into.
You
know
we
could
have
created
this
on
the
GPU,
but
first
for
showing
it.
You
know
right,
I'm,
sorry,
we
can
look
at
the
D
types
here.
We've
got
a
date/time
nano
second
precision
column
and
of
course
we
have
a
float.
A
Column
fully
supports
this,
and
so
you
know
if
we
want
to
do
things
with
this,
we
can
use
the
query,
API
or
use
dot,
lokor
all
sorts
of
different
things,
and
you
know
if
we
want
to
do
this
query.
For
example,
you
know
we
want
to
query
only
the
rows
with
a
a
time
before
this
date.
Well,
how
would
we
do
this?
If
we
used
query,
would
we
possibly
run
through
a
problem
here?
We
could
say
I
want
to
use
the
date
that
is
before
2018
11:23,
but
remember
we
don't
support
types.
A
A
Sorry,
taped,
yes,
nothing,
and
so
here
again
we
reach
the
problem.
We
can't
do
a
date/time
operation,
yet
with
a
string.
So
what
we
do
instead
is
use
the
timestamp
operation,
and
so,
if
we
do
pandas
timestamp,
we
can
see
now.
This
object
is
gonna,
create
a
day
time
object.
And
so
now,
if
we
took
this
string
right
here
and
said.
A
With
this
time
filter
now,
we
know
how
to
handle
this
and
we're
off
to
the
races,
and
so
this
is
an
example
of
how
we
can
naturally
support
interaction
between
date/time
variables
and
date/time
columns.
All
sorts
of
things
like
that,
there's
also,
of
course,
like
pandas,
more
detailed
things
like
you
can
take
the
minute
you
can
get
Oh
second
hour,
etc.
Well,
go
on
there's
a
lot
of
them.
I
won't
go
through
the
whole
thing
and.
A
You
can
do
all
of
them,
which
is
great
now.
Some
of
you
probably
used
coop
is
coop.
I
is
the
GPU
array,
library,
with
a
numpy,
consistent
API,
and
so
ku
DF
and
coop
I
play
together
incredibly
well.
In
fact
they
play
together
without
having
to
make
copies.
So
you
can
go
between
worlds
without
having
to
take
time
copying
data
in
between
and
for
any
data
frame
or
a
column,
a
series
you
can
call
the
dot
values
API
just
like
in
pandas
to
go
to
a
coupie
array
in
pandas.
A
Now
you
can
also
go
to
pendants,
you
can
call
to
pandas
and
it
will
just
put
your
data
frame
on
the
CPU
as
a
panda's
data
frame
being
consistent
with
your
data
types,
with
your
null
handling
with
your
all
sorts
of
things,
and
you
can
also
go
to
numpy.
If
you
wanted
to
you
can
call
as
matrix.
You
know
you
can
also
do
this
by
going
to
coupon
and
keeping
things
on
the
GPU.
A
A
We
can
read
that
file
and
if
the
same
API
is
pandas,
and
so
that's
it
that's
the
sort
of
the
intro
to
Kiev,
and
you
know
for
the
next
20
minutes,
we'll
go
into
the
user-defined
functions
section,
but
before
we
do
that,
I
want
to
show
an
example.
If
you
know
what
the
performance
can
really
mean,
you
know.
So
if
we
had
some
random
values,
no,
just
in
this
case
10
million,
make
it
make
a
data
frame
both
in
the
pandas
world
and
the
cou
DF
world
to
to
call
some
on
this
for
pandas.
A
You
know
I'm
one
of
the
columns-
it's
not
too
time-consuming
in
this
case
we're
using
time
it
to
you
know,
get
a
good
estimate
pretty
fast
60
milliseconds
for
the
GPU
300
microseconds.
That's
you
know
quite
a
bit
faster,
and
in
this
case
you
know,
perhaps
it's
not
so
significant,
because
you
feel
need
to
call
some
once
you
know.
16
milliseconds
is
probably
ok
but
think
about
a
more
realistic
example.
You
know
often
we're
doing
operations
many
times
and
so
in
this
case
we're
gonna
simulate
some
sensor.
A
Data
sensor
data
is
relevant
for
a
lot
of
workflows
and
it's
actually
particularly
relevant
because
it's
kind
of
kind
of
data
we're
gonna
be
doing
later
and
one
of
the
nurse
cork
flows,
but
in
this
case
we're
gonna
simulate
some
sensor
data
with
pandas
we're
going
to
imagine.
We
have
a
time
series
going
from
one
day's
worth
of
data,
20:19
August,
sorry
July
5th,
through
the
6th,
with
a
value
for
every
millisecond
and
then
we're
gonna
extract
the
hour,
extract
the
minutes,
print
the
shape
and
get
the
data's
head,
and
so
that's
took
20
seconds.
A
You
know
took
20
seconds.
It's
a
lot
of
data,
it's
86
million
rows,
that's
a
lot
of
data,
but
it's
only
imagine
one
sensors
worth
of
data
from
one
day,
it's
potentially
very
small
and
a
group
buy
on
this.
You
know
who
wants
to
say:
I
want
the
max
value
for
every
thing
on
an
hour
and
minute
basis
for
seconds.
Imagine
doing
this
for
all
of
your
sensors.
If
you
had
a
fleet
of
sensor,
this
would
take
forever
well
with
qu
DF.
We
can
do
this
much
faster
in
this
case.
A
We're
actually
gonna
run
the
same
code
except
just
put
it
in
a
cootie
F
data
frame,
so
we're
doing
the
data
generation
on
the
CPU
so
but
we're
gonna
just
put
it
on
the
GPU
and
show
you
how
it's
far
faster
to
do
this
on
the
GPU
all
these
processing.
In
this
case,
actually
we
added
second
thing
that
we
did
the
first
time,
but
we
added
seconds
it
still
took
only
two
seconds
compared
to
20
seconds,
the
group
by
52,
milliseconds
versus
you
know
four
or
five
seconds:
that's
a
hundred
times
faster.
A
This
is
just
one
example
of
a
group
by
it's
a
hundred
times
faster.
Other
group,
bys
might
be
50
times,
others
might
be
three
hundred
times
faster.
It's
gonna
depend
of
course,
and
so
you
know
I
encourage
you
to
play
around
to
get
a
sense
of
you
know
how
this
works,
but
at
a
high
level
that's
sort
of
coup
DF.
It
is
a
fully
featured
GPU
based
data
frame
library
and
Lauri.
Perhaps
maybe
we
should
take
some
questions
now
before
we
move
on
to
the
next
section.
B
A
B
C
A
A
There's
no
real
drawback
in
this,
but
in
general
it's
it's
better
in
the
there's
a
reason
in
the
pandas
world-
and
it
applies
here
as
well.
It's
better
to
be
explicit
and
using
lock
when
you
do
boolean
indexing,
because
often
what
happens
is
we're
gonna,
do
a
series
of
boolean
indexing
in
operations
and
then
in
a
panda's
world.
You
might
see
this
warning.
A
Perhaps
many
of
you
have
seen
it
that
says
setting
with
copy
and
it's
not
an
error,
it's
a
warning
that
tells
you
you're
setting
with
a
copy
and
that's
a
result
of
boolean
indexing
and
to
create
a
new
view
on
a
data
set
versus
a
copy
and
then
doing
operations,
and
it
can
cause
unexpected
results.
So
while
this
does
work-
and
it
will
of
course
behave
correctly,
it
often
is
more
robust
to
use
this
specific
access.
Err.
A
A
A
Question
so
you
can
do
both
so
in
this
notebook
we
actually
link
out
to
our
Docs
that
have
an
example
of
using
number
directly
for
the
weights.
Maybe
pianos
well
it's
somewhere,
but
we
have
some
Doc's
that
show
how
you
can
use
them,
but
directly
as
well,
and
the
reason
you'd
want
to
potentially
use
number
directly
would
be.
A
If
you
need
to
do
things
that
don't
naturally
map
to
the
dataframe
world,
you
would
want
to
use
number
directly
if
you
can
map
your
functions
and
you
want
to
have
it
just
kind
of
work
in
the
data
frame
world
and
put
your
things
in
a
data
frame
by
default.
This
is
a
nice
convenient
API,
but
you
can
of
course,
use
number
directly.
A
Great,
so,
essentially
in
this
in
this
function,
to
create
a
user-defined
function,
you
do
have
to
rely
on
number
and
so,
for
those
who
are
not
familiar
number
is
a
just-in-time
compiler
for
Python
code
to
transform
that
into
an
intermediate
representation
that
then
will
run
much
faster
because
it's
I
believe
it's
LLVM
compiled
then
for
the
CPU,
the
GPU.
It
gets
eventually
compiled
down
to
something
called
PTX
code,
and
we
use
this
under
the
hood,
for
these
apply
ROS
api's
that
lets
you
do
things
like
write.
A
function,
call
that
we
called
kernel
to
choose.
A
Some
columns
operate
on,
to
name
the
output
column
and
you
can
even
pass
values
into
it
and
there's
a
lot
of
stuff.
You
can
do
here.
I'm,
not
gonna,
go
through
all
the
exercises,
but
I
will
go
through
one
and
mention
that
now
this
actually
has
been
wrapped
up
into
a
new
library
that
we
have
in
the
rapid
world
called
coup.
Spatial
for
spatial
data
analytics
this
haver
signed
distance
function
is,
you
know,
fairly
commonly
used.
A
This
has
been
wrapped
up
into
a
nice
API
as
well
as
many
other
things
like
points
and
polygons
trajectory,
modeling
and
all
sorts
of
stuff,
but
so
this
you
know
this
exercise
is
to
calculate
the
Hammerstein's
distance
between
two
points.
For
all
your
all
the
points
and
it's
a
fairly
complex
algorithm,
a
lot
of
steps.
A
So
to
do
this,
you
would
just
run
this.
It's
actually
pretty
straightforward.
We're
gonna
define
the
columns
we
care
about
in
this
function
and
then
we're
gonna
have
our
output
column,
and
we
took
this
example
from
a
stack
overflow
post
by
someone
named
michael
dunn.
In
order
to
do
this,
you
have
to
enumerate
and
loop
through
your
columns
and
so
we're
looping
through
the
four
columns
and
we're
keeping
track
of
our
index.
A
A
You
need
to
actually
be
a
little
more
explicit
in
making
sure
that
your
threads
are
writing
to
the
correct
spot,
and
it's
it's
not
hard,
but
you
need
to
be
a
little
more
explicit
than
just
looping
through
and
that's
one
advantage
of
doing
it
like
this.
We've
taken
care
of
that
for
you,
but
you
can
see
that
you
know
we're
just
doing
some
math.
You
know
this
algorithm
is
just
math
and
we've
imported
the
standard
math
functions
from
pythons
built-in,
math
library
we're
doing
some
math.
We
are
printing
some
stuff
out
just
for
visual
sakes.
A
We
don't
need
to
do
this
and
then
we're
putting
our
output
and
each
thread
will
write
independently
in
parallel
to
this
column
and
we'll
run
it,
and
we
can
see
that
we
have
the
output
and
I
mean
we
know
it's
correct.
We
had
print
statements
in
our
code.
These
did
not
print
here
because
this
print
is
actually
running
on
the
terminal
from
which
this
was
launched,
which
is
not
shown
in
the
screen,
but
it
would
show
us
that
for
every
single
one
of
these
iterations
that
are
happening
in
parallel,
a
lot
of
things
are
happening.
A
A
We
have
two
blocks
shown
but
or
I
guess
we
have
a
few
blocks
shown,
but
you
can
find
more
information
about
what's
going
on
here
and
apply
rows
handles
it
all
for
us,
and
so
the
exercise
is
to
modify
this
to
pass
in
the
radius
of
the
earth
as
a
keyword
argument.
So
we
saw
that
right
here
we
passed
the
radius
of
the
earth
6371,
but
if
we
were
on
Mars,
this
would
be
completely
incorrect
and
I.
A
A
A
A
Sorry,
it's
a
lot
of
scrolling
a
lot
of
times.
We're
gonna,
see
typing
errors
when
we
use
number.
In
this
case
we
have
an
issue
with
the
wrong
type
of
argument
being
passed
and
so
we're
right
here.
It's
expecting
to
be
slightly
different,
and
so
perhaps
it's
a
little
bit
it's
just
a
little
bit
finicky
or
perhaps
I
made
a
subtle
I.
B
Yep,
okay,
but
we
do
have
a
question
from
Alex,
so
maybe
you
could
answer
so.
He
says
when
the
hammer
same
distance
kernel
is
invoked,
the
grid
and
the
block
dimensions
are
not
specified.
Can
we
invoke
the
kernel
and
explicitly
define
the
number
of
threads
in
a
block
and
the
number
of
blocks
in
the
grid.
A
Great
question:
yes,
we
can
so
that
would
be
a
great
unit.
Reason
to
use
numba
if
you
wanted
to
but
apply
ROS
does
all
that
for
you,
it's
it's
truck.
It
automatically
is
gonna.
Try
to
optimize
that
under
the
hood
we
do
expose
it
with
apply
chunks
applied,
chunks
is
going
to
let
you
handle
specific
things.
You
can
do
things
like
what
are
the
threads
per
block?
A
You
can
what,
if
the
block
counts,
I
hope
you
can
see
this
stuff,
but-
and
it
was
a
little
hard
with
all
the
prints,
but
you
can
do
things
like
controlling
the
threads
and
the
blocks
and
all
that
kind
of
stuff
if
the
same
API
or
if
it's
with
applied
chunks-
and
we
have
a
set
about
this
right
here.
In
fact,
in
the
notebook.
A
A
Now
this
is
a
little
bit
more
advanced,
so
perhaps
it's
not
necessary
for
a
lot
of
people,
but
conceptually
I
always
want
to
show
that
you
can
do
it
and
I
encourage
you
to
take
the
time
to
go
through
it.
You
can
do
things
like
take
the
rolling
average
of
a
group.
You
know
we
can
write
our
function
and-
and
this
you
know,
might
look
a
little
bit
more
like
a
number
function.
A
For
example,
you
can
see
that
I'm
explicitly
going
through
the
thread
index,
the
total
size
of
the
group-
and
you
know
the
block
dimensions,
and
you
can
do
this
to
do
to
basically
just
do
a
group
by
based
user-defined
function.
Now,
in
this
case
it
was
a
rolling
function
and
it
was
because
I
was
going
to
take
the
window
size
of
three
that
we
got.
These
missing
values
that
makes
sense
a
window.
Size
is
three
by
default.
A
We're
gonna
have
only
results
for
when
there's
at
least
three
values,
and
so
I
encourage
you
to
spend
more
time
after
this
or
they
really
go
through
these
notebooks
to
really
see
what's
going
on
here,
the
group
by
functionality
is
a
little
bit
more
complicated,
as
you
can
see,
but
it's
incredibly
powerful
as
well.
Okay,.
B
A
A
A
A
Ups
with
complicated
with
complex
code
and
there's
an
example
of
using
a
user-defined
function
and
applying
it
onto
a
rolling
window
which
I
encourage
you
all
to
look
into
so
hopefully
this
has
been
a
useful
45
minutes
for
those
of
you
who
have
not
yet
had
a
chance
to
work
on
the
notebooks
to
get
a
sense
of
what
they
contain.
You
know
give
you
a
sneak
peak
of
you
know
what
you're
gonna
see
when
you
go
through
the
homeworks
for
those
of
you
who
have
gone
through
them.