►
From YouTube: 3. Introduction to RAPIDS
Description
From the NERSC NVIDIA RAPIDS Workshop on April 14, 2020. Please see https://www.nersc.gov/users/training/events/rapids-hackathon/ for all course materials.
A
Hi
everyone,
my
name,
is
Nick
Becker
I'm.
Also
a
member
of
the
Nvidia
Rapids
engineering
team
and
I've
been
working
or
we've
been
working
with
brawlin
with
Lori
with
rest
of
the
folks
at
nurse.
The
better
part
of
the
last
year,
as
our
element'
and
I'm
really
excited
to
sort
of
take
on
where
you
take
up
where
you
just
left
off
and
talk
about
Rapids
and
I'm
gonna
share
my
screen.
Please
do
yell
in
the
chat.
If
you
can't
see
this
we're
all
in
or
Lori
you
can
ping
me.
If
that
happens,.
A
A
But
it's
also
made
GPUs
hard
to
use
from
higher
level
languages
that
are
really
productive,
as
Ron
mentioned,
like
Python
and
in
other
areas
as
well.
But
it's
also
meant
that
there's
a
significant
effort
involved
in
writing
that
code,
for
the
same
reason
that
the
Python
data
analytics
ecosystem
is
is
really
powerful.
You
don't
want
to
write
Fortran
code,
perhaps
or
write
C
code,
to
do
your
matrix
operations
to
do
your.
A
So
for
those
of
you
who
are
familiar
with
Python
data
ecosystem
in
a
second
you'll,
see
a
slide
that
looks
a
lot
like
this
and
see
very
familiar.
But
so
Rapids
is
really
an
end-to-end
accelerated
data
science
ecosystem.
Instead
of
taking
that
five
percent
of
your
code,
that's
compute
intensive.
Let's
take
99%
of
your
code
because
it
turns
out
even
the
areas
that
aren't
quite
as
compute
intensive
can
still
be
exposed
to
significant
parallelism,
and
so,
if
we
move
data
preparation
onto
the
GPU,
we
can
move
model
training
onto
the
GPU.
A
We
can
move
visualization
onto
the
GPU
and
we
can
then
put
the
entire
feedback
loop
on
the
GPU
so
that
you
can
do
science
faster
and
test
more
hypotheses
and
iterate
more
quickly
and
Rapids
has
a
suite
of
libraries
to
allow
you
to
do
this.
For
data
frame
oriented
analytics.
We
have
libraries
that
we
call
ku
DF
the
CUDA
data
frame,
there's
io
libraries
for
doing
you,
know:
ingestion
file,
I/o,
there's
machine
learning,
libraries
graph,
analytics
libraries,
their
support
baked
into
the
deep
learning
libraries
there's
visualization.
A
All
of
these
libraries
sit
on
top
of
the
GPU
and
they
use
the
Apache
Aero
memory
specification
on
the
GPU
and
we
scale
them
to
multiple
GPUs
using
desk
and
student
with
SPARC
as
well,
and
so
the
reason
this
is
particularly
important
is
something
that
you
know.
Hopefully,
some
of
you
had
a
chance
to
see
in
the
notebooks,
but
if
you
haven't,
that's
okay,
we'll
go
over
them
and
we'll
see
in
an
even
more
clarity
later
this
afternoon,
while
we
accelerate
a
real
nurse
workflow.
A
But
the
reason
this
is
important
is
that
data
processing
has
evolved
several
times
in
the
last
decade
and
each
time
we've
gotten
better
and
faster,
and
it's
allowed
us
to
do
more
work
to
do
larger
work
and
to
ask
new
questions.
So
you
know
about
10
years
ago,
the
common
process
for
doing
large-scale
computing
was
MapReduce.
A
Many
of
you
probably
wrote
MapReduce
jobs
where
you
would
read
data
from
something
like
you
know,
an
HDFS
system
or
some
kind
of
distributed
file
system.
Do
your
work
then
that
word.
That
would
finish.
Then
you
write
out
to
the
file
system
and
then
you
do
your
next
phase,
but
that
would
read
more
data
back
in
and
then
write
it
out
read
more
data
back
in.
A
Perhaps
you
would
do
something
after
that,
and
you
know
this
was
great,
because
it
was
a
really
efficient
way
of
doing
it
compared
to
the
existing
alternative,
which
was
very
minimal,
but
Hadoop
had
its
drawbacks.
In
particular,
map
reduced
with
HDFS
has
drawbacks
and
SPARC
came
along
about.
You
know.
You
know
several
years
later
with
the
idea
saying
why
don't
we
try
to
keep
all
the
data
in
memory
at
once?
A
Let's
read
once
maintain
this
in
memory
data
structured
for
all
of
our
work
and
then
right
at
the
end,
when
we
need
to
finish
our
results,
and
that
was
a
big
deal
that
gave
us
a
significant
improvement.
You
know
25
200
X
faster,
less
code,
which
is
very
important
as
well
and
not
to
be
underrated,
but
it
was
also
a
language
flexible.
So
you
see
things
like
PI,
SPARC
and
obviously
SPARC
is
in
the
JVM
worlds.
A
There's
Scala,
SPARC
and
there's
you
know
incredible
productivity
that
we
can
gain
by
not
having
to
write
MapReduce
jobs-
and
you
know
traditional
GPU
processing-
gives
you
even
more
benefits
beyond
SPARC,
but
it's
a
little
bit
language
rigid.
No,
you
can't
traditionally
use
GPUs
in
languages
like
Python.
A
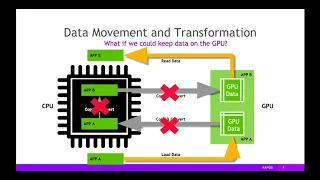
But
to
do
that,
you
might
need
to
copy
data
from
one
data
structure
to
another
on
the
CPU
before
sending
it
to
the
GPU,
which
is
another
copy,
then
you
could
read
the
data
on
the
GPU
to
your
application,
send
the
results
back
and
then
you
have
to
bring
it
back
to
the
CPU.
Perhaps,
and
these
data
movement
data
transformations
and
copies
negated,
some
of
the
benefit,
if
you
keep
the
data
entirely
on
the
GPU,
there's
no
need
to
do
any
of
these
things.
A
If
the
GPU
data
structures
are
consistent
in
memory,
if
there's
a
standard
format
that
everything
can
interoperate
with,
we
avoid
these
problems
in
the
first
place.
So
what
we've
done
is
that
we've
learned
from
the
Apache
arrow
project
for
those
who
are
less
aware
of
this
project
the
world
on
the
left
side
of
the
screen
is
the
worlds
in
which
people
use
different
tools
for
doing
different
types
of
work
and
the
tools
don't
communicate
with
one
another
and
in
in
order
to
combine
these
tools
in
a
workload
or
a
research
pipeline.
A
A
Apache
arrow
was
something
that
was
incubated
probably
about
three
or
four
years
ago
and
tried
to
say
why?
Don't
we
solve
this
problem
by
agreeing
on
a
memory
format,
let's
define
a
specification
for
cross
system
communication
and
allow
tools
to
share
this
format.
That
way
we
don't
have
to
have
any
of
that
serialization
and
deserialization
sign.
We
can
communicate
between
tools
in
the
same
way,
we've
learned
from
this
and
have
implemented
a
subset
of
the
Apache
arrow
memory
specification
on
the
GPU
for
Rapids.
What
that
means
is
we
can
now
go
one
step
further.
B
A
A
It
actually
got
even
more
faster
excuse
me,
even
even
faster,
sometimes
upwards,
of
40%
faster,
and
that's
because
of
the
improvements
we
are
making
every
day
to
this
ecosystem
and
to
these
libraries,
and
so
the
reason
this
is
particularly
valuable.
Is
that
when
doing
science
or
doing
data
analytics
iteration
is
critical
and
speed
of
compute
is
crucial,
but
ease
of
use
and
the
ability
to
test
hypotheses
can't
be
separating
from
that.
Some
of
you
may
be
familiar
with
something
called
Kaggle,
which
is
an
online
data
science
and
machine
learning
competition
website
without
fail.
A
So
I
mentioned
in
in
a
few
minutes,
you
were
gonna
see
a
slide
that
look
like
the
first
slide.
This
is
the
Python
data
ecosystem
as
you're
all
I
mentioned.
You
know
there
are
more
than
a
thousand
Python
users
Python
users,
that
nurse
the
Python
data
ecosystem
is
fantastic
for
their
libraries,
like
pandas,
for
analytics
scikit-learn,
for
machine
learning,
there's
graph,
analytics
visualizations
with
matplotlib
and
plot
skilled
with
tasks
or
spark.
It's
an
amazing
ecosystem,
and
it's
amazing
because
the
tools
interoperate
well
and
the
api's
are
familiar.
They're,
flexible
and
they're.
A
Easy
to
use
Rapids
fits
that
same
API.
It
is
designed
to
be
a
drop-in
replacement
for
your
existing
PI
data
workflows,
and
so
we
scale
that
with
desk,
which
my
our
colleagues
abou
will
talk
about
a
little
bit
later,
as
we
go
through
the
desk
workshop
in
the
desk
notebooks,
but
at
a
very
quick
level.
For
those
of
you
who
are
not
familiar
with
desk
desk
is
how
we
scale
Python
native
compute.
A
Pendant
but
coordinated
work
in
Python,
and
so
what
that
really
means,
in
you
know
in
layman's
terms,
is
lets.
You
scale
your
existing
Python
code
from
your
laptop
to
your
supercomputer.
It's
easy
to
install.
It
has
the
same
api's
as
the
existing
tools
like
pandas
numpy,
so
I
could
learn,
etc,
and
it's
built
by
the
same
people.
A
A
Our
colleagues
and
our
team
have
brought
this
into
the
desk
world
to
provide,
with
the
same
kind
of
benefits
that
you
could
get
with
MPI,
and
the
result
is
that
you
get
incredible
bandwidth
with
tasks
now
with
generic
TCP
bandwidth
for
a
sort
of
generic
random
data.
Merge
which
is
pretty
common,
might
be
peaking
at
about
800
megabytes
per
second
with
ucx
and
ask
we
can
get
sometimes
even
up
to
17
or
18
gigabytes
per
second
of
bandwidth
when
we're
using
rapids
and
that's
that's.
A
What
makes
these
workflows
fly
and
so
I'm
gonna
sort
of
take
the
next
15
to
20
minutes
to
go
into
two
of
the
libraries
that
are
probably
very
relevant
for
a
lot
of
your
workflows.
These
are
the
crew,
DF
and
qu
ml
libraries
for
providing
data
frame,
processing
and
statistical
modeling,
so
ku
DF
is
gpu-accelerated
data,
processing
and
feature
engineering.
A
Many
of
you
probably
have
lived
this,
but
in
general,
the
average
data
analytics
researcher
or
professional
ben's,
90%
plus
of
their
time
doing
data
processing
as
opposed
to
training
models
or
actually
analyzing
the
results
of
their
data.
Its
spent
doing
the
processing
and
a
lot
of
that
time
is
spent
waiting
with
the
GPU
powered
workflow.
The
time
spent
waiting
goes
away.
We
can
rapidly
iterate
and
we
can
still
text
there.
A
Our
same
hypothesis
test
the
same
hypotheses,
but
we
can
also
test
more
of
them
in
a
single
day,
and
so
this
technology
stack
is
multi-layered
at
the
bottom.
We
have
cuda.
This
is
all
built
on
nvidia
cuda
and
the
cuda
libraries
like
thrust
and
Jinna
Phi
and
cub,
which
many
some
of
you
perhaps
have
have
written
and
used
in
your
code.
On
top
of
that,
we've
built
a
library,
ku
DF
C++
that
we
call
our
ku
DF
library
that
provides
a
consistent
set
of
API
is
for
data
frame
processing
in
C++.
A
Now,
we've
wrapped
that
into
syphon
and
python
to
expose
these
CUDA
libraries
and
this
CUDA,
these
CUDA
C++
data
structures
natively
to
Python,
so
you
can
interact
with
it.
Just
like
you
would
with
pandas,
and
you
can
scale
it
just
like
you
would
with
tasks,
and
so
the
backbone
I
mentioned
is
that
CUDA
C++
library
that
we
call
Lib
qu
DF.
It's
essentially
a
combination
of
table
and
column
data
structures
and
algorithms
for
operating
on
them.
A
There
are
various
CUDA
kernels
for
doing
common
operations
like
sorting
doing
reductions,
element
wise
operations,
merging
data
grouping,
all
sorts
of
different
things,
and
we
have
optimized
GPU
implementations
for
different
data
types
and
data
structures,
things
like
strings,
there's
a
fully
featured
and
fully
GPU
accelerated
strings
library
for
your
text,
processing
or
any
kind
of
textual
data,
as
well
as
timestamps
and
numerix,
and
all
sorts
of
things.
And
you
know
the
primitives-
are
pretty
pretty
consistent
in
pretty
clean.
A
A
gather,
a
primitive
will
take
in
a
table
view
and
it
will
take
in
a
column
view
and
a
gather
map
gather
map
will
be
seized
me
to
gather
a
map
will
be
a
you
know,
a
view
of
a
view
of
a
column
and
it's
gonna
just
do
the
gather
as
if
you
were
writing
the
CUDA
kernel.
But
you
can
do
this
in
C++
now
in
Panda.
Excuse
me
in
Python,
you
don't
really
worry
about
C++
you
or
psyphon.
You
just
use
pandas.
A
The
COO
D
F
Python
library
has
the
same
API
as
the
pandas
Python
library.
It's
a
library
for
manipulating
GPU
data
frames.
You
can
do
all
sorts
of
things,
including
create
your
own
functions,
which
some
of
you
have
already
started.
The
notebooks
probably
I've
already
seen
but
we'll
go
through
after
this
it's
fully
featured
and
it
is
as
close
as
possible,
just
a
thin
layer
on
top
of
that
that
sort
of
CUDA
C++
layer
and
because
of
that
it
gets
a
pretty
significant
speed-up,
and
so
this
is
a
benchmark
of
doing
a
variety
of
operations.
A
Things
like
taking
group
bys
and
doing
aggregations
on
the
suit
on
sums
and
and
mins
and
counts
of
different
keys
in
different
groups
or
doing
merges.
You
can
see
that
for
ten
million
rows
or
for
a
hundred
million
rows.
You
know
we
can
get
significant
speed.
Ups
in
the
multi
hundred
times,
faster
sorts
and
merges,
and
group
bys,
then
using
pandas
with
the
same
API,
which
is
incredibly
powerful.
But
it's
not
the
whole
story.
It's
really
really
about
the
entire
ecosystem.
A
So
we
put
into
ku
DF
a
fully-featured
strings
library
for
doing
things
like
string,
splitting
regular
expression,
engines,
typecasting,
concatenation
and
even
more
high-level
things
like
doing
tokenization
and
all
sorts
of
things
like
that.
This
is
now
baked
into
the
KU
TF
library,
and
you
can
see
on
the
right.
You
know
examples
on
a
small
small
number
of
strings
significantly
faster
in
the
order
of
ten
to
fifty
to
a
hundred
times
faster
than
using
pandas.
A
And
in
order
to
make
this
work,
though,
you
have
to
get
data
onto
the
GPU,
and
so
we
have
GPU
accelerated
I/o
baked
in
for
things
like
common
data
formats
like
CSV,
Parque,
ork,
JSON,
Avro,
etc.
You
know
these
are
these
are
baked
in,
and
this
is
one
small
example
on
the
right,
but
you
know
ten
plus
times
faster
than
the
equivalent
CPU
based
and
the
key
is
that
we
can
put
GPU
acceleration
both
into
the
parsing
of
the
data
and
in
the
decompression.
A
A
It's
about
an
ecosystem
of
tools
and
enabling
this
GPU
ecosystem
of
interoperable
tools
that
can
communicate
together,
and
so,
if
you
remember
to
that
slide
from
about
five
to
ten
minutes
ago
with
that
arrow
world,
where
all
the
tools
can
talk
to
the
central
format,
that's
true
look
a
lot
like
this
slide
and
so
array
based
workflows
that
are
using
coop
I
can
use
this
MPI
based
workflows
that
you
don't
want
to
switch.
You
can
use
this
to
use
number
you
can
use
this
deep
learning.
Workflows
can
use.
A
This
tensorflow
actually
will
be
on
this
lit.
What
the
new
version
of
tensorflow
now
supports
this,
it's
just
the
slides,
a
little
out-of-date,
tensorflow
2.2,
and
so
this
interoperability
is
crucial
which
it
lets
us
do.
Things
like
take
desk
and
numpy
put
that
on
the
GPU
to
scale
array
workflows
to
multi
tens
and
hundreds
terabyte
size
problems
in
climate
science
in
large-scale
biomedical
imaging
and
other
HPC
problems.
A
You
can
take
this
world
and
put
it
on
the
GPU
and
that's
what
we're
doing
here
and
as
an
example
of
the
multi-dimensional
array,
slicing
workflow,
you
can
get
significant
speed,
ups
and
and
not
even
just
on
that,
you
know
terabyte
size
data.
This
is
on
eight
and
an
800
megabyte
size
to
raise.
You
know
these
element-wise,
slicing
or
FFTs
or
stencil
operations
or
matrix
multiplications.
A
These
can
be
ten
fifty
a
hundred
times
faster
on
the
GPU,
with
the
same
api's
and
as
one
example,
we
took
a
large
matrix,
decomposition
problem
and
scaled
it
across
machines,
and
you
can
see
that
in
this
graph
the
compute
time
is
going
from
600
seconds,
with
tasks
scaling
with
80
CPU
cores
down
to
30
seconds
with
tasks
you
arrays
with
ku
PI
and
multiple
GPUs,
and
so
we
actually
do
this
at
even
larger
scale.
We
did
this
a
petabyte
scale
to
see
how
we
could
do.
A
Less
than
an
hour
of
wall
time
to
do
significant,
matrix,
decomposition
and
processing
on
multi,
petabytes,
size,
workflows
and,
and
that's
the
power
here,
and
so
that
power
means
you
can
do
array
based
work,
and
you
can
also
do
machine
learning
based
work
things
like
clustering,
no,
linear,
regressions,
logistical
regressions,
all
sorts
of
things,
and
so
ku
ml
is
the
library
for
this
more
models,
more
problems.
You
can
test
more
hypotheses,
and
so
the
reason
this
is
really
important
is
that
you
know
data
sizes
are
growing.
A
So
the
same
reason
we
needed
to
accelerate
pre-processing
and
data
handling
is
why
we
have
to
Excel
accelerate
model,
training
and
model
prediction,
because
the
data
size
grows
the
time
you
have
to
spend
waiting
for
that
to
finish
increases
and
that
hurts
research.
So
what
you
end
up
doing
is
reducing
the
features
or
reducing
dimensionality
with
matrix,
decomposition
or
sampling,
and
you
know
that
can
be
great
statistically
for
some
problems,
but
you
know
maybe
you're
working
in
an
underpowered
environments
and
you
don't
have
the
Cystic
allow
to
sample
efficiently.
A
If
you
have
imbalance
problem
or
all
sorts
of
different
things
that
make
it
difficult
using
the
whole
universe
of
data
is
just
superior
and
so
ku
ml
allows
you
to
do
that
with
the
same
kind
of
technology
stack
that
puts
a
C++
library
on
top
of
CUDA
and
a
scythe
on
and
Python
library.
On
top
of
that,
that
looks
just
like
scikit-learn
and
scales,
just
like
Gascon
scikit-learn,
it
uses
screw
PI,
which
is
the
equivalent
of
numpy,
uses
the
CUDA
data
frame,
and
it
gives
you
all
sorts
of
things.
A
You
know
different
types
of
clustering,
visualizations
like
you
map
and
TCE
spectral,
embedding
principal
components,
all
sorts
of
you
know
eigen,
vector,
decomposition
and
stuff
like
that.
You
can
do
on
the
GPU
and
it
can
be
significantly
faster
but,
most
importantly,
it
matches
the
existing
api's
and
that's
a
theme
with
rapid.
You
know
that's
why
we're
so
excited
about
this
partnership
with
nurse
and
the
fact
that
25%
of
users
are
using
Python.
A
This
is
just
going
to
just
work
for
those
those
users,
and
hopefully
you
can.
You
know
give
this
a
try
on
your
research
workloads,
but
as
an
example,
you
know,
if
you
wanted
to
do
clustering
with
psych,
you
learn.
This
is
much,
which
is
what
you
might
do.
You
can
use
DB
scan,
which
is
you
know,
density
based,
clustering
algorithm.
You
could
create
some
data
and
you
could
fit
the
model
and
call
predict,
and
you
could
do
your
clustering
and
you'd
get
these
nice
little
clusters
in
this
case.
There's
two
of
them
well
with
rapid.
A
It's
the
same
thing.
You
just
change
your
imports
and
it
just
works
except
faster
and
that's
the
power
here,
and
so
in
this
case
you
know
we
have
some
benchmarks
that
I
encourage
you
to
go.
Look
at
if
you're
interested
I'm,
not
gonna,
go
through
them
all
here,
but
in
general,
for
a
lot
of
these
you
know
machine
learning,
workflows
and
matrix
T
compositions,
and
things
like
that.
You
know
we
can
get
significant
for
large
data.
A
You
know
between
five
ten
fifty
a
hundred
times
faster
for
a
lot
of
different
operations,
and
you
know
for
those
of
you
who
are
using
things
like
random
forests.
Next
reboost
those
are
supported
in
rapids
as
well
as
well
as
accelerated
prediction,
not
just
training,
because
prediction
is
important
to
again:
I'm,
not
gonna
belabor,
the
benchmarks,
I
think
the
points
been
made,
Rapids
is
fast,
and
so
it's
fast
with
actually
boosts
passive,
random
forests.
It's
fast
across
the
board-
and
you
know
right
now
we're
at
version
0.13.
A
This
is
from
March
of
this
year
and
we
have
a
lot
of
support,
which
is
great
Rapids
1.0,
perhaps
later
this
year,
we'll
have
full
multi
node
multi-gpu
support
for
most
algorithms,
the
ones
that
won't
have
that
are
largely
ones
that
are
more
commonly
done
with
smaller
data.
Things
like
you
know,
auto
regressive,
modeling
like
a
Rhema
and
others,
and
that's
you
know,
that's
really
exciting,
but
today,
even
today
that
we
have
an
incredible
amount
of
support
for
large-scale
problems
and
I'm
not
gonna
focus
on
it,
but
there
is
another
library
for
doing
graph
analytics.
A
A
I'm
not
gonna,
go
through
all
the
algorithms
here,
you
can
look
them
up
online,
but
there's
a
support
for
a
lot
of
different
types
of
things,
including
jacquard,
set
similarity,
overlaps,
okay,
trust
triangle,
counting
PageRank,
the
vein,
all
sorts
of
community
detection,
algorithms
and
things
like
that,
and
it's
fast.
This
is
an
example
of
the
high
bench
benchmark
suite
performance
of
PageRank.
A
This
is
a
benchmark
suite
for
doing
graph
problems
on
graphs
of
various
sizes
across
different
algorithms,
and
the
PageRank
portion
is
one
of
the
most
economically
important
ones
and
they
have
different
designations
around
each
data
size
between
huge
and
big
data
and
big
data
x
8.
You
can
see
that
for
graphs
with
400
million
vertices
and
sixteen
billion
edges,
that's
a
three
hundred
gigabyte
size,
CSV
file
on
a
single
DG
x2
with
16
GPUs
that
took
30
seconds
with
Apache
spark
and
a
hundred
nodes
that
took
96
minutes.
A
That's
the
power
of
Rapids
and
Reno
records
is
a
community
project.
It
is
full
of
ecosystem
partners
with
support
from
open
source.
You
know
maintainer
z',
across
different
libraries
support
from
people
at
various
companies
support
from
people
at
various
research
institutions.
It's
open
source,
it's
community
driven
and
anyone
can
get
involved
and
people
are
building
on
top
of
it.
For
those
who
may
be
right,
sequel
code,
there
is
a
sequel
engine
built
on
top
of
Rapids
for
streaming
work.
A
There's
a
streaming
engine
built
on
top
of
Rapids,
and
you
know
that's
that's
the
power
this
is
about
enabling
GPU
based
analytics.
It's
easy
to
install.
Those
of
you
have
tried
the
notebooks
I've
seen
that
in
this
case,
there's
already
been
a
kernel
set
up
for
you.
You
can
just
use
the
rapid
kernel,
but
if
you
were
to
try
this
yourself
in
the
future,
its
installable
via
Conda,
you
can
download
a
docker
container.
A
If
you
were
so
inclined,
you
can
use
all
of
this
in
a
nice,
easy
interactive
installation
guide
on
the
rapids
site,
which
is
linked
or
will
be
linked
in
the
documentation
for
this
workshop,
and
you
know
if
you're
interested
in
exploring
this,
you
can
contribute
back.
You
know
we
support
the
coop
I
project,
which
is
run
by
chain.
Nvidia
supports
that
both
you
know
with
development
time
and
with
resources
and
with
work.
You
know
it's
part
of
the
ecosystem,
it's
a
core
part
of
this
world,
and
you
know
it's
incredibly
important
to
us.
A
So
we
encourage
you
to
contribute
to
file
issues.
Make
future
requests
improve
the
ecosystem
so
that
we
can
best
serve
you.
The
scientists
and
nurse
researchers
who
are
doing
the
work
that
we
desperately
you
know,
need
right
now.
Is
it
as
a
country
in
as
a
world
and
so
to
get
started.
You
know
in
this
workshop
you
can
use
the
GPGPU
notebooks
that
have
been
provided
and
use
that
rapid
kernel.
A
But
if
you
want
to
learn
more
check
out
the
docs,
you
know
there's
a
ten-minute
guide
to
getting
started,
there's
a
whole
set
of
docs
that
you
know
we
can
go
through
and
there
are
links
to
them
and
then
in
the
workshop
notebooks
and
check
it
us
out
on
github.
You
can
get
us
in
the
cloud
on
docker
hub.
If
you
want
a
docker
container,
you
can
install
it
from
anaconda.
A
You
can
get
it
from
github
and
build
from
source
any
way
works,
and
so
with
that
I
hope,
you've
gotten
a
sense
of
what
Rapids
is
it's
this
ecosystem
of
libraries
to
meet
you
in
the
Python
world,
where
we
can
be
most
productive.
I
have
spent
the
last
five
years.
Writing
Python
and
Scala
code,
primarily
both
in
the
spark
world
and
in
the
Python
world,
and
bringing
GPUs
into
this
world
is
a
game
changer
and
it
takes
work
that
might
take
hours
on
the
CPU
into
seconds.
A
Sometimes,
and
we'll
actually
see
an
example
of
that
later
today,
with
a
real
workload
that
went
from
out
that
can
go
from
hours
to
seconds
and
so
I
hope
you've
enjoyed
this
brief.
You
know
30
to
40
minute
overview
of
rapid
and
with
that
Before
we
jump
into
you.
The
first
notebook
I'd
love
to
just
take.
It
takes
that.
Take
a
couple
minutes
to
hear
from
a
few
questions.
If
there
are
any,
does
anyone
feel
like
they
would
like
more
clarity
on
some
of
the
things
we
just
chatted
about.
A
C
C
A
Question
so
the
answer
is
that
we
spread
it
out.
So
GPU
is
generally
at
least
I
believe
the
the
core
GPUs
have
16
gigabytes
of
memory
per
GPU,
the
dgx
okay
great.
So
the
dgx
twos
have
GPUs
with
32
gigabytes
of
memory.
So,
for
example,
I
don't
know
if
you
can
see
my
mouse,
but
in
this
you
know,
example
at
the
top
and
the
left
side,
this
purple
bar
that
says
dgx.
That
machine
has
16
GPUs
each
with
32
gigabytes
of
memory.
A
So
there's
across
the
GPU
is
about
just
under
500
gigabytes
of
memory
total
these
GPUs
down
here
in
the
dgx
ones,
5
dgx
ones
is
40
GPUs
and
you
can
do
the
same
math
problem
for
whether
it's
16
or
32
gigabytes
per
GPU
and
there's
enough
memory
in
order
to
sort
of
have
all
of
it
in
memory
at
once.
Now
with
that
said,
allows
you
to
spill,
and
you
can
spill
both
to
CPU
memory
or
main
memory
from
the
GPU
or
to
disk.
If
that's
something,
that's
important,
that's
even
more
important!
A
A
So
yeah
it's
a
good
question,
so
this
is
not
using
you
VM,
you
can
use
you
VM
and
then,
of
course,
you
know
that
you
have
that
shared
address
space,
but,
let's
just
for
now
imagine
we're
not
using
you
VM
and
we
have
perhaps
500
gigabytes
of
memory
spread
across
16
GPUs.
This
data
set
will
be
loaded
in
to
memory
in
a
distributed
fashion.
Gpu
0
might
get
some
of
the
data.
Gpu
12
might
get
some
other
part
of
the
data.
A
The
operations
that
happen
after
that
are
going
to
leverage
data
locality
when
possible,
and
if
they
don't
have
the
data
they
need
they're
going
to
have
to
request
that
data
from
one
of
the
other
GPUs.
You
know
that's
going
to
be
a
transfer
and
in
some
operation
I'm
gonna
have
they
might
have
to
do
a
shuffle
if
they
have
to
shuffle
fully
the
way
that's
orchestrated
is
with
the
parallelism
framework.
In
this
case
we
used
ask
some
of
you
might
be
familiar
with
it.
A
C
A
C
A
Question
so
right
now
we
do
currently
officially
only
support
Ubuntu
and
CentOS.
We
don't
support
Mac
or
Windows,
if
not
something
that
is
likely
in
the
short-term
roadmap,
but
I'd
love
to
hear
more
about
that
and
learn
about.
You
know
why
that's
important
to
you
and
we
can
discuss
that.
We
would
like
to
support
everything.
Okay,.
A
So
I
am
NOT
well
sure
I
am
not
well-versed
in
in
summit.
Just
personally
I
suspect
the
answer
is
probably
but
I
think
we'd
have
to
chat
afterward.
Perhaps
there's
someone
one
of
my
colleagues
or
someone
at
Nurse
Corps
at
lb.
Excuse
me
all
right,
like
Oak,
Ridge
or
somewhere
else
that
has
done
this.
I
can.
B
Add
to
that
Nick
this
is
Zara,
so
we
we
are
working
with
approach
to
I,
think
the
latest
version
of
Rapids
that
they
had
was
point
11
and
one
of
their
modules.
I
think
this
IBM
Watson
module,
but
that's
the
power
system,
so
we've
been
working
on
updating
it
to
the
latest
release
as
last
week.
I
think
they
should
have
access
to
that
so
they're
going
to
update
that
2.13
soon.