13 Sep 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Pegasus Workflow Management System
Speaker:
Karan Vahi, Information Sciences Institute, University of Southern California
Abstract:
Workflows are a key technology for enabling complex scientific computations. They capture the interdependencies between processing steps in data analysis and simulation pipelines as well as the mechanisms to execute those steps reliably and efficiently. Workflows can capture complex processes to promote sharing and reuse, and also provide provenance information necessary for the verification of scientific results and scientific reproducibility. Pegasus (https://pegasus.isi.edu) is being used in a number of scientific domains doing production grade science. In 2016 the LIGO gravitational wave experiment used Pegasus to analyze instrumental data and confirm the first detection of a gravitational wave. The Southern California Earthquake Center (SCEC) based at USC, uses a Pegasus managed workflow infrastructure called Cybershake to generate hazard maps for the Southern California region. In 2021, SCEC conducted a CyberShake study on DOE systems Summit that used a simulation-based ERF for the first time. Overall, the study required 65,470 node-hours (358,000 GPU-hours and 243,000 CPU-hours ) of computation with Pegasus submitting tens of thousands of remote jobs automatically, and managed 165 TB of data over the 29-day study. Pegasus is also being used in astronomy, bioinformatics, civil engineering, climate modeling, earthquake science, molecular dynamics and other complex analyses. Pegasus users express their workflows using an abstract representation devoid of resource- specific information. Pegasus plans these abstract workflows by mapping tasks to available resources, augmenting the workflow with data management tasks, and optimizing the workflow by grouping small tasks into more efficient clustered batch jobs. Pegasus then executes this plan. If an error occurs at runtime, Pegasus automatically retries the failed task and provides checkpointing in case the workflow cannot continue. Pegasus can record provenance about the data, software and hardware used. Pegasus has a foundation for managing workflows in different environments, using workflow engines that are customized for a particular workload and system. Pegasus has a well defined support for major container technologies such as Docker, Singulartiy, Shifter that allows users to have the jobs in their workflow use containers of their choice. Pegasus most recent major release Pegasus 5.0 is a major improvement over previous releases. Pegasus 5.0 provides a brand new Python3 workflow API developed from the ground up so that, in addition to generating the abstract workflow and all the catalogs, it now allows you to plan, submit, monitor, analyze and generate statistics of your workflow.
Bio:
Karan Vahi is a Senior Computer Scientist in the Science Automation Technologies group at the USC Information Sciences Institute. He has been working in the field of scientific workflows since 2002, and has been closely involved in the development of the Pegasus Workflow Management System. He is currently the architect/lead developer for Pegasus and in charge of the core development of Pegasus. His work on implementing integrity checking in Pegasus for scientific workflows won the best paper and the Phil Andrews Most Transformative Research Award at PEARC19. He currently leads the Cloud Platforms group at CI Compass, a NSF CI Center, which includes CI practitioners from various NFS Major facilities(MF’s) and aims to understand the current practices for Cloud Infrastructure used by MFs and research alternative solutions. https://www.isi.edu/directory/vahi/
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Pegasus Workflow Management System
Speaker:
Karan Vahi, Information Sciences Institute, University of Southern California
Abstract:
Workflows are a key technology for enabling complex scientific computations. They capture the interdependencies between processing steps in data analysis and simulation pipelines as well as the mechanisms to execute those steps reliably and efficiently. Workflows can capture complex processes to promote sharing and reuse, and also provide provenance information necessary for the verification of scientific results and scientific reproducibility. Pegasus (https://pegasus.isi.edu) is being used in a number of scientific domains doing production grade science. In 2016 the LIGO gravitational wave experiment used Pegasus to analyze instrumental data and confirm the first detection of a gravitational wave. The Southern California Earthquake Center (SCEC) based at USC, uses a Pegasus managed workflow infrastructure called Cybershake to generate hazard maps for the Southern California region. In 2021, SCEC conducted a CyberShake study on DOE systems Summit that used a simulation-based ERF for the first time. Overall, the study required 65,470 node-hours (358,000 GPU-hours and 243,000 CPU-hours ) of computation with Pegasus submitting tens of thousands of remote jobs automatically, and managed 165 TB of data over the 29-day study. Pegasus is also being used in astronomy, bioinformatics, civil engineering, climate modeling, earthquake science, molecular dynamics and other complex analyses. Pegasus users express their workflows using an abstract representation devoid of resource- specific information. Pegasus plans these abstract workflows by mapping tasks to available resources, augmenting the workflow with data management tasks, and optimizing the workflow by grouping small tasks into more efficient clustered batch jobs. Pegasus then executes this plan. If an error occurs at runtime, Pegasus automatically retries the failed task and provides checkpointing in case the workflow cannot continue. Pegasus can record provenance about the data, software and hardware used. Pegasus has a foundation for managing workflows in different environments, using workflow engines that are customized for a particular workload and system. Pegasus has a well defined support for major container technologies such as Docker, Singulartiy, Shifter that allows users to have the jobs in their workflow use containers of their choice. Pegasus most recent major release Pegasus 5.0 is a major improvement over previous releases. Pegasus 5.0 provides a brand new Python3 workflow API developed from the ground up so that, in addition to generating the abstract workflow and all the catalogs, it now allows you to plan, submit, monitor, analyze and generate statistics of your workflow.
Bio:
Karan Vahi is a Senior Computer Scientist in the Science Automation Technologies group at the USC Information Sciences Institute. He has been working in the field of scientific workflows since 2002, and has been closely involved in the development of the Pegasus Workflow Management System. He is currently the architect/lead developer for Pegasus and in charge of the core development of Pegasus. His work on implementing integrity checking in Pegasus for scientific workflows won the best paper and the Phil Andrews Most Transformative Research Award at PEARC19. He currently leads the Cloud Platforms group at CI Compass, a NSF CI Center, which includes CI practitioners from various NFS Major facilities(MF’s) and aims to understand the current practices for Cloud Infrastructure used by MFs and research alternative solutions. https://www.isi.edu/directory/vahi/
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 6 participants
- 58 minutes

9 Aug 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Transparent Checkpointing: a mature technology enabling MANA for MPI and beyond
Speaker:
Gene Cooperman, Khoury College of Computer Sciences, Northeastern University
Abstract:
Although transparent checking grew up in the 1990s and 2000s as a technology for HPC, it has now grown as a tool that is useful for many newer domains. Today, this is no longer your grandfather's checkpointing software! In this talk, I will review some of the newer checkpointing technologies invented only in the last decade, and how they gate new capabilities that can be adapted in a variety of domains.
This talk includes a tour of the 15-year old DMTCP project, with special emphasis on the latest achievement: MANA for MPI -- a robust package for transparent checkpointing of MPI. But as a prerequisite, one must have an understanding of two advances that brought DMTCP to its present state: (i) a general framework for extensible checkpointing plugins; and (ii) split processes (isolate the software application to be checkpointed from the underlying hardware).
In the remainder of the talk, these two principles are first showcased in MANA. This is then followed by a selection of other domains where transparent checkpointing shows interesting potential. This includes: deep learning (especially for general frameworks), edge computing, lambda functions (serverless computing), spot instances, containers for parallel and distributed computing (Apptainer and Singularity), process migration (migrate the process to the data in joint work with JPL), deep debugging for parallel and distributed computations, a model for checkpointing in Hadoop, and more.
Bio:
Professor Cooperman currently works in high-performance computing. He received his B.S. from the University of Michigan in 1974, and his Ph.D. from Brown University in 1978. He came to Northeastern University in 1986, and has been a full professor there since 1992. His visiting research positions include a 5-year IDEX Chair of Attractivity at the University of Toulouse/CNRS in France, and sabbaticals at Concordia University, at CERN, and in Inria/France. In 2014, he and his student, Xin Dong, used a novel idea to semi-automatically add multi-threading support to the million-line Geant4 code coordinated out of CERN. He is one of the more than 100 co-authors on the foundational Geant4 paper, whose current citation count is 34,000. Prof. Cooperman currently leads the DMTCP project (Distributed Multi-Threaded CheckPointing) for transparent checkpointing. The project began in 2004, and has benefited from a series of PhD theses. Over 150 refereed publications cite DMTCP as having contributed to their research project.
Host of Seminar:
Zhengji Zhao, User Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Transparent Checkpointing: a mature technology enabling MANA for MPI and beyond
Speaker:
Gene Cooperman, Khoury College of Computer Sciences, Northeastern University
Abstract:
Although transparent checking grew up in the 1990s and 2000s as a technology for HPC, it has now grown as a tool that is useful for many newer domains. Today, this is no longer your grandfather's checkpointing software! In this talk, I will review some of the newer checkpointing technologies invented only in the last decade, and how they gate new capabilities that can be adapted in a variety of domains.
This talk includes a tour of the 15-year old DMTCP project, with special emphasis on the latest achievement: MANA for MPI -- a robust package for transparent checkpointing of MPI. But as a prerequisite, one must have an understanding of two advances that brought DMTCP to its present state: (i) a general framework for extensible checkpointing plugins; and (ii) split processes (isolate the software application to be checkpointed from the underlying hardware).
In the remainder of the talk, these two principles are first showcased in MANA. This is then followed by a selection of other domains where transparent checkpointing shows interesting potential. This includes: deep learning (especially for general frameworks), edge computing, lambda functions (serverless computing), spot instances, containers for parallel and distributed computing (Apptainer and Singularity), process migration (migrate the process to the data in joint work with JPL), deep debugging for parallel and distributed computations, a model for checkpointing in Hadoop, and more.
Bio:
Professor Cooperman currently works in high-performance computing. He received his B.S. from the University of Michigan in 1974, and his Ph.D. from Brown University in 1978. He came to Northeastern University in 1986, and has been a full professor there since 1992. His visiting research positions include a 5-year IDEX Chair of Attractivity at the University of Toulouse/CNRS in France, and sabbaticals at Concordia University, at CERN, and in Inria/France. In 2014, he and his student, Xin Dong, used a novel idea to semi-automatically add multi-threading support to the million-line Geant4 code coordinated out of CERN. He is one of the more than 100 co-authors on the foundational Geant4 paper, whose current citation count is 34,000. Prof. Cooperman currently leads the DMTCP project (Distributed Multi-Threaded CheckPointing) for transparent checkpointing. The project began in 2004, and has benefited from a series of PhD theses. Over 150 refereed publications cite DMTCP as having contributed to their research project.
Host of Seminar:
Zhengji Zhao, User Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 3 participants
- 58 minutes

28 Jun 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
FourCastNet: Data-driven, high-resolution atmosphere modeling at scale
Speaker:
Shashank Subramanian, Data & Analytics Services Group, National Energy Research Scientific Computing Center (NERSC), Lawrence Berkeley National Laboratory
Abstract:
We present FourCastNet, short for Fourier Forecasting Neural Network, a global data-driven weather forecasting model that provides accurate short to medium-range global predictions at 25km resolution. FourCastNet accurately forecasts high-resolution, fast-timescale variables such as the surface wind speed, total precipitation, and atmospheric water vapor with important implications for wind energy resource planning, predicting extreme weather events such as tropical cyclones and atmospheric rivers, as well as extreme precipitation. We compare the forecast skill of FourCastNet with archived operational IFS model forecasts and find that the forecast skill of our purely data-driven model is remarkably close to that of the IFS model for short to medium-range forecasts. FourCastNet generates a week-long forecast in less than 2 seconds, orders of magnitude faster than IFS, enabling the creation of inexpensive large-ensemble forecasts for improved probabilistic forecasting. Finally, our implementation is optimized and we present efficient scaling results on different supercomputing systems up to 3808 NVIDIA A100 GPUs, resulting in 80000 times faster time-to-solution relative to IFS, in inference.
Bio:
Shashank Subramanian is a NESAP for learning postdoctoral fellow with research interests in the intersection of high-performance scientific computing, deep learning, and physical sciences.
Host of Seminar:
Peter Harrington, Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
FourCastNet: Data-driven, high-resolution atmosphere modeling at scale
Speaker:
Shashank Subramanian, Data & Analytics Services Group, National Energy Research Scientific Computing Center (NERSC), Lawrence Berkeley National Laboratory
Abstract:
We present FourCastNet, short for Fourier Forecasting Neural Network, a global data-driven weather forecasting model that provides accurate short to medium-range global predictions at 25km resolution. FourCastNet accurately forecasts high-resolution, fast-timescale variables such as the surface wind speed, total precipitation, and atmospheric water vapor with important implications for wind energy resource planning, predicting extreme weather events such as tropical cyclones and atmospheric rivers, as well as extreme precipitation. We compare the forecast skill of FourCastNet with archived operational IFS model forecasts and find that the forecast skill of our purely data-driven model is remarkably close to that of the IFS model for short to medium-range forecasts. FourCastNet generates a week-long forecast in less than 2 seconds, orders of magnitude faster than IFS, enabling the creation of inexpensive large-ensemble forecasts for improved probabilistic forecasting. Finally, our implementation is optimized and we present efficient scaling results on different supercomputing systems up to 3808 NVIDIA A100 GPUs, resulting in 80000 times faster time-to-solution relative to IFS, in inference.
Bio:
Shashank Subramanian is a NESAP for learning postdoctoral fellow with research interests in the intersection of high-performance scientific computing, deep learning, and physical sciences.
Host of Seminar:
Peter Harrington, Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 3 participants
- 59 minutes

23 Jun 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Demo and hands-on session on ReFrame
Speaker:
Lisa Gerhardt, Alberto Chiusole - NERSC, Berkeley Lab
Abstract:
Overview and brief demo of the capabilities of ReFrame, and how we use it at NERSC to run pipelines on different systems and continuously test the user-facing requirements.
Title:
Demo and hands-on session on ReFrame
Speaker:
Lisa Gerhardt, Alberto Chiusole - NERSC, Berkeley Lab
Abstract:
Overview and brief demo of the capabilities of ReFrame, and how we use it at NERSC to run pipelines on different systems and continuously test the user-facing requirements.
- 5 participants
- 41 minutes

14 Jun 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Artificial Design of Porous Materials
Speaker:
Jihan Kim, Department of Chemical and Biomolecular Engineering, KAIST
Abstract:
In this presentation, I will explore the new trend of designing novel porous materials using artificial design principles. I will talk about using our in-house developed generative adversarial network (GAN) software to create (for the first time) porous materials. Moreover, we have successfully implemented inverse-design in our GAN prompting ways to train our AI to create porous materials with user-desired methane adsorption capacity [1]. Next, we incorporate machine learning with genetic algorithm to design optimal metal-organic frameworks suitable for many different applications including methane storage and gas separations [2-3]. Finally, we demonstrate usage of text mining to collect wealth of data from published papers to predict optimal synthesis conditions for porous materials [4]. Overall, machine learning and artificial design can accelerate the materials discovery and expedite the process to deploy new materials for many different applications.
Bio:
Jihan Kim is an associate professor at KAIST (Korea Advanced Institute of Science and Technology). He received his B.S. degree in Electrical Engineering and Computer Science (EECS) at UC Berkeley in 1997 and received his M.S. and Ph.D. degrees in Electrical and Computer Engineering at University of Illinois at Urbana-Champaign in 2004 and 2009, respectively. He worked as a NERSC postdoc in the Petascale Post-doc project from 2009 to 2011 and worked as postdoctoral researcher in UC Berkeley/LBNL with Prof. Berend Smit from 2011 to 2013. His current research at KAIST focuses on using molecular simulations and machine learning methods to design novel porous materials (e.g. zeolites, MOFs, porous polymers) for various energy and environmental related applications (e.g. gas storage, gas separations, catalysis, sensors). He has published over 100 papers and has over 7000 Google Scholar citations.
Host of Seminar:
Brian Austin, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Artificial Design of Porous Materials
Speaker:
Jihan Kim, Department of Chemical and Biomolecular Engineering, KAIST
Abstract:
In this presentation, I will explore the new trend of designing novel porous materials using artificial design principles. I will talk about using our in-house developed generative adversarial network (GAN) software to create (for the first time) porous materials. Moreover, we have successfully implemented inverse-design in our GAN prompting ways to train our AI to create porous materials with user-desired methane adsorption capacity [1]. Next, we incorporate machine learning with genetic algorithm to design optimal metal-organic frameworks suitable for many different applications including methane storage and gas separations [2-3]. Finally, we demonstrate usage of text mining to collect wealth of data from published papers to predict optimal synthesis conditions for porous materials [4]. Overall, machine learning and artificial design can accelerate the materials discovery and expedite the process to deploy new materials for many different applications.
Bio:
Jihan Kim is an associate professor at KAIST (Korea Advanced Institute of Science and Technology). He received his B.S. degree in Electrical Engineering and Computer Science (EECS) at UC Berkeley in 1997 and received his M.S. and Ph.D. degrees in Electrical and Computer Engineering at University of Illinois at Urbana-Champaign in 2004 and 2009, respectively. He worked as a NERSC postdoc in the Petascale Post-doc project from 2009 to 2011 and worked as postdoctoral researcher in UC Berkeley/LBNL with Prof. Berend Smit from 2011 to 2013. His current research at KAIST focuses on using molecular simulations and machine learning methods to design novel porous materials (e.g. zeolites, MOFs, porous polymers) for various energy and environmental related applications (e.g. gas storage, gas separations, catalysis, sensors). He has published over 100 papers and has over 7000 Google Scholar citations.
Host of Seminar:
Brian Austin, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 49 minutes

7 Jun 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Building a Platform for Operating Multi-Institutional Distributed Services
Speaker:
Lincoln Bryant, Research Engineer at the University of Chicago's Enrico Fermi Institute
Abstract:
Much of science today is propelled by research collaborations that require highly interconnected instrumentation, computational, and storage resources that cross institutional boundaries. To provide a generalized service infrastructure for multi-institutional science, we propose a new abstraction and implementation of this model: Federated Operations (FedOps) and SLATE. We will show the general principles behind the FedOps trust model and how the SLATE platform implements FedOps for building a service fabric over independently operated Kubernetes clusters. Finally, we will show how SLATE is being used to manage data and software caching networks in production across computing sites in the US ATLAS computing facility in support the ATLAS experiment at the CERN Large Hadron Collider.
Bio:
Lincoln Bryant is a Research Engineer in the Enrico Fermi Institute at the University of Chicago. He has over a decade of experience building and supporting High-Throughput Computing (HTC), distributed storage, and containerization/virtualization systems for both the ATLAS experiment at the Large Hadron Collider and other collaborations as part of the Open Science Grid Consortium. Lincoln is one of the primary contributors to the Services Layer At The Edge (SLATE) project and has been an active Kubernetes user since 2017.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Building a Platform for Operating Multi-Institutional Distributed Services
Speaker:
Lincoln Bryant, Research Engineer at the University of Chicago's Enrico Fermi Institute
Abstract:
Much of science today is propelled by research collaborations that require highly interconnected instrumentation, computational, and storage resources that cross institutional boundaries. To provide a generalized service infrastructure for multi-institutional science, we propose a new abstraction and implementation of this model: Federated Operations (FedOps) and SLATE. We will show the general principles behind the FedOps trust model and how the SLATE platform implements FedOps for building a service fabric over independently operated Kubernetes clusters. Finally, we will show how SLATE is being used to manage data and software caching networks in production across computing sites in the US ATLAS computing facility in support the ATLAS experiment at the CERN Large Hadron Collider.
Bio:
Lincoln Bryant is a Research Engineer in the Enrico Fermi Institute at the University of Chicago. He has over a decade of experience building and supporting High-Throughput Computing (HTC), distributed storage, and containerization/virtualization systems for both the ATLAS experiment at the Large Hadron Collider and other collaborations as part of the Open Science Grid Consortium. Lincoln is one of the primary contributors to the Services Layer At The Edge (SLATE) project and has been an active Kubernetes user since 2017.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 6 participants
- 53 minutes

17 May 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Memory Disaggregation: Potentials and Pitfalls
Speaker:
Nan Ding, Performance and Algorithms Group, Computer Science Department, Lawrence Berkeley National Laboratory
Abstract:
Memory usage imbalance has been consistently observed in many data centers. This has sparked interest in memory disaggregation, which allows applications to use all available memory across an entire data center instead of being confined to the memory of a single server. In the talk, I'll present the design space and implementation for building a disaggregated memory system. I'll then discuss the critical metrics for applications to benefit from memory disaggregation.
Bio:
Nan Ding is a Research Scientist in the Performance and Algorithms group of the Computer Science Department at Lawrence Berkeley National Laboratory. Her research interests include high-performance computing, performance modeling, and auto-tuning. Nan received her Ph.D. in computer science from Tsinghua University, Beijing, China in 2018.
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Memory Disaggregation: Potentials and Pitfalls
Speaker:
Nan Ding, Performance and Algorithms Group, Computer Science Department, Lawrence Berkeley National Laboratory
Abstract:
Memory usage imbalance has been consistently observed in many data centers. This has sparked interest in memory disaggregation, which allows applications to use all available memory across an entire data center instead of being confined to the memory of a single server. In the talk, I'll present the design space and implementation for building a disaggregated memory system. I'll then discuss the critical metrics for applications to benefit from memory disaggregation.
Bio:
Nan Ding is a Research Scientist in the Performance and Algorithms group of the Computer Science Department at Lawrence Berkeley National Laboratory. Her research interests include high-performance computing, performance modeling, and auto-tuning. Nan received her Ph.D. in computer science from Tsinghua University, Beijing, China in 2018.
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 39 minutes

26 Apr 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
FirecREST, RESTful HPC
Speaker:
Juan Pablo Dorsch, HPC Software Engineer & Lead for the Innovative Resource Access Methods, CSCS Swiss National Supercomputing Center
Abstract:
FirecREST is a RESTful API to HPC that empowers scientific communities to access compute and data HPC services and infrastructure through a web interface. This API supports and enhances the development of scientific portals that allow web developers and HPC users to adapt their workflows in a more flexible, secure, automated, and standardized way. In this talk, we will present FirecREST and provide an introduction to its capabilities.
Bio:
Juan Pablo Dorsch is a software engineer and lead for the Innovative Resource Access Methods at the CSCS Swiss National Supercomputing Centre. His areas of expertise include microservice architecture design, IAM, web development and RESTful services. Before joining CSCS, Juan held the position of HPC engineer with the Computational Methods Research Centre (CIMEC), and the position of scientific software developer with the International Centre for Numerical Methods in Engineering (CIMNE). He was also previously a degree professor at the National University (UNL) of Littoral in Santa Fe, Argentina. He holds a degree in Informatics Engineering with an emphasis on scientific applications from UNL.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
FirecREST, RESTful HPC
Speaker:
Juan Pablo Dorsch, HPC Software Engineer & Lead for the Innovative Resource Access Methods, CSCS Swiss National Supercomputing Center
Abstract:
FirecREST is a RESTful API to HPC that empowers scientific communities to access compute and data HPC services and infrastructure through a web interface. This API supports and enhances the development of scientific portals that allow web developers and HPC users to adapt their workflows in a more flexible, secure, automated, and standardized way. In this talk, we will present FirecREST and provide an introduction to its capabilities.
Bio:
Juan Pablo Dorsch is a software engineer and lead for the Innovative Resource Access Methods at the CSCS Swiss National Supercomputing Centre. His areas of expertise include microservice architecture design, IAM, web development and RESTful services. Before joining CSCS, Juan held the position of HPC engineer with the Computational Methods Research Centre (CIMEC), and the position of scientific software developer with the International Centre for Numerical Methods in Engineering (CIMNE). He was also previously a degree professor at the National University (UNL) of Littoral in Santa Fe, Argentina. He holds a degree in Informatics Engineering with an emphasis on scientific applications from UNL.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 48 minutes

19 Apr 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Discovering and Modeling Strong Gravitational Lenses with Cori and Perlmutter at NERSC
Speakers:
Xiaosheng Huang, USF
Andi Gu, UCB
Abstract:
We have discovered over 1500 new strong lens candidates in the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys with residual neural networks using NERSC resources. Follow-up observations are underway. Our Hubble Space Telescope program has confirmed all 51 observed candides. DESI observations have confirmed more systems spectroscopically. Preliminary results from our latest search will increase the number of lens candidates to over 3000. We have also developed GIGA-Lens: a gradient-informed, GPU-accelerated Bayesian framework, implemented in TensorFlow and JAX. All components of this framework (optimization, variational inference, HMC) take advantage of gradient information through autodiff and parallelization on GPUs. Running on one Perlmutter A100 GPU node, we achieve 1-2 orders of magnitude speedup compared to existing codes. The robustness, speed, and scalability offered by this framework make it possible to model the large number of strong lenses found in DESI, and O(10^5) lenses expected to be discovered in upcoming large-scale surveys, such as the LSST.
Bios:
Xiaosheng Huang received his PhD from UC Berkeley and has been a faculty member in the Physics & Astronomy Department at the University of San Francisco since 2012. He works on problems in observational cosmology with collaborators in the Supernova Cosmology Project, the Nearby Supernova Factory, and the Dark Energy Spectroscopic Instrument experiment, and of course, with students.
Andi Gu is a current senior at UC Berkeley. He has been working in the Supernova Cosmology Project and DESI since 2019, applying his computer science and physics background to gravitational lens detection and modeling.
Host of Seminar:
Steven Farrell
Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Discovering and Modeling Strong Gravitational Lenses with Cori and Perlmutter at NERSC
Speakers:
Xiaosheng Huang, USF
Andi Gu, UCB
Abstract:
We have discovered over 1500 new strong lens candidates in the Dark Energy Spectroscopic Instrument (DESI) Legacy Imaging Surveys with residual neural networks using NERSC resources. Follow-up observations are underway. Our Hubble Space Telescope program has confirmed all 51 observed candides. DESI observations have confirmed more systems spectroscopically. Preliminary results from our latest search will increase the number of lens candidates to over 3000. We have also developed GIGA-Lens: a gradient-informed, GPU-accelerated Bayesian framework, implemented in TensorFlow and JAX. All components of this framework (optimization, variational inference, HMC) take advantage of gradient information through autodiff and parallelization on GPUs. Running on one Perlmutter A100 GPU node, we achieve 1-2 orders of magnitude speedup compared to existing codes. The robustness, speed, and scalability offered by this framework make it possible to model the large number of strong lenses found in DESI, and O(10^5) lenses expected to be discovered in upcoming large-scale surveys, such as the LSST.
Bios:
Xiaosheng Huang received his PhD from UC Berkeley and has been a faculty member in the Physics & Astronomy Department at the University of San Francisco since 2012. He works on problems in observational cosmology with collaborators in the Supernova Cosmology Project, the Nearby Supernova Factory, and the Dark Energy Spectroscopic Instrument experiment, and of course, with students.
Andi Gu is a current senior at UC Berkeley. He has been working in the Supernova Cosmology Project and DESI since 2019, applying his computer science and physics background to gravitational lens detection and modeling.
Host of Seminar:
Steven Farrell
Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 4 participants
- 53 minutes

22 Mar 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Composable Platforms for Scientific Computing: Experiences and Outcomes
Speakers:
Erik Gough, Brian Werts, Sam Weekly - Rosen Center for Advanced Computing, Purdue University
Abstract:
The Geddes Composable Platform is an on-premise Kubernetes-based private cloud hosted at Purdue University that’s designed to meet the increased demand for scientific data analysis and to promote "SciOps" — the application of DevOps principles in scientific computing. The platform has supported research groups and data science initiatives at Purdue, enabling as many as sixty users from a variety of scientific domains. In this seminar, we will give a technical overview of the platform and its components, summarize the usage patterns, and describe the scientific use cases the platform enables. Some examples of services deployed through Geddes include JupyterHubs, science gateways, databases, ML-based image classifiers, and web-based BLAST database searches. The same technology behind Geddes is found in Purdue’s new XSEDE resource named Anvil, which provides composable computing capabilities to the broader national research community.
Bios:
Erik Gough is a lead computational scientist in the Research Computing department at Purdue University. He has been building, maintaining and using large scale cyberinfrastructure for scientific computing at Purdue since 2007. Gough is a technical leader on multiple NSF funded projects, including an NSF CC* award to build the Geddes Composable Platform.
Brian Werts is the lead engineer for the design and implementation of Purdue’s Geddes Composable Platform and a HIPAA aligned Hadoop cluster for researchers that leverages Kubernetes to help facilitate reproducibility and scalability of data science workflows.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Composable Platforms for Scientific Computing: Experiences and Outcomes
Speakers:
Erik Gough, Brian Werts, Sam Weekly - Rosen Center for Advanced Computing, Purdue University
Abstract:
The Geddes Composable Platform is an on-premise Kubernetes-based private cloud hosted at Purdue University that’s designed to meet the increased demand for scientific data analysis and to promote "SciOps" — the application of DevOps principles in scientific computing. The platform has supported research groups and data science initiatives at Purdue, enabling as many as sixty users from a variety of scientific domains. In this seminar, we will give a technical overview of the platform and its components, summarize the usage patterns, and describe the scientific use cases the platform enables. Some examples of services deployed through Geddes include JupyterHubs, science gateways, databases, ML-based image classifiers, and web-based BLAST database searches. The same technology behind Geddes is found in Purdue’s new XSEDE resource named Anvil, which provides composable computing capabilities to the broader national research community.
Bios:
Erik Gough is a lead computational scientist in the Research Computing department at Purdue University. He has been building, maintaining and using large scale cyberinfrastructure for scientific computing at Purdue since 2007. Gough is a technical leader on multiple NSF funded projects, including an NSF CC* award to build the Geddes Composable Platform.
Brian Werts is the lead engineer for the design and implementation of Purdue’s Geddes Composable Platform and a HIPAA aligned Hadoop cluster for researchers that leverages Kubernetes to help facilitate reproducibility and scalability of data science workflows.
Host of Seminar:
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 4 participants
- 45 minutes

15 Mar 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Chameleon: An Innovation Platform for Computer Science Research and Education
Speakers:
Kate Keahey, Senior Scientist, CASE Affiliate
Abstract:
We live in interesting times: new ideas and technological opportunities emerge at ever increasing rate in disaggregated hardware, programmable networks, and the edge computing and IoT space to name just a few. These innovations require an instrument where they can be deployed and investigated, and where new solutions that those disruptive ideas require can be developed, tested, and shared. To support a breadth of Computer Science experiments such instrument has to provide access to a diversity of hardware configurations, support deployment at scale, as well as deep reconfigrability so that a wide range of experiments can be supported. It also has to provide mechanisms for easy and direct sharing of repeatable digital artifacts so that new experiments and results can be easily replicated and help enable further innovation. Most importantly -- since science does not stand still – such instrument requires the capability for constant adaptation to support an ever increasing range of experiments driven by emergent ideas and opportunities. The NSF-funded Chameleon testbed (www.chameleoncloud.org) has been developed to provide all those capabilities. It provides access to a variety of hardware including cutting-edge architectures, a range of accelerators, storage hierarchies with a mix of large RAM, NVDIMMs, a variety of enterprise and consumer grade SDDs, HDDs, high-bandwidth I/0 storage, SDN-enabled networking hardware, and fast interconnects. This diversity was enlarged recently to add support for edge computing/IoT devices and will be further extended this year to include LiQid composable hardware as well as P4 switches. Chameleon is distributed over two core sites at the University of Chicago and the Texas Advanced Computing Center (TACC) connected by 100 Gbps network – as well as three volunteer sites at NCAR, Northwestern University, and the University of Illinois in Chicago (UIC). Bare metal reconfigurability for Computer Science experiments is provided by CHameleon Infrastructure (CHI), based on an enhanced bare-metal flavor of OpenStack: it allows users to reconfigure resources at bare metal level, boot from custom kernel, and have root privileges on the machines. To date, the testbed has supported 6,000+ users and 800+ projects in research, education, and emergent applications. In this talk, I will describe the goals, the design strategy, and the capabilities of the testbed, as well as some of the research and education projects our users are working on. I will also discuss our new thrusts in support for research on edge computing and IoT, our investment in developing and packaging of research infrastructure (CHI-in-a-Box), as well as our support for composable systems that can both dynamically integrate resources from other sources into Chameleon and make Chameleon resources available via other systems. Lastly, I will describe the services and tools we created to support sharing of experiments, educational curricula, and other digitally expressed artifacts that allow science to be shared via active involvement and foster reproducibility.
Bio:
Kate Keahey is one of the pioneers of infrastructure cloud computing. She created the Nimbus project, recognized as the first open source Infrastructure-as-a-Service implementation, and continues to work on research aligning cloud computing concepts with the needs of scientific datacenters and applications. To facilitate such research for the community at large, Kate leads the Chameleon project, providing a deeply reconfigurable, large-scale, and open experimental platform for Computer Science research. To foster the recognition of contributions to science made by software projects, Kate co-founded and serves as co-Editor-in-Chief of the SoftwareX journal, a new format designed to publish software contributions. Kate is a Scientist at Argonne National Laboratory and a Senior Scientist The University of Chicago Consortium for Advanced Science and Engineering (UChicago CASE).
Hosts of Seminar:
Shane Canon, Data & Analytics Group
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Chameleon: An Innovation Platform for Computer Science Research and Education
Speakers:
Kate Keahey, Senior Scientist, CASE Affiliate
Abstract:
We live in interesting times: new ideas and technological opportunities emerge at ever increasing rate in disaggregated hardware, programmable networks, and the edge computing and IoT space to name just a few. These innovations require an instrument where they can be deployed and investigated, and where new solutions that those disruptive ideas require can be developed, tested, and shared. To support a breadth of Computer Science experiments such instrument has to provide access to a diversity of hardware configurations, support deployment at scale, as well as deep reconfigrability so that a wide range of experiments can be supported. It also has to provide mechanisms for easy and direct sharing of repeatable digital artifacts so that new experiments and results can be easily replicated and help enable further innovation. Most importantly -- since science does not stand still – such instrument requires the capability for constant adaptation to support an ever increasing range of experiments driven by emergent ideas and opportunities. The NSF-funded Chameleon testbed (www.chameleoncloud.org) has been developed to provide all those capabilities. It provides access to a variety of hardware including cutting-edge architectures, a range of accelerators, storage hierarchies with a mix of large RAM, NVDIMMs, a variety of enterprise and consumer grade SDDs, HDDs, high-bandwidth I/0 storage, SDN-enabled networking hardware, and fast interconnects. This diversity was enlarged recently to add support for edge computing/IoT devices and will be further extended this year to include LiQid composable hardware as well as P4 switches. Chameleon is distributed over two core sites at the University of Chicago and the Texas Advanced Computing Center (TACC) connected by 100 Gbps network – as well as three volunteer sites at NCAR, Northwestern University, and the University of Illinois in Chicago (UIC). Bare metal reconfigurability for Computer Science experiments is provided by CHameleon Infrastructure (CHI), based on an enhanced bare-metal flavor of OpenStack: it allows users to reconfigure resources at bare metal level, boot from custom kernel, and have root privileges on the machines. To date, the testbed has supported 6,000+ users and 800+ projects in research, education, and emergent applications. In this talk, I will describe the goals, the design strategy, and the capabilities of the testbed, as well as some of the research and education projects our users are working on. I will also discuss our new thrusts in support for research on edge computing and IoT, our investment in developing and packaging of research infrastructure (CHI-in-a-Box), as well as our support for composable systems that can both dynamically integrate resources from other sources into Chameleon and make Chameleon resources available via other systems. Lastly, I will describe the services and tools we created to support sharing of experiments, educational curricula, and other digitally expressed artifacts that allow science to be shared via active involvement and foster reproducibility.
Bio:
Kate Keahey is one of the pioneers of infrastructure cloud computing. She created the Nimbus project, recognized as the first open source Infrastructure-as-a-Service implementation, and continues to work on research aligning cloud computing concepts with the needs of scientific datacenters and applications. To facilitate such research for the community at large, Kate leads the Chameleon project, providing a deeply reconfigurable, large-scale, and open experimental platform for Computer Science research. To foster the recognition of contributions to science made by software projects, Kate co-founded and serves as co-Editor-in-Chief of the SoftwareX journal, a new format designed to publish software contributions. Kate is a Scientist at Argonne National Laboratory and a Senior Scientist The University of Chicago Consortium for Advanced Science and Engineering (UChicago CASE).
Hosts of Seminar:
Shane Canon, Data & Analytics Group
Jonathan Skone, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 57 minutes

1 Feb 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
KubeFlux: a scheduler plugin bridging the cloud-HPC gap in Kubernetes
Speakers:
Claudia Misale, Research Staff Member in Hybrid Cloud Infrastructure Software Dept, IBM Research
Daniel J. Milroy, Computer Scientist, Center for Applied Scientific Computing, Lawrence Livermore National Laboratory
Abstract:
The cloud is an increasingly important market sector of computing and is driving innovation. Adoption of cloud technologies by high performance computing (HPC) is accelerating, and HPC users want their applications to perform well everywhere. While cloud orchestration frameworks like Kubernetes provide advantages like resiliency, elasticity, and automation, they are not designed to enable application performance to the same degree as HPC workload managers and schedulers. As HPC and cloud Computing converge, techniques from HPC can be integrated into the cloud to improve application performance and provide universal scalability. We present KubeFlux, a Kubernetes plugin based on the Fluxion open-source HPC scheduler component of the Flux framework developed at the Lawrence Livermore National Laboratory. We introduce the Flux framework and the Fluxion scheduler and describe how their hierarchical, graph-based foundation is naturally suited to converged computing. We discuss uses for KubeFlux and compare the performance of an application scheduled by the Kubernetes default scheduler and KubeFlux. KubeFlux is an example of the rich capability that can be added to Kubernetes and paves the way to democratization of the cloud for HPC workloads.
Bio(s):
Claudia Misale is a Research Staff Member in the Hybrid Cloud Infrastructure Software group at IBM T.J. Watson Research Center (NY). Her research is focused on Kubernetes for IBM Public Cloud, and also targets porting HPC applications to the cloud by enabling batch scheduling alternatives for Kubernetes. She is mainly interested in cloud computing and container technologies, and her background is on high-level parallel programming models and patterns, and big data analytics on HPC platforms. She received her master’s summa cum laude and bachelor’s degree in Computer Science at the University of Calabria (Italy), and her PhD from the Computer Science Department of the University of Torino (Italy).
Daniel Milroy is a Computer Scientist at the Center for Applied Scientific Computing at the Lawrence Livermore National Laboratory. His research focuses on graph-based scheduling and resource representation and management for high performance computing (HPC) and cloud converged environments. While Dan’s research background is numerical analysis and software quality assurance and correctness for climate simulations, he is currently interested in scheduling and representing dynamic resources, and co-scheduling and management techniques for HPC and cloud. Dan holds a B.A. in physics from the University of Chicago, and an M.S. and PhD in computer science from the University of Colorado Boulder.
Host of Seminar:
Shane Canon
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
KubeFlux: a scheduler plugin bridging the cloud-HPC gap in Kubernetes
Speakers:
Claudia Misale, Research Staff Member in Hybrid Cloud Infrastructure Software Dept, IBM Research
Daniel J. Milroy, Computer Scientist, Center for Applied Scientific Computing, Lawrence Livermore National Laboratory
Abstract:
The cloud is an increasingly important market sector of computing and is driving innovation. Adoption of cloud technologies by high performance computing (HPC) is accelerating, and HPC users want their applications to perform well everywhere. While cloud orchestration frameworks like Kubernetes provide advantages like resiliency, elasticity, and automation, they are not designed to enable application performance to the same degree as HPC workload managers and schedulers. As HPC and cloud Computing converge, techniques from HPC can be integrated into the cloud to improve application performance and provide universal scalability. We present KubeFlux, a Kubernetes plugin based on the Fluxion open-source HPC scheduler component of the Flux framework developed at the Lawrence Livermore National Laboratory. We introduce the Flux framework and the Fluxion scheduler and describe how their hierarchical, graph-based foundation is naturally suited to converged computing. We discuss uses for KubeFlux and compare the performance of an application scheduled by the Kubernetes default scheduler and KubeFlux. KubeFlux is an example of the rich capability that can be added to Kubernetes and paves the way to democratization of the cloud for HPC workloads.
Bio(s):
Claudia Misale is a Research Staff Member in the Hybrid Cloud Infrastructure Software group at IBM T.J. Watson Research Center (NY). Her research is focused on Kubernetes for IBM Public Cloud, and also targets porting HPC applications to the cloud by enabling batch scheduling alternatives for Kubernetes. She is mainly interested in cloud computing and container technologies, and her background is on high-level parallel programming models and patterns, and big data analytics on HPC platforms. She received her master’s summa cum laude and bachelor’s degree in Computer Science at the University of Calabria (Italy), and her PhD from the Computer Science Department of the University of Torino (Italy).
Daniel Milroy is a Computer Scientist at the Center for Applied Scientific Computing at the Lawrence Livermore National Laboratory. His research focuses on graph-based scheduling and resource representation and management for high performance computing (HPC) and cloud converged environments. While Dan’s research background is numerical analysis and software quality assurance and correctness for climate simulations, he is currently interested in scheduling and representing dynamic resources, and co-scheduling and management techniques for HPC and cloud. Dan holds a B.A. in physics from the University of Chicago, and an M.S. and PhD in computer science from the University of Colorado Boulder.
Host of Seminar:
Shane Canon
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 3 participants
- 47 minutes

13 Jan 2022
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
The Next Generation of High Performance Computing: HPC-2.0
Speaker:
Gregory Kurtzer, CEO of Ctrl IQ, Inc. and Executive Director of Rocky Enterprise Software Foundation / Rocky Linux
Abstract:
We’ve been using the same base architecture for building HPC systems for almost 30 years and while the capabilities of our systems have increased considerably, we still use the same flat and monolithic architecture of the 1990’s to build our systems. What would the next generation architecture look like? How do we leverage containers to do computing of complex workflows while orchestrating not only jobs, but data? How do we bridge HPC into the 2020’s and make optimal use of multi-clusters and federate these systems into a larger resource to unite on-prem, multi-prem, cloud, and multi-cloud? How do we integrate with these resources in a cloud-native compatible manner supporting CI/CD, DevOps, DevSecOps, compute portals, GUIs, and even mobile? This isn’t a bunch of shoelace and duct-tape on top of legacy HPC, this is an entirely new way to think about HPC infrastructure. This is a glimpse into HPC-2.0, coming later in Q1 of 2022.
Bio:
Gregory M. Kurtzer is a 20+ year veteran in Linux, open source, and high performance computing. He is well known in the HPC space for designing scalable and easy to manage secure architectures for innovative performance intensive computing while working for the U.S. Department of Energy and joint appointment to UC Berkeley. Greg founded and led several large open source projects such as CentOS Linux, the Warewulf and Perceus cluster toolkits, the container system Singularity, and most recently, the successor to CentOS, Rocky Linux. Greg’s first startup was acquired almost 2 years ago and now he is working on software infrastructure, including Rocky Linux as well as building a cloud native, cloud hybrid, federated orchestration platform called Fuzzball.
Hosts of Seminar:
Jonathan Skone, Advanced Technologies Group
Glenn Lockwood, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
The Next Generation of High Performance Computing: HPC-2.0
Speaker:
Gregory Kurtzer, CEO of Ctrl IQ, Inc. and Executive Director of Rocky Enterprise Software Foundation / Rocky Linux
Abstract:
We’ve been using the same base architecture for building HPC systems for almost 30 years and while the capabilities of our systems have increased considerably, we still use the same flat and monolithic architecture of the 1990’s to build our systems. What would the next generation architecture look like? How do we leverage containers to do computing of complex workflows while orchestrating not only jobs, but data? How do we bridge HPC into the 2020’s and make optimal use of multi-clusters and federate these systems into a larger resource to unite on-prem, multi-prem, cloud, and multi-cloud? How do we integrate with these resources in a cloud-native compatible manner supporting CI/CD, DevOps, DevSecOps, compute portals, GUIs, and even mobile? This isn’t a bunch of shoelace and duct-tape on top of legacy HPC, this is an entirely new way to think about HPC infrastructure. This is a glimpse into HPC-2.0, coming later in Q1 of 2022.
Bio:
Gregory M. Kurtzer is a 20+ year veteran in Linux, open source, and high performance computing. He is well known in the HPC space for designing scalable and easy to manage secure architectures for innovative performance intensive computing while working for the U.S. Department of Energy and joint appointment to UC Berkeley. Greg founded and led several large open source projects such as CentOS Linux, the Warewulf and Perceus cluster toolkits, the container system Singularity, and most recently, the successor to CentOS, Rocky Linux. Greg’s first startup was acquired almost 2 years ago and now he is working on software infrastructure, including Rocky Linux as well as building a cloud native, cloud hybrid, federated orchestration platform called Fuzzball.
Hosts of Seminar:
Jonathan Skone, Advanced Technologies Group
Glenn Lockwood, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 38 minutes

14 Dec 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Characterizing Machine Learning I/O Workloads on Leadership Scale HPC Systems
Speaker:
Ahmad Maroof Karimi
A.I. Methods at Scale Group
National Center for Computational Sciences (NCCS) Division
Oak Ridge National Laboratory
Abstract:
High performance computing (HPC) is no longer solely limited to traditional workloads such as simulation and modeling. With the increase in the popularity of machine learn- ing (ML) and deep learning (DL) technologies, we are observing that an increasing number of HPC users
are incorporating ML methods into their workflow and scientific discovery processes, across a wide spectrum of science domains such as biology, earth science, and physics. This gives rise to a diverse set of I/O patterns than the traditional checkpoint/restart-based HPC I/O behavior. The details of the I/O characteristics of such ML I/O workloads have not been studied extensively for large-scale leadership HPC systems. This paper aims to fill that gap by providing an in-depth analysis to gain an understanding of the I/O behavior of ML I/O workloads using darshan - an I/O characterization tool designed for lightweight tracing and profiling. We study the darshan logs of more than 23,000 HPC ML I/O jobs over a time period of one year running on Summit - the second-fastest supercomputer in the world. This paper provides a systematic I/O characterization of ML I/O jobs running on a leadership scale supercomputer to understand how the I/O behavior differs across science domains and the scale of workloads, and analyze the usage of parallel file system and burst buffer by ML I/O workloads.
Bio:
Ahmad Maroof Karimi works as an HPC Operational Data Scientist in Analytics and A.I. Methods at Scale (AAIMS) Group in National Center for Computational Sciences (NCCS) Division, Oak Ridge National Laboratory. His current research focuses on the characterization of HPC I/O patterns and finding evolving HPC workload trends. He is also working on analyzing HPC facility data to characterize the HPC power consumption and building machine learning based job-aware power prediction models. Before joining ORNL, Ahmad completed his Ph.D. in Computer Science at CWRU, Cleveland, Ohio, in October 2020. His Ph.D. dissertation titled “Data science and machine learning to predict degradation and power of photovoltaic systems: convolutional and spatiotemporal graph neural networks” focused on classifying degradation mechanism and performance prediction of a photovoltaic power plant. He received his M.S. degree from the University of Toledo, Ohio, and B.S. degree from Aligarh Muslim University, India. Ahmad has also worked in the I.T. industry as a software programmer and database designer.
Hosts of Seminar:
Hai Ah Nam, Advanced Technologies Group
Wahid Bhimji, Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Characterizing Machine Learning I/O Workloads on Leadership Scale HPC Systems
Speaker:
Ahmad Maroof Karimi
A.I. Methods at Scale Group
National Center for Computational Sciences (NCCS) Division
Oak Ridge National Laboratory
Abstract:
High performance computing (HPC) is no longer solely limited to traditional workloads such as simulation and modeling. With the increase in the popularity of machine learn- ing (ML) and deep learning (DL) technologies, we are observing that an increasing number of HPC users
are incorporating ML methods into their workflow and scientific discovery processes, across a wide spectrum of science domains such as biology, earth science, and physics. This gives rise to a diverse set of I/O patterns than the traditional checkpoint/restart-based HPC I/O behavior. The details of the I/O characteristics of such ML I/O workloads have not been studied extensively for large-scale leadership HPC systems. This paper aims to fill that gap by providing an in-depth analysis to gain an understanding of the I/O behavior of ML I/O workloads using darshan - an I/O characterization tool designed for lightweight tracing and profiling. We study the darshan logs of more than 23,000 HPC ML I/O jobs over a time period of one year running on Summit - the second-fastest supercomputer in the world. This paper provides a systematic I/O characterization of ML I/O jobs running on a leadership scale supercomputer to understand how the I/O behavior differs across science domains and the scale of workloads, and analyze the usage of parallel file system and burst buffer by ML I/O workloads.
Bio:
Ahmad Maroof Karimi works as an HPC Operational Data Scientist in Analytics and A.I. Methods at Scale (AAIMS) Group in National Center for Computational Sciences (NCCS) Division, Oak Ridge National Laboratory. His current research focuses on the characterization of HPC I/O patterns and finding evolving HPC workload trends. He is also working on analyzing HPC facility data to characterize the HPC power consumption and building machine learning based job-aware power prediction models. Before joining ORNL, Ahmad completed his Ph.D. in Computer Science at CWRU, Cleveland, Ohio, in October 2020. His Ph.D. dissertation titled “Data science and machine learning to predict degradation and power of photovoltaic systems: convolutional and spatiotemporal graph neural networks” focused on classifying degradation mechanism and performance prediction of a photovoltaic power plant. He received his M.S. degree from the University of Toledo, Ohio, and B.S. degree from Aligarh Muslim University, India. Ahmad has also worked in the I.T. industry as a software programmer and database designer.
Hosts of Seminar:
Hai Ah Nam, Advanced Technologies Group
Wahid Bhimji, Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 3 participants
- 42 minutes

7 Dec 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Ceph Storage at CERN
Speaker(s):
Dan van der Ster, Pablo Llopis Sanmillan
CERN
Abstract:
Ceph and its Reliable Autonomic Distributed Object Store (RADOS) offers a scale out storage solution for block storage (RBD), object storage (S3 and SWIFT) and filesystems (CephFS). The key technologies enabling Ceph include CRUSH, a mechanism for defining and implementing failure domains, and the mature Object Storage Daemons (OSDs), which provide a reliable storage backend via replication or erasure coding. CERN has employed Ceph for its on-prem cloud infrastructures since 2013. As of 2021, its storage group operates more than ten clusters totaling over 50 petabytes for cloud, Kubernetes, and HPC use-cases. This talk will introduce Ceph and its key concepts, and describe how CERN uses Ceph in practice. It will include recent highlights related to high-throughput particle physics data taking and SLURM storage optimization.
Bio(s):
Dan manages the Ceph storage at CERN in Geneva, Switzerland. He has participated actively in its community since 2013 and was one of the first to demonstrate its scalability up to multi-10s of petabytes. Dan is a regular speaker at Open Infrastructure events, previously acted as Academic Liaison to the original Ceph Advisory Board, and has a similar role in the current Ceph Board. Dan earned a PhD in Distributed Systems at the University of Victoria, Canada in 2008.
Pablo is a computer engineer at CERN, where he manages the IT department’s HPC service. He provides HPC support to both engineers of the Accelerator Technology Sector and to theoretical physicists. Pablo works on improving the performance of their HPC workloads, and on other projects such as the automation of operational tasks of the infrastructure. He holds a Ph.D. in computer science from University Carlos III of Madrid. In the past he has also collaborated with Argonne National Laboratory and IBM Research Zurich on HPC and cloud-related topics. His main areas of interest include high performance computing, storage systems, power efficiency, and distributed systems.Zoom:
Host of Seminar:
Alberto Chiusole
Storage and I/O Software Engineer, Data and Analytics Services
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Ceph Storage at CERN
Speaker(s):
Dan van der Ster, Pablo Llopis Sanmillan
CERN
Abstract:
Ceph and its Reliable Autonomic Distributed Object Store (RADOS) offers a scale out storage solution for block storage (RBD), object storage (S3 and SWIFT) and filesystems (CephFS). The key technologies enabling Ceph include CRUSH, a mechanism for defining and implementing failure domains, and the mature Object Storage Daemons (OSDs), which provide a reliable storage backend via replication or erasure coding. CERN has employed Ceph for its on-prem cloud infrastructures since 2013. As of 2021, its storage group operates more than ten clusters totaling over 50 petabytes for cloud, Kubernetes, and HPC use-cases. This talk will introduce Ceph and its key concepts, and describe how CERN uses Ceph in practice. It will include recent highlights related to high-throughput particle physics data taking and SLURM storage optimization.
Bio(s):
Dan manages the Ceph storage at CERN in Geneva, Switzerland. He has participated actively in its community since 2013 and was one of the first to demonstrate its scalability up to multi-10s of petabytes. Dan is a regular speaker at Open Infrastructure events, previously acted as Academic Liaison to the original Ceph Advisory Board, and has a similar role in the current Ceph Board. Dan earned a PhD in Distributed Systems at the University of Victoria, Canada in 2008.
Pablo is a computer engineer at CERN, where he manages the IT department’s HPC service. He provides HPC support to both engineers of the Accelerator Technology Sector and to theoretical physicists. Pablo works on improving the performance of their HPC workloads, and on other projects such as the automation of operational tasks of the infrastructure. He holds a Ph.D. in computer science from University Carlos III of Madrid. In the past he has also collaborated with Argonne National Laboratory and IBM Research Zurich on HPC and cloud-related topics. His main areas of interest include high performance computing, storage systems, power efficiency, and distributed systems.Zoom:
Host of Seminar:
Alberto Chiusole
Storage and I/O Software Engineer, Data and Analytics Services
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 7 participants
- 1:06 hours

6 Dec 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
funcX: Federated FaaS for Scientific Computing
Speaker:
Ryan Chard
Data Science and Learning Division
Argonne National Laboratory
Abstract:
Exploding data volumes and velocities, new computational methods and platforms, and ubiquitous connectivity demand new approaches to computation in the sciences. These new approaches must enable computation to be mobile, so that, for example, it can occur near data, be triggered by events (e.g., arrival of new data), be offloaded to specialized accelerators, or run remotely where resources are available. They also require new design approaches in which monolithic applications can be decomposed into smaller components, that may in turn be executed separately and on the most suitable resources. To address these needs we present funcX—a distributed function as a service (FaaS) platform that enables flexible, scalable, and high-performance remote function execution. funcX's endpoint software can transform existing clusters and supercomputers into function serving systems, while funcX's cloud-hosted service provides transparent, secure, and reliable function execution across a federated ecosystem of endpoints. We demonstrate the use of funcX with several scientific case studies and show how it integrates into the wider Globus ecosystem to enable secure, fire-and-forget scientific computation.
Bio:
Ryan Chard joined Argonne in 2016 as a Maria Goeppert Mayer Fellow and then as an Assistant Computer Scientist in the Data Science and Learning Division. He now works with Argonne, UChicago, and Globus to develop cyberinfrastructure to enable scientific research. In particular, he works on the Globus Flows platform to create reliable data analysis pipelines and the funcX service to enable function serving for HPC. He has a Ph.D. in computer science and an M.Sc. from Victoria University of Wellington, New Zealand.
Host of Seminar:
Jonathan Skone, Advanced Technologies
Bjoern Enders, Data Science Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
funcX: Federated FaaS for Scientific Computing
Speaker:
Ryan Chard
Data Science and Learning Division
Argonne National Laboratory
Abstract:
Exploding data volumes and velocities, new computational methods and platforms, and ubiquitous connectivity demand new approaches to computation in the sciences. These new approaches must enable computation to be mobile, so that, for example, it can occur near data, be triggered by events (e.g., arrival of new data), be offloaded to specialized accelerators, or run remotely where resources are available. They also require new design approaches in which monolithic applications can be decomposed into smaller components, that may in turn be executed separately and on the most suitable resources. To address these needs we present funcX—a distributed function as a service (FaaS) platform that enables flexible, scalable, and high-performance remote function execution. funcX's endpoint software can transform existing clusters and supercomputers into function serving systems, while funcX's cloud-hosted service provides transparent, secure, and reliable function execution across a federated ecosystem of endpoints. We demonstrate the use of funcX with several scientific case studies and show how it integrates into the wider Globus ecosystem to enable secure, fire-and-forget scientific computation.
Bio:
Ryan Chard joined Argonne in 2016 as a Maria Goeppert Mayer Fellow and then as an Assistant Computer Scientist in the Data Science and Learning Division. He now works with Argonne, UChicago, and Globus to develop cyberinfrastructure to enable scientific research. In particular, he works on the Globus Flows platform to create reliable data analysis pipelines and the funcX service to enable function serving for HPC. He has a Ph.D. in computer science and an M.Sc. from Victoria University of Wellington, New Zealand.
Host of Seminar:
Jonathan Skone, Advanced Technologies
Bjoern Enders, Data Science Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 8 participants
- 1:07 hours

30 Nov 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Tiled: A Service for Structured Data Access
Speaker:
Dan Allan, NSLS-II - Brookhaven National Laboratory
Abstract:
In the Data Science and Systems Integration Program at NSLS-II, we have explored various ways to separate I/O code from user science code. After seven years of developing in-house solutions and contributing to external ones (including Intake), we propose an abstraction that we think is a broadly useful building block, named Tiled. Tiled is a data access service for data-aware portals and data science tools. It has a Python client that feels much like h5py to use and integrates naturally with dask, but nothing about the service is Python-specific; it also works from curl. Tiled’s service sits atop databases, filesystems, and/or remote services to enable search and structured, chunk-wise access to data in an extensible variety of appropriate formats, providing data in a consistent structure regardless of the format the data happens to be stored in at rest. The natively-supported formats span slow but widespread interchange formats (e.g. CSV, JSON) and fast, efficient ones (e.g. C buffers, Apache Arrow Tables). Tiled enables slicing and sub-selection to read and transfer only the data of interest, and it enables parallelized download of many chunks at once. Users can access data with very light software dependencies and fast partial downloads. Tiled puts an emphasis on structures rather than formats, including N-dimensional strided arrays (i.e. numpy-like arrays), tabular data (i.e. pandas-like“dataframes”), and hierarchical structures thereof (e.g. xarrays, HDF5-compatible structures like NeXus). Tiled implements extensible access control enforcement based on web security standards, similar -to JupyterHub Authenticators. Like Jupyter, Tiled can be used by a single user or deployed as a shared resource. Tiled facilitates local client-side caching in a standard web browser or in Tiled’s Python client, making efficient use of bandwidth and enabling an offline “airplane mode.” Service-side caching of "hot" datasets and resources is also possible. Tiled is conceptually “complete” but still new enough that there is room for disruptive suggestions and feedback. We are interested in particular in exploring how Tiled could be made broadly available to NERSC users alongside traditional file-based access, and how that work might prompt us to rethink aspects of Tiled’s design.
Bio:
Dan Allan is scientific software developer and group lead in the Data Science and Systems Integration Program at NSLS-II. He joined Brookhaven National Lab as a post-doc in 2015 after studying soft condensed-matter experimental physics and getting involved in the open source scientific Python community. He works on data acquisition, management, and analysis within and around the "Bluesky" software ecosystem.
Host of Seminar:
Bjoern Enders
Data Science Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Tiled: A Service for Structured Data Access
Speaker:
Dan Allan, NSLS-II - Brookhaven National Laboratory
Abstract:
In the Data Science and Systems Integration Program at NSLS-II, we have explored various ways to separate I/O code from user science code. After seven years of developing in-house solutions and contributing to external ones (including Intake), we propose an abstraction that we think is a broadly useful building block, named Tiled. Tiled is a data access service for data-aware portals and data science tools. It has a Python client that feels much like h5py to use and integrates naturally with dask, but nothing about the service is Python-specific; it also works from curl. Tiled’s service sits atop databases, filesystems, and/or remote services to enable search and structured, chunk-wise access to data in an extensible variety of appropriate formats, providing data in a consistent structure regardless of the format the data happens to be stored in at rest. The natively-supported formats span slow but widespread interchange formats (e.g. CSV, JSON) and fast, efficient ones (e.g. C buffers, Apache Arrow Tables). Tiled enables slicing and sub-selection to read and transfer only the data of interest, and it enables parallelized download of many chunks at once. Users can access data with very light software dependencies and fast partial downloads. Tiled puts an emphasis on structures rather than formats, including N-dimensional strided arrays (i.e. numpy-like arrays), tabular data (i.e. pandas-like“dataframes”), and hierarchical structures thereof (e.g. xarrays, HDF5-compatible structures like NeXus). Tiled implements extensible access control enforcement based on web security standards, similar -to JupyterHub Authenticators. Like Jupyter, Tiled can be used by a single user or deployed as a shared resource. Tiled facilitates local client-side caching in a standard web browser or in Tiled’s Python client, making efficient use of bandwidth and enabling an offline “airplane mode.” Service-side caching of "hot" datasets and resources is also possible. Tiled is conceptually “complete” but still new enough that there is room for disruptive suggestions and feedback. We are interested in particular in exploring how Tiled could be made broadly available to NERSC users alongside traditional file-based access, and how that work might prompt us to rethink aspects of Tiled’s design.
Bio:
Dan Allan is scientific software developer and group lead in the Data Science and Systems Integration Program at NSLS-II. He joined Brookhaven National Lab as a post-doc in 2015 after studying soft condensed-matter experimental physics and getting involved in the open source scientific Python community. He works on data acquisition, management, and analysis within and around the "Bluesky" software ecosystem.
Host of Seminar:
Bjoern Enders
Data Science Engagement Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 7 participants
- 57 minutes

2 Nov 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Characterizing I/O behavior of large-scale scientific deep learning applications
Speaker:
Hariharan Devarajan, Lawrence Livermore National Laboratory
Abstract:
Deep learning has been shown as a successful method for various tasks, and its popularity results in numerous open-source deep learning software tools. Deep learning has been applied to a broad spectrum of scientific domains such as cosmology, particle physics, computer vision, fusion, and astrophysics. Scientists have performed a great deal of work to optimize the computational performance of deep learning frameworks. However, the same cannot be said for I/O performance. As deep learning algorithms rely on big-data volume and variety to effectively train neural networks accurately, I/O is a significant bottleneck on large-scale distributed deep learning training. In this talk, I will share our experiences of running large-scale DL applications on Theta supercomputer with a detailed investigation of the I/O behavior of various scientific deep learning workloads. Additionally, I will showcase our DLIO Benchmark, which accurately represents the class of applications previously characterized to foster I/O research in these classes of applications. I will share some key results and insights we discovered in modern scientific DL applications including, access patterns, integration with scientific data formats, and their I/O scalability in production supercomputers. Finally, I would highlight key pain points in doing I/O characterization of DL applications and discuss some research directions to improve these aspects.
Bio:
Hariharan Devarajan is a Postdoctoral researcher at Lawrence Livermore National Laboratory. He received his Ph.D. in Computer Science at Illinois Institute of Technology, advised by Dr. Xian-He Sun. His research is focused on accurate I/O characterization of distributed applications and building highly configurable storage systems on large-scale distributed systems. He has worked on I/O optimizations in several domains such as scientific simulations, AI, and Big Data Analytics and specializes in designing solutions for hierarchical storage environments. He is the recipient of the best paper awards at HPDC and CCGrid.
Host of Seminar:
Suren Byna
Computational Research Division
Lawrence Berkeley National Laboratory
Title:
Characterizing I/O behavior of large-scale scientific deep learning applications
Speaker:
Hariharan Devarajan, Lawrence Livermore National Laboratory
Abstract:
Deep learning has been shown as a successful method for various tasks, and its popularity results in numerous open-source deep learning software tools. Deep learning has been applied to a broad spectrum of scientific domains such as cosmology, particle physics, computer vision, fusion, and astrophysics. Scientists have performed a great deal of work to optimize the computational performance of deep learning frameworks. However, the same cannot be said for I/O performance. As deep learning algorithms rely on big-data volume and variety to effectively train neural networks accurately, I/O is a significant bottleneck on large-scale distributed deep learning training. In this talk, I will share our experiences of running large-scale DL applications on Theta supercomputer with a detailed investigation of the I/O behavior of various scientific deep learning workloads. Additionally, I will showcase our DLIO Benchmark, which accurately represents the class of applications previously characterized to foster I/O research in these classes of applications. I will share some key results and insights we discovered in modern scientific DL applications including, access patterns, integration with scientific data formats, and their I/O scalability in production supercomputers. Finally, I would highlight key pain points in doing I/O characterization of DL applications and discuss some research directions to improve these aspects.
Bio:
Hariharan Devarajan is a Postdoctoral researcher at Lawrence Livermore National Laboratory. He received his Ph.D. in Computer Science at Illinois Institute of Technology, advised by Dr. Xian-He Sun. His research is focused on accurate I/O characterization of distributed applications and building highly configurable storage systems on large-scale distributed systems. He has worked on I/O optimizations in several domains such as scientific simulations, AI, and Big Data Analytics and specializes in designing solutions for hierarchical storage environments. He is the recipient of the best paper awards at HPDC and CCGrid.
Host of Seminar:
Suren Byna
Computational Research Division
Lawrence Berkeley National Laboratory
- 2 participants
- 35 minutes

26 Oct 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
David Kanter, MLCommons
Title:
Challenges and Directions in ML System Performance: The MLPerf Story
Abstract:
As the industry drives towards more capable ML, workloads are rapidly evolving and the need for performance is nearly unlimited. We explore the challenges and design choices behind MLPerf, the industry standard benchmark for ML system performance.
Bio:
David Kanter is a Founder and the Executive Director of MLCommons™ where he helps lead the MLPerf™ benchmarks and other initiatives. He has 16+ years of experience in semiconductors, computing, and machine learning. He founded a microprocessor and compiler startup, was an early employee at Aster Data Systems, and has consulted for industry leaders such as Intel, Nvidia, KLA, Applied Materials, Qualcomm, Microsoft and many others. David holds a Bachelor of Science degree with honors in Mathematics with a specialization in Computer Science, and a Bachelor of Arts with honors in Economics from the University of Chicago.
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
Steve Farrell, Data Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
David Kanter, MLCommons
Title:
Challenges and Directions in ML System Performance: The MLPerf Story
Abstract:
As the industry drives towards more capable ML, workloads are rapidly evolving and the need for performance is nearly unlimited. We explore the challenges and design choices behind MLPerf, the industry standard benchmark for ML system performance.
Bio:
David Kanter is a Founder and the Executive Director of MLCommons™ where he helps lead the MLPerf™ benchmarks and other initiatives. He has 16+ years of experience in semiconductors, computing, and machine learning. He founded a microprocessor and compiler startup, was an early employee at Aster Data Systems, and has consulted for industry leaders such as Intel, Nvidia, KLA, Applied Materials, Qualcomm, Microsoft and many others. David holds a Bachelor of Science degree with honors in Mathematics with a specialization in Computer Science, and a Bachelor of Arts with honors in Economics from the University of Chicago.
Host of Seminar:
Hai Ah Nam, Advanced Technologies Group
Steve Farrell, Data Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 4 participants
- 59 minutes

19 Oct 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Luiz DeRose, Ph.D., Oracle
Title:
Scaling Out HPC with On-Premise Performance in the Oracle Cloud Infrastructure
Abstract:
The continuous increase in complexity and scale of high-end systems, together with the evolving diversity of processor options, are forcing computational scientists to face system characteristics that can significantly impact the performance and scalability of applications. HPC users need a system infrastructure that can adapt to their workload needs, rather than having to constantly redesign their applications to adapt to new systems. In this talk, I will discuss the current trends in computer architecture and the implications in the development of HPC applications and programming and middleware environments. I will present the Oracle Cloud Infrastructure (OCI), which provides availability, resiliency, and performance at scale, so HPC users can easily choose the best option for their workloads, and will discuss hybrid on-prem/cloud options, which facilitate workload migration from on-premise to the cloud. I will finish the presentation with a discussion of some of the challenges and open research problems that still need to be addressed in this area.
Bio:
Dr. Luiz DeRose is a Director of Cloud Engineering for HPC at Oracle. Before joining Oracle, he was a Sr. Science Manager at AWS, and a Senior Principal Engineer and the Programming Environments Director at Cray. Dr. DeRose has a Ph.D. in Computer Science from the University of Illinois at Urbana-Champaign. He has more than 25 years of high-performance computing experience and a deep knowledge of programming and middleware environments for HPC. Dr. DeRose has eight patents and has published more than 50 peer-review articles in scientific journals, conferences, and book chapters, primarily on the topics of compilers and tools for high performance computing.
Host of Seminar:
Jonathan Skone, Ph.D.
Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Luiz DeRose, Ph.D., Oracle
Title:
Scaling Out HPC with On-Premise Performance in the Oracle Cloud Infrastructure
Abstract:
The continuous increase in complexity and scale of high-end systems, together with the evolving diversity of processor options, are forcing computational scientists to face system characteristics that can significantly impact the performance and scalability of applications. HPC users need a system infrastructure that can adapt to their workload needs, rather than having to constantly redesign their applications to adapt to new systems. In this talk, I will discuss the current trends in computer architecture and the implications in the development of HPC applications and programming and middleware environments. I will present the Oracle Cloud Infrastructure (OCI), which provides availability, resiliency, and performance at scale, so HPC users can easily choose the best option for their workloads, and will discuss hybrid on-prem/cloud options, which facilitate workload migration from on-premise to the cloud. I will finish the presentation with a discussion of some of the challenges and open research problems that still need to be addressed in this area.
Bio:
Dr. Luiz DeRose is a Director of Cloud Engineering for HPC at Oracle. Before joining Oracle, he was a Sr. Science Manager at AWS, and a Senior Principal Engineer and the Programming Environments Director at Cray. Dr. DeRose has a Ph.D. in Computer Science from the University of Illinois at Urbana-Champaign. He has more than 25 years of high-performance computing experience and a deep knowledge of programming and middleware environments for HPC. Dr. DeRose has eight patents and has published more than 50 peer-review articles in scientific journals, conferences, and book chapters, primarily on the topics of compilers and tools for high performance computing.
Host of Seminar:
Jonathan Skone, Ph.D.
Data & Analytics Services Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 56 minutes

28 Sep 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Richard Hawryluk, PPPL
Troy Carter, UCLA
Brian Wirth, ORNL
Chris Holland, UCSD
Dave Humphreys, General Atomics
Title:
Fusion Long Range Plan and Fusion Energy Sciences Advisory Committee Report Briefing and Current and Future FES Needs at NERSC
Abstract:
Research in Fusion Energy Sciences comprises a big portion of the NERSC workload. Recently FES has developed a long-range plan to guide research priorities. The leaders of this effort will give a summary of these plans with an emphasis on how they involve NERSC and HPC. Outline: Troy Carter Brief overview of FESAC long-range plan with slide on HPC modeling (15 min), Rich Hawryluk main recommendations from NASEM report and strategic plan (8min), Brian Wirth role integrated design teams and integrated modeling (8min), Dave Humphreys report on FES/ASCR machine learning workshop (15 min Q&A).
Host of Seminar:
Richard Gerber
Senior Science Advisor | HPC Department Head
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Richard Hawryluk, PPPL
Troy Carter, UCLA
Brian Wirth, ORNL
Chris Holland, UCSD
Dave Humphreys, General Atomics
Title:
Fusion Long Range Plan and Fusion Energy Sciences Advisory Committee Report Briefing and Current and Future FES Needs at NERSC
Abstract:
Research in Fusion Energy Sciences comprises a big portion of the NERSC workload. Recently FES has developed a long-range plan to guide research priorities. The leaders of this effort will give a summary of these plans with an emphasis on how they involve NERSC and HPC. Outline: Troy Carter Brief overview of FESAC long-range plan with slide on HPC modeling (15 min), Rich Hawryluk main recommendations from NASEM report and strategic plan (8min), Brian Wirth role integrated design teams and integrated modeling (8min), Dave Humphreys report on FES/ASCR machine learning workshop (15 min Q&A).
Host of Seminar:
Richard Gerber
Senior Science Advisor | HPC Department Head
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 7 participants
- 1:09 hours

21 Sep 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Sudheer Chunduri, Argonne National Lab
Kevin Harms, Argonne National Lab
Title:
Darshan 3.3.0 & Autoperf 2.0 updates
Abstract:
AutoPerf is a lightweight profiling tool used for Automatic performance collection of MPI (focused on MPI 2.0 operations) usage and hardware performance counter information. AutoPerf 1.0 was deployed on Argonne’s earlier general machine called Mira and was successfully collected logs for over 4-5 years. The analysis from this data was helpful in providing several insights in the MPI space* and beyond. Considering the feedback from this study and to enhance the coverage for more MPI 3.0 operations and other improvements in the recorded and reported summary data, Autoperf 2.0 is designed. AutoPerf2.0 implements two additional Darshan instrumentation modules that can provide details on application MPI communication usage and application performance characteristics on Cray XC platforms. We will describe our plans for future work in this topic and provide a summary of Darshan latest release.
Bio:
Sudheer Chunduri is a member of Performance Engineering team at ALCF working on the interconnects and MPI developments and performance analysis.
Kevin Harms is a Performance Engineering Team Lead at ALCF working on Parallel IO, storage and platform analysis and benchmarking aspects.
Host of Seminar:
Taylor Groves
Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Sudheer Chunduri, Argonne National Lab
Kevin Harms, Argonne National Lab
Title:
Darshan 3.3.0 & Autoperf 2.0 updates
Abstract:
AutoPerf is a lightweight profiling tool used for Automatic performance collection of MPI (focused on MPI 2.0 operations) usage and hardware performance counter information. AutoPerf 1.0 was deployed on Argonne’s earlier general machine called Mira and was successfully collected logs for over 4-5 years. The analysis from this data was helpful in providing several insights in the MPI space* and beyond. Considering the feedback from this study and to enhance the coverage for more MPI 3.0 operations and other improvements in the recorded and reported summary data, Autoperf 2.0 is designed. AutoPerf2.0 implements two additional Darshan instrumentation modules that can provide details on application MPI communication usage and application performance characteristics on Cray XC platforms. We will describe our plans for future work in this topic and provide a summary of Darshan latest release.
Bio:
Sudheer Chunduri is a member of Performance Engineering team at ALCF working on the interconnects and MPI developments and performance analysis.
Kevin Harms is a Performance Engineering Team Lead at ALCF working on Parallel IO, storage and platform analysis and benchmarking aspects.
Host of Seminar:
Taylor Groves
Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 7 participants
- 1:00 hours

14 Sep 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Jonathan Skone
Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Challenges and successes with a hybrid multicloud implementation for research computing
Abstract:
A review of the efforts to evolve an academic on-premises HPC ecosystem to the cloud through the hybrid multicloud solution named Skyway, will be presented. Skyway incorporates multicloud computing resources as elastic extensions of its on-premises HPC infrastructure and makes use of a system-level software package to interface the job scheduler and cloud SDKs, resulting in a seamless experience for users when interacting with both on-premises and cloud resources. The implementation is general enough to interface with one or more cloud providers, which currently include both Amazon AWS and Google GCP. The challenges encountered and the use cases where it has been successful, will be elaborated.
Bio:
https://www.nersc.gov/about/nersc-staff/advanced-technologies-group/jonathan-skone/
Host of Seminar:
Nicholas Wright
Group Leader, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Jonathan Skone
Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
Challenges and successes with a hybrid multicloud implementation for research computing
Abstract:
A review of the efforts to evolve an academic on-premises HPC ecosystem to the cloud through the hybrid multicloud solution named Skyway, will be presented. Skyway incorporates multicloud computing resources as elastic extensions of its on-premises HPC infrastructure and makes use of a system-level software package to interface the job scheduler and cloud SDKs, resulting in a seamless experience for users when interacting with both on-premises and cloud resources. The implementation is general enough to interface with one or more cloud providers, which currently include both Amazon AWS and Google GCP. The challenges encountered and the use cases where it has been successful, will be elaborated.
Bio:
https://www.nersc.gov/about/nersc-staff/advanced-technologies-group/jonathan-skone/
Host of Seminar:
Nicholas Wright
Group Leader, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 60 minutes

24 Aug 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Kjiersten Fagnan
Joint Genome Institute (JGI)
Lawrence Berkeley National Laboratory
Title:
JGI Computing - the future is looking cloudy
Abstract:
The DOE Joint Genome Institute produces high-quality omics data from fungi, plants, microbes, and metagenomes. The computational infrastructure needed to support processing and analysis spans laptops to exascale. JGI has adapted to these needs through moving to a distributed network of computing and storage resources. In this talk I'll describe those resources, what's run where, and the software infrastructure we're building to maintain a high level of usability for JGI's staff and User community.
Host of Seminar:
Nicholas Wright
Group Leader, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Kjiersten Fagnan
Joint Genome Institute (JGI)
Lawrence Berkeley National Laboratory
Title:
JGI Computing - the future is looking cloudy
Abstract:
The DOE Joint Genome Institute produces high-quality omics data from fungi, plants, microbes, and metagenomes. The computational infrastructure needed to support processing and analysis spans laptops to exascale. JGI has adapted to these needs through moving to a distributed network of computing and storage resources. In this talk I'll describe those resources, what's run where, and the software infrastructure we're building to maintain a high level of usability for JGI's staff and User community.
Host of Seminar:
Nicholas Wright
Group Leader, Advanced Technologies Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 43 minutes

10 Aug 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Brandon Cook
Application Performance Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
LDMS data at NERSC: doing something useful with 8 petabytes of CSV files
Abstract:
Analysis of telemetry data from NERSC systems offers the potential for deeper quantitative understanding of the NERSC workload - providing insights for future system design, operation and optimization of the current platform, feedback to developers about workflow performance and diagnostics to uncover issues with workflows. NERSC uses the Lightweight Distributed Metric Service (LDMS) for lightweight collection of a large variety of metrics on NERSC systems; including memory usage, CPU HW counters, power consumption, network and I/O traffic. Across the compute nodes of Cori currently a total of ~400 MB/s worth of data is being collected and stored in CSV file format. With current retention policies there are approximately 8 petabytes of data in CSV format. The size and number of the CSV files along with the desire to integrate with other sources such as Slurm accounting poses several challenges for anyone who wants to work with this data. In this talk, I will walk through this data set: how it is collected, what is in it, where it is located. Then I will discuss a post processing pipeline that transforms, filters, joins this data with Slurm accounting information, and finally stores it 20 - 200 times more efficiently than CSV. Finally I will discuss how the results of the pipeline are used in Iris through the Superfacility API to provide plots directly to users for all non-shared jobs on Cori in O(seconds). Throughout the talk I will highlight how these resources can be accessed and extended.
Bio:
Brandon leads the simulations area of NERSC's application readiness program (NESAP) and works on understanding and analyzing performance on a system and application level, developing future benchmark suites, analyzing future architectures, developing tools to help NERSC users/staff be more productive, engaging users through consulting, acting as NERSC liaison for several NESAP teams, and exploring future programming models. Brandon received his Ph.D. in physics from Vanderbilt University in 2012, where he studied ab initio methods for quantum transport in nanomaterials. Before joining NERSC he was a postdoc at Oak Ridge National Laboratory where he developed and applied electronic structure methods to problems in material science.
Host of Seminar:
Wahid Bhimji
Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Brandon Cook
Application Performance Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title:
LDMS data at NERSC: doing something useful with 8 petabytes of CSV files
Abstract:
Analysis of telemetry data from NERSC systems offers the potential for deeper quantitative understanding of the NERSC workload - providing insights for future system design, operation and optimization of the current platform, feedback to developers about workflow performance and diagnostics to uncover issues with workflows. NERSC uses the Lightweight Distributed Metric Service (LDMS) for lightweight collection of a large variety of metrics on NERSC systems; including memory usage, CPU HW counters, power consumption, network and I/O traffic. Across the compute nodes of Cori currently a total of ~400 MB/s worth of data is being collected and stored in CSV file format. With current retention policies there are approximately 8 petabytes of data in CSV format. The size and number of the CSV files along with the desire to integrate with other sources such as Slurm accounting poses several challenges for anyone who wants to work with this data. In this talk, I will walk through this data set: how it is collected, what is in it, where it is located. Then I will discuss a post processing pipeline that transforms, filters, joins this data with Slurm accounting information, and finally stores it 20 - 200 times more efficiently than CSV. Finally I will discuss how the results of the pipeline are used in Iris through the Superfacility API to provide plots directly to users for all non-shared jobs on Cori in O(seconds). Throughout the talk I will highlight how these resources can be accessed and extended.
Bio:
Brandon leads the simulations area of NERSC's application readiness program (NESAP) and works on understanding and analyzing performance on a system and application level, developing future benchmark suites, analyzing future architectures, developing tools to help NERSC users/staff be more productive, engaging users through consulting, acting as NERSC liaison for several NESAP teams, and exploring future programming models. Brandon received his Ph.D. in physics from Vanderbilt University in 2012, where he studied ab initio methods for quantum transport in nanomaterials. Before joining NERSC he was a postdoc at Oak Ridge National Laboratory where he developed and applied electronic structure methods to problems in material science.
Host of Seminar:
Wahid Bhimji
Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 9 participants
- 58 minutes

3 Aug 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Speaker:
Manolis Papadakis
NVIDIA
Title:
Legate: High Productivity High Performance Computing
Abstract:
The Legate project (https://github.com/nv-legate) aims to provide distributed and accelerated drop-in replacements for popular scientific / data-science libraries (NumPy and Pandas so far). Our goal is to allow programmers to prototype their applications on their local machine, then be able to transparently scale up to large clusters, utilizing the available acceleration hardware, without having to rewrite their application in an explicit parallel programming model like MPI or Dask. By building all Legate libraries on top of Legion's distributed data model and runtime we can achieve seamless asynchronous execution across libraries, with minimal blocking and copying.
Bio:
Manolis Papadakis is a Senior Software Engineer at NVIDIA, working on the Legate project.
Host of Seminar:
Laurie Stephey
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Speaker:
Manolis Papadakis
NVIDIA
Title:
Legate: High Productivity High Performance Computing
Abstract:
The Legate project (https://github.com/nv-legate) aims to provide distributed and accelerated drop-in replacements for popular scientific / data-science libraries (NumPy and Pandas so far). Our goal is to allow programmers to prototype their applications on their local machine, then be able to transparently scale up to large clusters, utilizing the available acceleration hardware, without having to rewrite their application in an explicit parallel programming model like MPI or Dask. By building all Legate libraries on top of Legion's distributed data model and runtime we can achieve seamless asynchronous execution across libraries, with minimal blocking and copying.
Bio:
Manolis Papadakis is a Senior Software Engineer at NVIDIA, working on the Legate project.
Host of Seminar:
Laurie Stephey
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 3 participants
- 41 minutes

13 Jul 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Monitoring Scientific Python Usage at NERSC
Speaker:
Rollin Thomas
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Abstract:
Last year about 30% of all NERSC users ran jobs involving Python in some way. The most popular Python package in use in Python jobs isn't NumPy, it's multiprocessing. And among Python-based MPI jobs, AstroPy appears to be the most significant package in use. How do we know this and how does this information help us? In this talk, I will discuss how NERSC monitors the use of Python on its systems, as part of its Monitoring of Data Services (MODS) project. The talk will cover how the data is collected, stored, analyzed, and published for consumption by various stakeholders (staff, management, developers, etc.) using a Jupyter notebook-centric workflow involving GPUs, Dask, Papermill, Voilà, and Spin.
Bio:
Rollin Thomas is a Data Architect in the Data and Analytics Services group at NERSC. From 2015 to 2020 he was in charge of Python support on Cori.
Host of Seminar:
Wahid Bhimji
Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title: Monitoring Scientific Python Usage at NERSC
Speaker:
Rollin Thomas
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Abstract:
Last year about 30% of all NERSC users ran jobs involving Python in some way. The most popular Python package in use in Python jobs isn't NumPy, it's multiprocessing. And among Python-based MPI jobs, AstroPy appears to be the most significant package in use. How do we know this and how does this information help us? In this talk, I will discuss how NERSC monitors the use of Python on its systems, as part of its Monitoring of Data Services (MODS) project. The talk will cover how the data is collected, stored, analyzed, and published for consumption by various stakeholders (staff, management, developers, etc.) using a Jupyter notebook-centric workflow involving GPUs, Dask, Papermill, Voilà, and Spin.
Bio:
Rollin Thomas is a Data Architect in the Data and Analytics Services group at NERSC. From 2015 to 2020 he was in charge of Python support on Cori.
Host of Seminar:
Wahid Bhimji
Acting Group Leader, Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 2 participants
- 30 minutes

16 Apr 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: The Open Catalyst 2020 (OC20) Dataset and Community Challenges
Speaker(s):
Zachary Ulissi, Assistant Professor of Chemical Engineering at Carnegie Mellon University
Larry Zitnick, Research Scientist at Facebook AI Research
Abstract:
The Open Catalyst Project aims to develop new ML methods and models to accelerate the catalyst simulation process for renewable energy technologies and improve our ability to predict activity/selectivity across catalyst composition. To achieve that in the short term we need participation from the ML community in solving key challenges in catalysis. One path to interaction is the development of grand challenge datasets that are representative of common challenges in catalysis, large enough to excite the ML community, and large enough to take advantage of and encourage advances in deep learning models. Similar datasets have had a large impact in small molecule drug discovery, organic photovoltaics, and inorganic crystal structure prediction. We present the first open dataset from this effort on thermochemical intermediates across stable multi-metallic and p-block doped surfaces. This dataset includes full-accuracy DFT calculations across 53 elements and their binary/ternary materials, various low-index facets. Adsorbates span 56 common reaction intermediates with relevance to carbon, oxygen, and nitrogen thermal and electrochemical reactions. Off-equilibrium structures are also generated and included to aid in machine learning force field design and fitting. Collectively, this dataset represents the largest systematic dataset that bridges organic and inorganic chemistry and will enable a new generation of catalyst structure/property relationships. Fixed train/test splits that represent common chemical challenges and an open challenge website will be discussed to encourage competition and buy-in from the ML community.
Bio:
Zachary Ulissi is an Assistant Professor of Chemical Engineering at Carnegie Mellon University. He works on the development and application of high-throughput computational methods in catalysis, machine learning models to predict their properties, and active learning methods to guide these systems. Applications include energy materials, CO2 utilization, fuel cell development, and additive manufacturing. He has been recognized nationally for his work including the 3M Non-Tenured Faculty Award and the AIChE 35-under-35 award among others.
Larry Zitnick is a research scientist at Facebook AI Research in Menlo Park. His current areas of interest include scientific applications of AI, language and vision, and object recognition. He serves on the board of the Common Visual Data Foundation whose mission is to aid the computer vision community in creating datasets and competitions. Previously, he spent 12 great years at Microsoft Research, and obtained a PhD in Robotics from CMU's Robotics Institute.
Host of Seminar:
Brandon Wood
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
Title: The Open Catalyst 2020 (OC20) Dataset and Community Challenges
Speaker(s):
Zachary Ulissi, Assistant Professor of Chemical Engineering at Carnegie Mellon University
Larry Zitnick, Research Scientist at Facebook AI Research
Abstract:
The Open Catalyst Project aims to develop new ML methods and models to accelerate the catalyst simulation process for renewable energy technologies and improve our ability to predict activity/selectivity across catalyst composition. To achieve that in the short term we need participation from the ML community in solving key challenges in catalysis. One path to interaction is the development of grand challenge datasets that are representative of common challenges in catalysis, large enough to excite the ML community, and large enough to take advantage of and encourage advances in deep learning models. Similar datasets have had a large impact in small molecule drug discovery, organic photovoltaics, and inorganic crystal structure prediction. We present the first open dataset from this effort on thermochemical intermediates across stable multi-metallic and p-block doped surfaces. This dataset includes full-accuracy DFT calculations across 53 elements and their binary/ternary materials, various low-index facets. Adsorbates span 56 common reaction intermediates with relevance to carbon, oxygen, and nitrogen thermal and electrochemical reactions. Off-equilibrium structures are also generated and included to aid in machine learning force field design and fitting. Collectively, this dataset represents the largest systematic dataset that bridges organic and inorganic chemistry and will enable a new generation of catalyst structure/property relationships. Fixed train/test splits that represent common chemical challenges and an open challenge website will be discussed to encourage competition and buy-in from the ML community.
Bio:
Zachary Ulissi is an Assistant Professor of Chemical Engineering at Carnegie Mellon University. He works on the development and application of high-throughput computational methods in catalysis, machine learning models to predict their properties, and active learning methods to guide these systems. Applications include energy materials, CO2 utilization, fuel cell development, and additive manufacturing. He has been recognized nationally for his work including the 3M Non-Tenured Faculty Award and the AIChE 35-under-35 award among others.
Larry Zitnick is a research scientist at Facebook AI Research in Menlo Park. His current areas of interest include scientific applications of AI, language and vision, and object recognition. He serves on the board of the Common Visual Data Foundation whose mission is to aid the computer vision community in creating datasets and competitions. Previously, he spent 12 great years at Microsoft Research, and obtained a PhD in Robotics from CMU's Robotics Institute.
Host of Seminar:
Brandon Wood
Data & Analytics Group
National Energy Research Scientific Computing Center (NERSC)
Lawrence Berkeley National Laboratory
- 5 participants
- 50 minutes

9 Mar 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Darshan: Enabling Application IO Understanding in an Evolving HPC Landscape
Speaker:
Shane Snyder (Argonne National Laboratory)
Abstract:
Darshan is a lightweight, application I/O characterization tool that captures detailed statistics describing an application's I/O workload. Installed and enabled by default at many production HPC facilities (including at NERSC), Darshan has become an invaluable tool for users, system admins, and I/O researchers to investigate and tune the I/O behavior of applications. While the initial focus of Darshan was on instrumenting file-based APIs (e.g., POSIX, MPI-IO) for MPI applications, much recent work has focused on extending Darshan to new contexts that are increasingly relevant in the HPC community, including object-based storage APIs (e.g., DAOS) and non-MPI computational frameworks (e.g., Spark, TensorFlow). In this seminar, we describe how users can leverage Darshan to better understand the I/O behavior of their applications. We provide details on how users can produce Darshan instrumentation data for their applications and how to further analyze this data, focusing specifically on the Cori system at NERSC. New and upcoming features are covered that aim to extend Darshan to exciting I/O instrumentation contexts for HPC, including instrumentation modules for HDF5 and DAOS libraries, as well as support for instrumenting non-MPI applications and frameworks. We further walk through a couple of Darshan log analysis examples to help illustrate the types of I/O insights that can be attained using Darshan log data and analysis tools.
Bio:
Shane Snyder is a software engineer in the Mathematics and Computer Science Division of Argonne National Laboratory. He received his master's degree in computer engineering from Clemson University in 2013. His research interests primarily include the design of high-performance distributed storage systems and the characterization and analysis of I/O workloads on production HPC systems.
Title: Darshan: Enabling Application IO Understanding in an Evolving HPC Landscape
Speaker:
Shane Snyder (Argonne National Laboratory)
Abstract:
Darshan is a lightweight, application I/O characterization tool that captures detailed statistics describing an application's I/O workload. Installed and enabled by default at many production HPC facilities (including at NERSC), Darshan has become an invaluable tool for users, system admins, and I/O researchers to investigate and tune the I/O behavior of applications. While the initial focus of Darshan was on instrumenting file-based APIs (e.g., POSIX, MPI-IO) for MPI applications, much recent work has focused on extending Darshan to new contexts that are increasingly relevant in the HPC community, including object-based storage APIs (e.g., DAOS) and non-MPI computational frameworks (e.g., Spark, TensorFlow). In this seminar, we describe how users can leverage Darshan to better understand the I/O behavior of their applications. We provide details on how users can produce Darshan instrumentation data for their applications and how to further analyze this data, focusing specifically on the Cori system at NERSC. New and upcoming features are covered that aim to extend Darshan to exciting I/O instrumentation contexts for HPC, including instrumentation modules for HDF5 and DAOS libraries, as well as support for instrumenting non-MPI applications and frameworks. We further walk through a couple of Darshan log analysis examples to help illustrate the types of I/O insights that can be attained using Darshan log data and analysis tools.
Bio:
Shane Snyder is a software engineer in the Mathematics and Computer Science Division of Argonne National Laboratory. He received his master's degree in computer engineering from Clemson University in 2013. His research interests primarily include the design of high-performance distributed storage systems and the characterization and analysis of I/O workloads on production HPC systems.
- 5 participants
- 58 minutes
23 Feb 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: The CS Area Superfacility Project: Year in Review 2020
Speakers: The Superfacility Team
Abstract: The Superfacility project has been busy in 2020! In this talk, we will present lightning updates from each area of technical work, highlighting the progress and achievements we've made in the past year.
Bio:
The Superfacility project includes staff from NERSC, ESnet and CRD.
Title: The CS Area Superfacility Project: Year in Review 2020
Speakers: The Superfacility Team
Abstract: The Superfacility project has been busy in 2020! In this talk, we will present lightning updates from each area of technical work, highlighting the progress and achievements we've made in the past year.
Bio:
The Superfacility project includes staff from NERSC, ESnet and CRD.
- 18 participants
- 48 minutes

19 Jan 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Self-Supervised Representation Learning for Astronomical Images
Speakers: Md Abul Hayat (University of Arkansas, Berkeley Lab), George Stein (UCB, Berkeley Lab)
Abstract: Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS), to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state- of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.
Bios:
Md Abul Hayat is a 4th year PhD student of Electrical engineering at the University of Arkansas. His research is on predicting hydration status using signal processing and statistical learning techniques from biomedical signals. In past years he has worked at Berkeley Lab and Nokia Bell Labs as a summer intern. Before joining the PhD program, he has worked as a telecommunications system engineer at Telenor Bangladesh.
George Stein is a postdoc at LBL/BCCP, with research centered on machine learning for cosmology. Areas of focus include cosmological simulations, generative models, anomaly detection, and of course self-supervised learning.
Title: Self-Supervised Representation Learning for Astronomical Images
Speakers: Md Abul Hayat (University of Arkansas, Berkeley Lab), George Stein (UCB, Berkeley Lab)
Abstract: Sky surveys are the largest data generators in astronomy, making automated tools for extracting meaningful scientific information an absolute necessity. We show that, without the need for labels, self-supervised learning recovers representations of sky survey images that are semantically useful for a variety of scientific tasks. These representations can be directly used as features, or fine-tuned, to outperform supervised methods trained only on labeled data. We apply a contrastive learning framework on multi-band galaxy photometry from the Sloan Digital Sky Survey (SDSS), to learn image representations. We then use them for galaxy morphology classification, and fine-tune them for photometric redshift estimation, using labels from the Galaxy Zoo 2 dataset and SDSS spectroscopy. In both downstream tasks, using the same learned representations, we outperform the supervised state- of-the-art results, and we show that our approach can achieve the accuracy of supervised models while using 2-4 times fewer labels for training.
Bios:
Md Abul Hayat is a 4th year PhD student of Electrical engineering at the University of Arkansas. His research is on predicting hydration status using signal processing and statistical learning techniques from biomedical signals. In past years he has worked at Berkeley Lab and Nokia Bell Labs as a summer intern. Before joining the PhD program, he has worked as a telecommunications system engineer at Telenor Bangladesh.
George Stein is a postdoc at LBL/BCCP, with research centered on machine learning for cosmology. Areas of focus include cosmological simulations, generative models, anomaly detection, and of course self-supervised learning.
- 6 participants
- 54 minutes
12 Jan 2021
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Deep Learning Approaches for Modeling Multi-Scale Chaos and Geophysical Turbulence
Speaker: Ashesh Chattopadhyay (Rice University)
Abstract: Our atmosphere is a coupled, chaotic, and turbulent dynamical system with multiple physical processes interacting with each other, at continuously varying spatio-temporal scales. Building efficient and accurate weather/climate models that can predict the state of the atmosphere for the near and distant future requires us to resolve a broad range of spatio-temporal scales that often take up a daunt- ing amount of computational resources. Thus, current tractable climate models often have inaccurate and crude approximations of hard-to-resolve physical processes that drastically affect our ability to predict the dynamics of the system. Here, we propose alternative data-driven approaches that utilize deep learning algorithms trained on observations or high-resolution model outputs working in conjunction with numerical models to perform carefully constructed approximations that accurately capture the physics of these hard-to-resolve processes. This can reduce computational cost while bringing more insight into poorly understood physics that can dramatically improve our ability to predict the large-scale dynamics of the atmosphere.
Bio: Ashesh Chattopadhyay did his Bachelors from the department of Mechanical Engineering at Indian Institute of Technology, Patna where he worked primarily in optimization and computational geometry. He got his masters from the University of Texas, El Paso, from the Computational Science program where his research was focused on high performance computing. Since then, he has been a PhD student at Rice University in the department of Mechanical Engineering, where he works at the intersection of theoretical deep learning, dynamical systems and turbulence modeling for broad applications in atmospheric dynamics.
Title: Deep Learning Approaches for Modeling Multi-Scale Chaos and Geophysical Turbulence
Speaker: Ashesh Chattopadhyay (Rice University)
Abstract: Our atmosphere is a coupled, chaotic, and turbulent dynamical system with multiple physical processes interacting with each other, at continuously varying spatio-temporal scales. Building efficient and accurate weather/climate models that can predict the state of the atmosphere for the near and distant future requires us to resolve a broad range of spatio-temporal scales that often take up a daunt- ing amount of computational resources. Thus, current tractable climate models often have inaccurate and crude approximations of hard-to-resolve physical processes that drastically affect our ability to predict the dynamics of the system. Here, we propose alternative data-driven approaches that utilize deep learning algorithms trained on observations or high-resolution model outputs working in conjunction with numerical models to perform carefully constructed approximations that accurately capture the physics of these hard-to-resolve processes. This can reduce computational cost while bringing more insight into poorly understood physics that can dramatically improve our ability to predict the large-scale dynamics of the atmosphere.
Bio: Ashesh Chattopadhyay did his Bachelors from the department of Mechanical Engineering at Indian Institute of Technology, Patna where he worked primarily in optimization and computational geometry. He got his masters from the University of Texas, El Paso, from the Computational Science program where his research was focused on high performance computing. Since then, he has been a PhD student at Rice University in the department of Mechanical Engineering, where he works at the intersection of theoretical deep learning, dynamical systems and turbulence modeling for broad applications in atmospheric dynamics.
- 6 participants
- 1:02 hours

16 Oct 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title:
Using Machine Learning to Augment Coarse-Grid Computational Fluid Dynamics Simulations
Abstract:
Simulation of turbulent flows at high Reynolds number is a computationally challenging task relevant to a large number of engineering and scientific applications in diverse fields such as climate science, aerodynamics, and combustion. Turbulent flows are typically modeled by the Navier-Stokes equations. Direct Numerical Simulation (DNS) of the Navier-Stokes equations with sufficient numerical resolution to capture all the relevant scales of the turbulent motions can be prohibitively expensive. Simulation at lower-resolution on a coarse-grid introduces significant errors. We introduce a machine learning (ML) technique based on a deep neural network architecture that corrects the numerical errors induced by a coarse-grid simulation of turbulent flows at high-Reynolds numbers, while simultaneously recovering an estimate of the high-resolution fields. Our proposed simulation strategy is a hybrid ML-PDE solver that is capable of obtaining a meaningful high-resolution solution trajectory while solving the system PDE at a lower resolution. The approach has the potential to dramatically reduce the expense of turbulent flow simulations. As a proof-of-concept, we demonstrate our ML-PDE strategy on a two-dimensional Rayleigh-Bénard Convection (RBC) problem.
Title:
Using Machine Learning to Augment Coarse-Grid Computational Fluid Dynamics Simulations
Abstract:
Simulation of turbulent flows at high Reynolds number is a computationally challenging task relevant to a large number of engineering and scientific applications in diverse fields such as climate science, aerodynamics, and combustion. Turbulent flows are typically modeled by the Navier-Stokes equations. Direct Numerical Simulation (DNS) of the Navier-Stokes equations with sufficient numerical resolution to capture all the relevant scales of the turbulent motions can be prohibitively expensive. Simulation at lower-resolution on a coarse-grid introduces significant errors. We introduce a machine learning (ML) technique based on a deep neural network architecture that corrects the numerical errors induced by a coarse-grid simulation of turbulent flows at high-Reynolds numbers, while simultaneously recovering an estimate of the high-resolution fields. Our proposed simulation strategy is a hybrid ML-PDE solver that is capable of obtaining a meaningful high-resolution solution trajectory while solving the system PDE at a lower resolution. The approach has the potential to dramatically reduce the expense of turbulent flow simulations. As a proof-of-concept, we demonstrate our ML-PDE strategy on a two-dimensional Rayleigh-Bénard Convection (RBC) problem.
- 10 participants
- 59 minutes
2 Oct 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Abstract: Fordecades, the use of HPC systems was limited to those in the physical scienceswho had mastered their domain in conjunction with a deep understanding of HPCarchitectures and algorithms. During these same decades, consumer computingdevice advances produced laptops, tablets, and smartphones that allow millionsto interactively develop and share code projects using high productivitylanguages and environments. The HPC community faces many challenges associatedwith guiding researchers from disciplines that routinely utilize highproductivity interactive tools to effectively use HPC systems, since it is fruitlessto expect them to give up the interactive, on-demand nature of their workflows.
For over adecade, MIT Lincoln Laboratory has been supporting interactive, on-demand HPCby seamlessly integrating familiar high productivity tools to provide userswith an increased number of design turns, rapid prototyping capability, andfaster time to insight. In this talk, we discuss the lessons learned whilesupporting interactive, on-demand high performance computing from theperspectives of the users and the team supporting the users and the system. Atits core, it involves an expansion of what the HPC ecosystem paradigm entailsincluding expansions in system architecture, scheduler policies, metrics ofsuccess, and supported software development environments and tools. We concludewith how our team supports users and the systems in this paradigm expansion.
Abstract: Fordecades, the use of HPC systems was limited to those in the physical scienceswho had mastered their domain in conjunction with a deep understanding of HPCarchitectures and algorithms. During these same decades, consumer computingdevice advances produced laptops, tablets, and smartphones that allow millionsto interactively develop and share code projects using high productivitylanguages and environments. The HPC community faces many challenges associatedwith guiding researchers from disciplines that routinely utilize highproductivity interactive tools to effectively use HPC systems, since it is fruitlessto expect them to give up the interactive, on-demand nature of their workflows.
For over adecade, MIT Lincoln Laboratory has been supporting interactive, on-demand HPCby seamlessly integrating familiar high productivity tools to provide userswith an increased number of design turns, rapid prototyping capability, andfaster time to insight. In this talk, we discuss the lessons learned whilesupporting interactive, on-demand high performance computing from theperspectives of the users and the team supporting the users and the system. Atits core, it involves an expansion of what the HPC ecosystem paradigm entailsincluding expansions in system architecture, scheduler policies, metrics ofsuccess, and supported software development environments and tools. We concludewith how our team supports users and the systems in this paradigm expansion.
- 5 participants
- 1:21 hours

25 Sep 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Abstract: This talk will present an update on the features and future of HDF5 for exascale HPC. Currently, our work focuses on asynchronous I/O and node-local storage caches, but future work will include GPU direct I/O and data movement across the deeper memory hierarchy anticipated on future systems.
Abstract: This talk will present an update on the features and future of HDF5 for exascale HPC. Currently, our work focuses on asynchronous I/O and node-local storage caches, but future work will include GPU direct I/O and data movement across the deeper memory hierarchy anticipated on future systems.
- 6 participants
- 51 minutes

11 Sep 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Flux: Overcoming Scheduling Challenges for Exascale Workflows
Dong Ahn & Stephen Herbein (Lawrence Livermore National Laboratory)
Abstract: Many emerging scientific workflows that target high-end HPC systems require complex interplay with the resource and job management software (RJMS). However, portable, efficient and easy-to-use scheduling and execution of these workflows is still an unsolved problem. In this talk, I will present Flux, a next-generation RJMS designed specifically to address the key scheduling challenges of modern workflows in a scalable, easy-to-use, and portable manner. At the heart of Flux lies its ability to be seamlessly nested within batch allocations created by itself as well as other system schedulers (e.g., SLURM, MOAB, LSF, etc), serving the target workflows as their “personal RJMS instances”. In particular, Flux’s consistent and rich set of well-defined APIs portably and efficiently support those workflows that can often feature non-traditional execution patterns such as requirements for complex co-scheduling, massive ensembles of small jobs and coordination among jobs in an ensemble. As part of this talk, I will also discuss Flux’s graph-based resource data model, Flux’s response to needing to schedule increasingly diverse resources, and how this model is becoming the center of our industry co-design efforts: for example, multi-tiered storage scheduling co-design with HPE and Cloud resource co-design with IBM T.J. Watson and RedHat OpenShift.
Flux: Overcoming Scheduling Challenges for Exascale Workflows
Dong Ahn & Stephen Herbein (Lawrence Livermore National Laboratory)
Abstract: Many emerging scientific workflows that target high-end HPC systems require complex interplay with the resource and job management software (RJMS). However, portable, efficient and easy-to-use scheduling and execution of these workflows is still an unsolved problem. In this talk, I will present Flux, a next-generation RJMS designed specifically to address the key scheduling challenges of modern workflows in a scalable, easy-to-use, and portable manner. At the heart of Flux lies its ability to be seamlessly nested within batch allocations created by itself as well as other system schedulers (e.g., SLURM, MOAB, LSF, etc), serving the target workflows as their “personal RJMS instances”. In particular, Flux’s consistent and rich set of well-defined APIs portably and efficiently support those workflows that can often feature non-traditional execution patterns such as requirements for complex co-scheduling, massive ensembles of small jobs and coordination among jobs in an ensemble. As part of this talk, I will also discuss Flux’s graph-based resource data model, Flux’s response to needing to schedule increasingly diverse resources, and how this model is becoming the center of our industry co-design efforts: for example, multi-tiered storage scheduling co-design with HPE and Cloud resource co-design with IBM T.J. Watson and RedHat OpenShift.
- 5 participants
- 52 minutes

4 Sep 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Steps toward holistic control of particle accelerators with neural networks
Abstract: Particle accelerators are used in a wide array of medical, industrial, and scientific applications, ranging from cancer treatment to understanding fundamental laws of physics. While each of these applications brings with them different operational requirements, a common challenge concerns how to optimally adjust controllable settings of the accelerator to obtain the desired beam characteristics. For example, at highly flexible user facilities like the LCLS and FACET-II, requests for a wide array custom beam configurations must be met in a limited window of time to ensure the success of each experiment — a task which can be difficult both in terms of tuning time and the final achievable solution quality, especially for novel or non-standard setups. At present, the operation of most accelerator facilities relies heavily on manual tuning by highly-skilled human operators, sometimes with the aid of simplified physics models and local optimization algorithms. As a complement to these existing tools, approaches based on machine learning are poised to enhance our ability to achieve higher-quality beams, fulfill requests for custom beam parameters more quickly, and aid the development of novel operating schemes. Focusing on neural network based approaches, I will discuss proof-of-principle studies that point toward the potential of machine learning in this regard, highlight open questions and challenges, and give an outlook on some of the future pathways toward bringing these techniques more fully into operation of accelerators. These improvements could increase the scientific output of user facilities and enable new capabilities by tuning a wider range of machine settings, as well as exploiting subtle sensitivities that may otherwise go unutilized. They could also help us to meet the modeling and tuning challenges that become more acute as we push toward the more difficult-to-achieve beam parameters that are desired for future accelerator applications (e.g. higher beam energies and intensities, higher stability, and extreme adjustments of the beam shape in phase space).
Title: Steps toward holistic control of particle accelerators with neural networks
Abstract: Particle accelerators are used in a wide array of medical, industrial, and scientific applications, ranging from cancer treatment to understanding fundamental laws of physics. While each of these applications brings with them different operational requirements, a common challenge concerns how to optimally adjust controllable settings of the accelerator to obtain the desired beam characteristics. For example, at highly flexible user facilities like the LCLS and FACET-II, requests for a wide array custom beam configurations must be met in a limited window of time to ensure the success of each experiment — a task which can be difficult both in terms of tuning time and the final achievable solution quality, especially for novel or non-standard setups. At present, the operation of most accelerator facilities relies heavily on manual tuning by highly-skilled human operators, sometimes with the aid of simplified physics models and local optimization algorithms. As a complement to these existing tools, approaches based on machine learning are poised to enhance our ability to achieve higher-quality beams, fulfill requests for custom beam parameters more quickly, and aid the development of novel operating schemes. Focusing on neural network based approaches, I will discuss proof-of-principle studies that point toward the potential of machine learning in this regard, highlight open questions and challenges, and give an outlook on some of the future pathways toward bringing these techniques more fully into operation of accelerators. These improvements could increase the scientific output of user facilities and enable new capabilities by tuning a wider range of machine settings, as well as exploiting subtle sensitivities that may otherwise go unutilized. They could also help us to meet the modeling and tuning challenges that become more acute as we push toward the more difficult-to-achieve beam parameters that are desired for future accelerator applications (e.g. higher beam energies and intensities, higher stability, and extreme adjustments of the beam shape in phase space).
- 3 participants
- 59 minutes

24 Jul 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Abstract: Direct physiological observation of subcellular dynamics is now feasible using the Lattice Light-Sheet Microscopy. It is a transformative imaging technology that spans the relevant scales in space and time because of the wide resolution range and large volumetric acquisition capability. This new imaging method allows us to record dynamics at a scale of nanometers and milliseconds, determine their consequences at a scale of microns and hours, and visualize their long-term outcome at a scale of up to several millimeters over several days. I’ll present our past work on combined lattice light sheet microscopy with adaptive optics to achieve (Science, 2018), across large multicellular volumes, noninvasive aberration-free imaging of subcellular dynamics in vivo. Next, I’ll discuss the combination of lattice light-sheet with the physical expansion of samples (Expansion Microscopy) that enables scalable super-resolution volumetric imaging of large tissues (Science, 2019) including the complete fly brain, columns of mouse brain – datasets spanning several hundred terabytes. Finally, I will introduce our next-generation microscope design– dubbed the “Swiss army knife microscope”, which combines at least ten different modes of imaging with integrated light paths. In essence, this new microscope is designed to seamlessly switch between modes of imaging in order to alleviate the tradeoffs related to resolution, speed, invasiveness and imaging depth, which precludes any single optical microscopy to function optimally for a diverse set of biological specimens.
Abstract: Direct physiological observation of subcellular dynamics is now feasible using the Lattice Light-Sheet Microscopy. It is a transformative imaging technology that spans the relevant scales in space and time because of the wide resolution range and large volumetric acquisition capability. This new imaging method allows us to record dynamics at a scale of nanometers and milliseconds, determine their consequences at a scale of microns and hours, and visualize their long-term outcome at a scale of up to several millimeters over several days. I’ll present our past work on combined lattice light sheet microscopy with adaptive optics to achieve (Science, 2018), across large multicellular volumes, noninvasive aberration-free imaging of subcellular dynamics in vivo. Next, I’ll discuss the combination of lattice light-sheet with the physical expansion of samples (Expansion Microscopy) that enables scalable super-resolution volumetric imaging of large tissues (Science, 2019) including the complete fly brain, columns of mouse brain – datasets spanning several hundred terabytes. Finally, I will introduce our next-generation microscope design– dubbed the “Swiss army knife microscope”, which combines at least ten different modes of imaging with integrated light paths. In essence, this new microscope is designed to seamlessly switch between modes of imaging in order to alleviate the tradeoffs related to resolution, speed, invasiveness and imaging depth, which precludes any single optical microscopy to function optimally for a diverse set of biological specimens.
- 2 participants
- 55 minutes

17 Jul 2020
NESRC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Superconducting Radio-Frequency Cavity Fault Classification Using Machine Learning at Jefferson Laboratory
Abstract: We report on the development of machine learning models for classifying C100 superconducting radio-frequency (SRF) cavity faults in the Continuous Electron Beam Accelerator Facility (CEBAF) at Jefferson Lab. CEBAF is a continuous-wave recirculating linac utilizing 418 SRF cavities to accelerate electrons up to 12 GeV through 5-passes. Of these, 96 cavities (12 cryomodules) are designed with a digital low-level RF system configured such that a cavity fault triggers waveform recordings of 17 RF signals for each of the 8 cavities in the cryomodule. Subject matter experts (SME) are able to analyze the collected time-series data and identify which of the eight cavities faulted first and classify the type of fault. This information is used to find trends and strategically deploy mitigations to problematic cryomodules. However manually labeling the data is laborious and time-consuming. By leveraging machine learning, near real-time – rather than post-mortem – identification of the offending cavity and classification of the fault type has been implemented. We discuss the development and performance of the ML models as well as valuable lessons learned in bringing a ML system to deployment.
Title: Superconducting Radio-Frequency Cavity Fault Classification Using Machine Learning at Jefferson Laboratory
Abstract: We report on the development of machine learning models for classifying C100 superconducting radio-frequency (SRF) cavity faults in the Continuous Electron Beam Accelerator Facility (CEBAF) at Jefferson Lab. CEBAF is a continuous-wave recirculating linac utilizing 418 SRF cavities to accelerate electrons up to 12 GeV through 5-passes. Of these, 96 cavities (12 cryomodules) are designed with a digital low-level RF system configured such that a cavity fault triggers waveform recordings of 17 RF signals for each of the 8 cavities in the cryomodule. Subject matter experts (SME) are able to analyze the collected time-series data and identify which of the eight cavities faulted first and classify the type of fault. This information is used to find trends and strategically deploy mitigations to problematic cryomodules. However manually labeling the data is laborious and time-consuming. By leveraging machine learning, near real-time – rather than post-mortem – identification of the offending cavity and classification of the fault type has been implemented. We discuss the development and performance of the ML models as well as valuable lessons learned in bringing a ML system to deployment.
- 6 participants
- 57 minutes
19 Jun 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Title: Status of Containers in HPC
Abstract: Containers have quickly gained traction in HPC and Data Intensive computing. Containers provides users with greater flexibility, enables sharing and reproducibly, can make workflows more portable and can even improve performance. In this talk we will review some of these benefits, the status of containers at NERSC, and trends for containers in HPC. We will also discuss some of the use cases and success stories for containers at NERSC.
Title: Status of Containers in HPC
Abstract: Containers have quickly gained traction in HPC and Data Intensive computing. Containers provides users with greater flexibility, enables sharing and reproducibly, can make workflows more portable and can even improve performance. In this talk we will review some of these benefits, the status of containers at NERSC, and trends for containers in HPC. We will also discuss some of the use cases and success stories for containers at NERSC.
- 2 participants
- 44 minutes

29 May 2020
NESRC Data Seminar Series: https://github.com/NERSC/data-seminars
Simulation-based and label-free deep learning for science
Abstract:
Precise scientific analysis in many areas of science is possible because of complex simulations that connect fundamental theories to observable quantities. These simulations have been paired with multivariate methods for many years in search of new fundamental and emergent structure in nature. Deep learning tools hold great promise to qualitatively change this paradigm by allowing for holistic analysis of data in its natural hyperdimensionality with thousands or millions of features instead of up to tens of features. These tools are not yet broadly used for all areas of data analysis because of the traditional dependence on simulations. In this talk, I will discuss how we can change this paradigm in order to exploit the new features of deep learning. In particular, I will show how neural networks can be used to (1) overcome the challenge of high-dimensional probability density modeling and (2) learn directly from (unlabeled) data to perform hypothesis tests that go beyond any existing analysis methods. The example for (1) will be full phase space unfolding (deconvolution) and the example for (2) will be anomaly detection. The talk will include a discussion of uncertainties associated with deep learning-based analyses. These ideas are starting to become a reality: the first deep learning weakly supervised anomaly detection search has recently been made public by the ATLAS Collaboration at the LHC. While my examples will primarily draw from collider physics, the techniques are more broadly applicable and I am happy to discuss extensions and applications to your science domain.
Simulation-based and label-free deep learning for science
Abstract:
Precise scientific analysis in many areas of science is possible because of complex simulations that connect fundamental theories to observable quantities. These simulations have been paired with multivariate methods for many years in search of new fundamental and emergent structure in nature. Deep learning tools hold great promise to qualitatively change this paradigm by allowing for holistic analysis of data in its natural hyperdimensionality with thousands or millions of features instead of up to tens of features. These tools are not yet broadly used for all areas of data analysis because of the traditional dependence on simulations. In this talk, I will discuss how we can change this paradigm in order to exploit the new features of deep learning. In particular, I will show how neural networks can be used to (1) overcome the challenge of high-dimensional probability density modeling and (2) learn directly from (unlabeled) data to perform hypothesis tests that go beyond any existing analysis methods. The example for (1) will be full phase space unfolding (deconvolution) and the example for (2) will be anomaly detection. The talk will include a discussion of uncertainties associated with deep learning-based analyses. These ideas are starting to become a reality: the first deep learning weakly supervised anomaly detection search has recently been made public by the ATLAS Collaboration at the LHC. While my examples will primarily draw from collider physics, the techniques are more broadly applicable and I am happy to discuss extensions and applications to your science domain.
- 2 participants
- 46 minutes
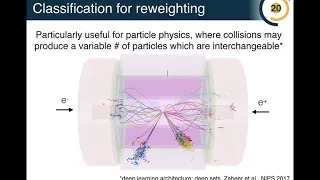
15 May 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Deep learning production capabilities at NERSC
Abstract: Deep Learning is increasingly being used for scientific problems which require large scale computing resources. High performance computing centers are adapting to accommodate these new kinds of workloads which can differ significantly from traditional HPC simulation workloads. NERSC supports and enables deep learning workflows by providing an optimized software stack and by supporting users to deploy their applications effectively and productively. In this presentation we will describe NERSC’s production capabilities for scientific deep learning applications, including details of the software stack, system performance with extensive benchmarking, and workflow solutions to enable productive science. In addition, we will discuss our outlook for the future of AI at NERSC on the upcoming Perlmutter supercomputer and beyond.
Deep learning production capabilities at NERSC
Abstract: Deep Learning is increasingly being used for scientific problems which require large scale computing resources. High performance computing centers are adapting to accommodate these new kinds of workloads which can differ significantly from traditional HPC simulation workloads. NERSC supports and enables deep learning workflows by providing an optimized software stack and by supporting users to deploy their applications effectively and productively. In this presentation we will describe NERSC’s production capabilities for scientific deep learning applications, including details of the software stack, system performance with extensive benchmarking, and workflow solutions to enable productive science. In addition, we will discuss our outlook for the future of AI at NERSC on the upcoming Perlmutter supercomputer and beyond.
- 4 participants
- 56 minutes
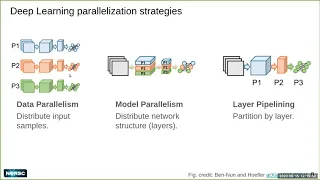
1 May 2020
NERSC Data Seminars Series: https://github.com/NERSC/data-seminars
Deep learning for PDEs, and scientific computing with JAX
Abstract: This talk will give an overview of how deep learning can be combined with traditional numerical methods to create improved methods for scientific computing. I will highlight two recent examples from my research: using deep learning to improve discretizations for solving partial differential equations [1], and using deep learning to reparameterize optimization landscapes for PDE constrained structural optimization [2]. I will also briefly introduce JAX [3], an open source library from Google for composable transformations of Python/NumPy programs, including automatic differentiation, vectorization and JIT compilation for accelerators. JAX is particularly suitable for scientific applications, including hybrid machine learning / simulation codes.
[1] Bar-Sinai*, Y., Hoyer*, S., Hickey, J. & Brenner, M. P. Learning data-driven discretizations for partial differential equations. Proceedings of the National Academy of Sciences 201814058 (2019). doi:10.1073/pnas.1814058116 [2] Hoyer, S., Sohl-Dickstein, J. & Greydanus, S. Neural reparameterization improves structural optimization. arXiv [cs.LG] (2019). https://arxiv.org/abs/1909.04240 [3] https://github.com/google/jax
Deep learning for PDEs, and scientific computing with JAX
Abstract: This talk will give an overview of how deep learning can be combined with traditional numerical methods to create improved methods for scientific computing. I will highlight two recent examples from my research: using deep learning to improve discretizations for solving partial differential equations [1], and using deep learning to reparameterize optimization landscapes for PDE constrained structural optimization [2]. I will also briefly introduce JAX [3], an open source library from Google for composable transformations of Python/NumPy programs, including automatic differentiation, vectorization and JIT compilation for accelerators. JAX is particularly suitable for scientific applications, including hybrid machine learning / simulation codes.
[1] Bar-Sinai*, Y., Hoyer*, S., Hickey, J. & Brenner, M. P. Learning data-driven discretizations for partial differential equations. Proceedings of the National Academy of Sciences 201814058 (2019). doi:10.1073/pnas.1814058116 [2] Hoyer, S., Sohl-Dickstein, J. & Greydanus, S. Neural reparameterization improves structural optimization. arXiv [cs.LG] (2019). https://arxiv.org/abs/1909.04240 [3] https://github.com/google/jax
- 9 participants
- 1:02 hours

17 Apr 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: A Data-Driven Global Weather Model Using Reservoir Computing
Abstract: Data-driven approaches to predict chaotic spatiotemporal dynamical systems have been shown to be successful for a number of high-dimensional, complex systems. One of the most important chaotic systems which impacts our lives is the atmosphere. This, naturally, leads to the question whether a purely data-driven machine learning algorithm can accurately predict the weather. In this talk, we present a prototype machine learning model that can skillfully predict the three dimensional state of the atmosphere for 3-5 days. The training of the machine learning model is computationally efficient and parallelized over thousands of computer cores. Our results suggest that machine learning has the potential to improve the prediction of atmospheric state variables most affected by parameterized processes in numerical models.
References: Arcomano et al. "A Machine-Learning-Based Global Atmospheric Forecast Model." (2020). https://www.essoar.org/doi/pdf/10.1002/essoar.10502527.1
Title: A Data-Driven Global Weather Model Using Reservoir Computing
Abstract: Data-driven approaches to predict chaotic spatiotemporal dynamical systems have been shown to be successful for a number of high-dimensional, complex systems. One of the most important chaotic systems which impacts our lives is the atmosphere. This, naturally, leads to the question whether a purely data-driven machine learning algorithm can accurately predict the weather. In this talk, we present a prototype machine learning model that can skillfully predict the three dimensional state of the atmosphere for 3-5 days. The training of the machine learning model is computationally efficient and parallelized over thousands of computer cores. Our results suggest that machine learning has the potential to improve the prediction of atmospheric state variables most affected by parameterized processes in numerical models.
References: Arcomano et al. "A Machine-Learning-Based Global Atmospheric Forecast Model." (2020). https://www.essoar.org/doi/pdf/10.1002/essoar.10502527.1
- 3 participants
- 55 minutes

14 Mar 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: ECP HDF5 - New features and applications
Abstract: HDF5 is a data model, file format, and I/O library that has become a de facto standard for HPC applications to achieve scalable I/O and for storing and managing big data from computer modeling, large physics experiments and observations. Several Exascale Computing Project (ECP) applications are currently using or planning to use HDF5 for I/O. The ExaHDF5 project team of the ECP is working on developing and productizing various features to improve the efficiency of parallel I/O to take advantage of exascale architectures. In this presentation, we will talk about these features, including Virtual Object Layer (VOL), asynchronous I/O, subfiling, Data Elevator, independent metadata updates, querying, etc. The presentation also include integration of HDF5 into ECP applications and co-design efforts, such as EQSIM and AMReX.
Title: ECP HDF5 - New features and applications
Abstract: HDF5 is a data model, file format, and I/O library that has become a de facto standard for HPC applications to achieve scalable I/O and for storing and managing big data from computer modeling, large physics experiments and observations. Several Exascale Computing Project (ECP) applications are currently using or planning to use HDF5 for I/O. The ExaHDF5 project team of the ECP is working on developing and productizing various features to improve the efficiency of parallel I/O to take advantage of exascale architectures. In this presentation, we will talk about these features, including Virtual Object Layer (VOL), asynchronous I/O, subfiling, Data Elevator, independent metadata updates, querying, etc. The presentation also include integration of HDF5 into ECP applications and co-design efforts, such as EQSIM and AMReX.
- 3 participants
- 58 minutes
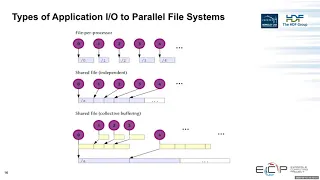
6 Mar 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: Intersections of AI/ML and Chemistry in Catalyst Design and Discovery
Abstract: Summary: Increasing computational sophistication and resources can enable a larger and more integrated role of theory in the discovery and understanding of new materials. This process has been slower to infiltrate surface science and catalysis than the field of bulk inorganic materials due to additional scientific complexity of modeling the interface. Most catalyst studies start in a data-poor regime where the material of interest is unrelated to previous to studies (new structure, composition etc) or the computational methods are incompatible with previous studies (different exchange-correlation functionals, methods, etc). Efficient methods to quickly define, schedule, and organize necessary simulations are thus important and enable the application of online design of experiments approaches. I will discuss on-going work and software development to enable data science methods in catalysis including open datasets for the community. These large datasets enable the use of graph convolutional models for surface properties and the uncertainty in these methods can be carefully calibrated. Finally, I will describe applications of our approach to ordered bimetallic alloy catalysts, with applications to several electrochemical catalyst discovery efforts including CO2 reduction, oxygen reduction, and water splitting chemistry.
Title: Intersections of AI/ML and Chemistry in Catalyst Design and Discovery
Abstract: Summary: Increasing computational sophistication and resources can enable a larger and more integrated role of theory in the discovery and understanding of new materials. This process has been slower to infiltrate surface science and catalysis than the field of bulk inorganic materials due to additional scientific complexity of modeling the interface. Most catalyst studies start in a data-poor regime where the material of interest is unrelated to previous to studies (new structure, composition etc) or the computational methods are incompatible with previous studies (different exchange-correlation functionals, methods, etc). Efficient methods to quickly define, schedule, and organize necessary simulations are thus important and enable the application of online design of experiments approaches. I will discuss on-going work and software development to enable data science methods in catalysis including open datasets for the community. These large datasets enable the use of graph convolutional models for surface properties and the uncertainty in these methods can be carefully calibrated. Finally, I will describe applications of our approach to ordered bimetallic alloy catalysts, with applications to several electrochemical catalyst discovery efforts including CO2 reduction, oxygen reduction, and water splitting chemistry.
- 2 participants
- 55 minutes

28 Feb 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: The Superfacility project: 2019 year in review
Abstract: The Superfacility Initiative was a key component of the CS Area strategic report, and described the research and engineering required to connect experimental, networking and HPC facilities to accelerate scientific discovery. The Superfacility project was created in early 2019 in response to this Initiative. The project tracks, coordinates and communicates the work being performed across the CS Area to address the needs described in the Strategic Plan. This includes close partnership with several science teams whose needs are driving our work. In this talk, we will introduce the Superfacility concept and project structure, and the project leads will present their highlight achievements in 2019, and plans for 2020.
Title: The Superfacility project: 2019 year in review
Abstract: The Superfacility Initiative was a key component of the CS Area strategic report, and described the research and engineering required to connect experimental, networking and HPC facilities to accelerate scientific discovery. The Superfacility project was created in early 2019 in response to this Initiative. The project tracks, coordinates and communicates the work being performed across the CS Area to address the needs described in the Strategic Plan. This includes close partnership with several science teams whose needs are driving our work. In this talk, we will introduce the Superfacility concept and project structure, and the project leads will present their highlight achievements in 2019, and plans for 2020.
- 14 participants
- 58 minutes
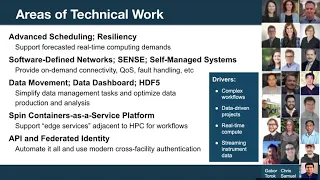
14 Feb 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: Intrinsi ccomputation and physics-based machine learning for emergent self-organization in far-from-equilibrium systems
Abstract: Coherent structures form spontaneously in far-from-equilibrium spatiotemporal systems and are found at all spatial scales in natural phenomena from laboratory hydrodynamic flows and chemical reactions to ocean and atmosphere dynamics. Phenomenologically, they appear as key components that organize macroscopicdynamical behaviors. Unlike their equilibrium and near-equilibriumc ounterparts, there is no general theory to predict what patterns and structures may emerge in far-from-equilibrium systems. Each system behaves differently; details and history matter. The complex behaviors that emerge cannot be explicitly described mathematically, nor can they be directly deduced from the governing equations (e.g. what is the mathematical expression for a hurricane, and how can you derive it from the equations of a general circulation climate model?). It is thus appealing to bring the instance-based data-driven models of machine learning to bear on the problem. Supervised learning models have been the most successful, but they require ground-truth training labels which do not exist for far-from-equilibrium structures. Unsupervised models that leverage physical principles of self-organization are required. To this end we will make connections between structural organization and intrinsic computation to motivate the use of physics-based unsupervised models called local causal states. As local models they are capable of capturing structures of arbitrary shape and size in a visually interpretable manner, due to the shared coordinate geometry between observable spacetime fields and their associated latent local causal state fields. We will show the local causal states can capture patterns in cellular automata models as generalized spacetime symmetries and coherent structures as localized deviations from these generalized symmetries. To demonstrate their applicability to real-world systems, we show the utility of the local causal states for extracting coherent structures in simulations and observations of complex fluid flows, including promising results highlighting extreme weather events in the water vapor field of the CAM5.1 climate model. These results require high-performance computing, and we will briefly describe how we were able to process almost 90TB in under 7 minutes end-to-end on 1024 Haswell nodes of Cori using a distributed implementation in Python.
Title: Intrinsi ccomputation and physics-based machine learning for emergent self-organization in far-from-equilibrium systems
Abstract: Coherent structures form spontaneously in far-from-equilibrium spatiotemporal systems and are found at all spatial scales in natural phenomena from laboratory hydrodynamic flows and chemical reactions to ocean and atmosphere dynamics. Phenomenologically, they appear as key components that organize macroscopicdynamical behaviors. Unlike their equilibrium and near-equilibriumc ounterparts, there is no general theory to predict what patterns and structures may emerge in far-from-equilibrium systems. Each system behaves differently; details and history matter. The complex behaviors that emerge cannot be explicitly described mathematically, nor can they be directly deduced from the governing equations (e.g. what is the mathematical expression for a hurricane, and how can you derive it from the equations of a general circulation climate model?). It is thus appealing to bring the instance-based data-driven models of machine learning to bear on the problem. Supervised learning models have been the most successful, but they require ground-truth training labels which do not exist for far-from-equilibrium structures. Unsupervised models that leverage physical principles of self-organization are required. To this end we will make connections between structural organization and intrinsic computation to motivate the use of physics-based unsupervised models called local causal states. As local models they are capable of capturing structures of arbitrary shape and size in a visually interpretable manner, due to the shared coordinate geometry between observable spacetime fields and their associated latent local causal state fields. We will show the local causal states can capture patterns in cellular automata models as generalized spacetime symmetries and coherent structures as localized deviations from these generalized symmetries. To demonstrate their applicability to real-world systems, we show the utility of the local causal states for extracting coherent structures in simulations and observations of complex fluid flows, including promising results highlighting extreme weather events in the water vapor field of the CAM5.1 climate model. These results require high-performance computing, and we will briefly describe how we were able to process almost 90TB in under 7 minutes end-to-end on 1024 Haswell nodes of Cori using a distributed implementation in Python.
- 5 participants
- 1:01 hours

7 Feb 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Title: Time-series Analysis of ESnet Network Traffic: Statistical and Deep Learning models
Abstract: Predicting network traffic can provide information on large data movement and details on how users interact with the network. As the area of ML matures, we are investigating building predictive models that can provide suitable predictions into the future on how traffic will behave on the network links. The goals of this prediction is to investigate anomaly detection and understanding congestion patterns on the network to help manage them more efficiently. In this talk, we will present our results on time series analysis and also show we plan to deploy these models to perform real-time ML predictions.
Title: Time-series Analysis of ESnet Network Traffic: Statistical and Deep Learning models
Abstract: Predicting network traffic can provide information on large data movement and details on how users interact with the network. As the area of ML matures, we are investigating building predictive models that can provide suitable predictions into the future on how traffic will behave on the network links. The goals of this prediction is to investigate anomaly detection and understanding congestion patterns on the network to help manage them more efficiently. In this talk, we will present our results on time series analysis and also show we plan to deploy these models to perform real-time ML predictions.
- 3 participants
- 47 minutes
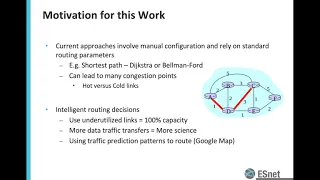
31 Jan 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: In a not-too-distant future, our devices will not just be networked, but share huge volumes of data required for instantaneous and vital decisions. Technologies such as self-driving cars, smart cities and homes, and augmented reality all depend on handling massive quantities of data quickly and reliably. Understanding the characteristics of workloads such as these will be critical to reducing storage costs and making the cloud of tomorrow accessible and equitable for all. All storage systems exist to serve some group of users and applications. Tuning a storage system is a delicate balance between reliability, availability, security, performance spread over the users, or workloads, that the system serves. For cloud storage, elasticity is a crucial factor, but misconfiguration in reactive storage tuning has been cited to be a leading cause of production failures. Transferring and transforming provisioning insights to match dynamic workloads will break ground for system improvements spanning from the power footprint to cache management to selecting an appropriate reliability configuration. This talk covers the current state of workload-aware design along with our current work to improve storage provisioning and trace characterization.
Abstract: In a not-too-distant future, our devices will not just be networked, but share huge volumes of data required for instantaneous and vital decisions. Technologies such as self-driving cars, smart cities and homes, and augmented reality all depend on handling massive quantities of data quickly and reliably. Understanding the characteristics of workloads such as these will be critical to reducing storage costs and making the cloud of tomorrow accessible and equitable for all. All storage systems exist to serve some group of users and applications. Tuning a storage system is a delicate balance between reliability, availability, security, performance spread over the users, or workloads, that the system serves. For cloud storage, elasticity is a crucial factor, but misconfiguration in reactive storage tuning has been cited to be a leading cause of production failures. Transferring and transforming provisioning insights to match dynamic workloads will break ground for system improvements spanning from the power footprint to cache management to selecting an appropriate reliability configuration. This talk covers the current state of workload-aware design along with our current work to improve storage provisioning and trace characterization.
- 5 participants
- 41 minutes

10 Jan 2020
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: For bridging the ever-widening performance gap between computation and storage systems, new tiers are introduced to the already deep storage hierarchy. I/O middleware, such as HDF5, has been developed and used for decades to provide applications relatively simple APIs and hide all the low-level details of the underlying I/O and storage systems. As the systems scale out, some of the old designs such as the collective metadata updating mechanism that fits smaller scales start to show the performance penalty. For addressing this problem, we have built a new HDF5-based I/O middleware prototype that enables independent metadata updating. In this presentation, I'll talk about the challenges, the design and implementation of the solutions, and the lessons we learned from building the system.
Abstract: For bridging the ever-widening performance gap between computation and storage systems, new tiers are introduced to the already deep storage hierarchy. I/O middleware, such as HDF5, has been developed and used for decades to provide applications relatively simple APIs and hide all the low-level details of the underlying I/O and storage systems. As the systems scale out, some of the old designs such as the collective metadata updating mechanism that fits smaller scales start to show the performance penalty. For addressing this problem, we have built a new HDF5-based I/O middleware prototype that enables independent metadata updating. In this presentation, I'll talk about the challenges, the design and implementation of the solutions, and the lessons we learned from building the system.
- 1 participant
- 36 minutes

6 Dec 2019
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: The majority of all materials data is currently scattered across the text, tables, and figures of millions of scientific publications. In my talk, I will present the work of our team at Lawrence Berkeley National Laboratory on the use of natural language processing (NLP) and machine learning techniques to extract and discover materials knowledge through textual analysis of the abstracts of several million journal articles. With this data we are exploring new avenues for materials discovery and design, such as how functional materials like thermoelectrics can be identified by using only unsupervised word embeddings for materials. To date, we have used advanced techniques for named entity recognition to extract more than 100 million mentions of materials, structures, properties, applications, synthesis methods, and characterization techniques from our database of over 3 million materials science abstracts. With this data, we are developing machine learning tools for autonomously building databases of materials-properties data extracted from unstructured materials text.
Abstract: The majority of all materials data is currently scattered across the text, tables, and figures of millions of scientific publications. In my talk, I will present the work of our team at Lawrence Berkeley National Laboratory on the use of natural language processing (NLP) and machine learning techniques to extract and discover materials knowledge through textual analysis of the abstracts of several million journal articles. With this data we are exploring new avenues for materials discovery and design, such as how functional materials like thermoelectrics can be identified by using only unsupervised word embeddings for materials. To date, we have used advanced techniques for named entity recognition to extract more than 100 million mentions of materials, structures, properties, applications, synthesis methods, and characterization techniques from our database of over 3 million materials science abstracts. With this data, we are developing machine learning tools for autonomously building databases of materials-properties data extracted from unstructured materials text.
- 8 participants
- 1:03 hours

15 Nov 2019
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: The upcoming generation of cosmological surveys such as DESI or LSST will probe the Universe on an unprecedented scale and with unparalleled precision, to answer fundamental questions about Dark Matter and Dark Energy. However, optimally extracting cosmological information from this massive amount of data remains a major challenge, and constitutes a very active research area. Having access to differentiable forward simulations of these surveys paves the way to novel and extremely powerful gradient-based inference techniques. For instance, we have demonstrated potential for over a 50% information gain in constraining Dark Energy using the upcoming DESI galaxy survey. In this talk, we will present FlowPM, the first differentiable cosmological N-body simulation code implemented in TensorFlow for seamless integration with deep learning components and gradient-based inference techniques. After showcasing a few examples of the benefits of such a tool, we will discuss our efforts to scale these simulations to large supercomputers using the Mesh TensorFlow framework.
Abstract: The upcoming generation of cosmological surveys such as DESI or LSST will probe the Universe on an unprecedented scale and with unparalleled precision, to answer fundamental questions about Dark Matter and Dark Energy. However, optimally extracting cosmological information from this massive amount of data remains a major challenge, and constitutes a very active research area. Having access to differentiable forward simulations of these surveys paves the way to novel and extremely powerful gradient-based inference techniques. For instance, we have demonstrated potential for over a 50% information gain in constraining Dark Energy using the upcoming DESI galaxy survey. In this talk, we will present FlowPM, the first differentiable cosmological N-body simulation code implemented in TensorFlow for seamless integration with deep learning components and gradient-based inference techniques. After showcasing a few examples of the benefits of such a tool, we will discuss our efforts to scale these simulations to large supercomputers using the Mesh TensorFlow framework.
- 9 participants
- 54 minutes
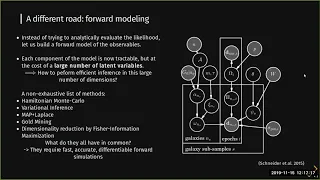
25 Oct 2019
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: This talk looks at HPC from the perspective of data acquisition systems (DAQs) at experimental and observational facilities. A systems view of DOE-scale instruments producing data increasingly includes opportunities and/or needs to modulate computational intensity upwards. Experimental facilities that "plug into HPC" for this purpose often include DAQ hardware and systems for which HPC can be a challenge. This seminar reviews related issues from recent data science engagements at NERSC.
Abstract: This talk looks at HPC from the perspective of data acquisition systems (DAQs) at experimental and observational facilities. A systems view of DOE-scale instruments producing data increasingly includes opportunities and/or needs to modulate computational intensity upwards. Experimental facilities that "plug into HPC" for this purpose often include DAQ hardware and systems for which HPC can be a challenge. This seminar reviews related issues from recent data science engagements at NERSC.
- 1 participant
- 42 minutes

12 Apr 2019
NERSC Data Seminars: https://github.com/NERSC/data-seminars
Abstract: Most contemporary machine learning experiments are performed treating the underlying algorithms as a black box. This approach, however, fails when trying to budget large scale experiments or when machine learning is used as part of scientific discovery and uncertainty needs to be quantifiable. Using the example of Neural Networks, this talk presents a line of research enabling the measurement and prediction of the capabilities of machine learners, allowing a more rigorous experimental design process for machine learning experiments. The main idea is taking the viewpoint that memorization is worst-case generalization. My presentation is made of three parts. Based on MacKay's information theoretic model of supervised machine learning~\cite{mackay2003}, I first derive four easily applicable engineering principles to analytically determine the upper-limit memory capacity of neural network architectures. This allows the comparison of the efficiency of different architectures independent of a task. Second, I introduce and experimentally validate a heuristic method to estimate the neural network memory capacity requirement for a given learning task. Third, I outline a generalization process that successively reduces capacity starting at the memorization estimate. I conclude with a discussion on the consequences of sizing a machine learner wrongly, which includes a potentially increased number of adversarial examples.
Abstract: Most contemporary machine learning experiments are performed treating the underlying algorithms as a black box. This approach, however, fails when trying to budget large scale experiments or when machine learning is used as part of scientific discovery and uncertainty needs to be quantifiable. Using the example of Neural Networks, this talk presents a line of research enabling the measurement and prediction of the capabilities of machine learners, allowing a more rigorous experimental design process for machine learning experiments. The main idea is taking the viewpoint that memorization is worst-case generalization. My presentation is made of three parts. Based on MacKay's information theoretic model of supervised machine learning~\cite{mackay2003}, I first derive four easily applicable engineering principles to analytically determine the upper-limit memory capacity of neural network architectures. This allows the comparison of the efficiency of different architectures independent of a task. Second, I introduce and experimentally validate a heuristic method to estimate the neural network memory capacity requirement for a given learning task. Third, I outline a generalization process that successively reduces capacity starting at the memorization estimate. I conclude with a discussion on the consequences of sizing a machine learner wrongly, which includes a potentially increased number of adversarial examples.
- 6 participants
- 58 minutes
